Регулярная неоднозначность
Термин «лексическая единица» может вызвать ошибочное представление, будто каждая лексическая единица обязательно должна фиксироваться в словаре данного языка. Это вовсе не так.
Во всех языках, по-видимому, между лексическими единицами существуют отношения импликации, то есть из существования одной лексической единицы может следовать существование некоторой другой лексической единицы, которая тем самым может и не включаться в словарь. Например, Лестер Райс обратил мое внимание на следующий факт: во многих языках прилагательные, обозначающие температуру (теплый, холодный и т. п.), могут использоваться также для обозначения температурных ощущений, обеспечиваемых ношением той или иной одежды. Так, английская фраза(13) This coat is warm. ‘Это пальто теплое.’
неоднозначна: она значит либо что само пальто имеет достаточно высокую температуру, либо что оно обеспечивает тому, кто его носит, ощущение достаточно высокой температуры. Точно такая же неоднозначность присуща и венгерской фразе
(14) Ez a kabat meleg. ‘Это пальто теплое.’
Поэтому я предлагаю считать, что, хотя в английском языке имеются две лексические единицы warm, однако в словарь надо помещать только одну из них, поскольку вторая может быть получена из первой в соответствии со следующим правилом: для всякого прилагательного, обозначающего некоторую температуру, имеется другое прилагательное, относящееся к одежде и означающее ‘каузирующий ощу* щение, которое соответствует температуре, обозначенной первым прилагательным’*. Заметим, что, хотя в толкование второго прилагательного входит элемент ‘каузация’, оно не может быть получено из первого посредством обычной каузативной трансформации, во-первых, потому, что эта трансформация не обеспечивает появления сочетаемостного ограничения «относится только к одежде» а, и, во-вторых, потому, что в результате каузативной трансформации получаются предложения, в которых глубинное подлежащее «исходной» лексической единицы выступает как дополнение к «производной» единице (так, John opened the door.
‘Джон открыл дверь. ’— это каузативное предложение, включающее The door opened. ‘Дверь открылась.’), тогда как производное прилагательное warm (относящееся к одежде) не допускает- присоединения именной группы, обозначающей обогреваемое лицо или вещь.Приведем еще один пример того, как наличие некоторой лексической единицы в языке может быть предсказано по наличию в нем другой лексической единицы: мы имеем в виду процесс, который Дж. Лакофф назвал «овеществлением» (reification).
Сравним смысловые различия между вхождениями слова score ‘партитура’ в (15) и (16):
(15) John has memorized the score of the Ninth Symphony. ‘Джон выучил наизусть партитуру 9-й симфонии.’
(16) The score of the Ninth Symphony is lying on the piano.
‘Партитура 9-й симфонии лежит на рояле.’
Аналогично обстоит дело с John’s dissertation ‘диссертация Джона’ в (17) и (18):
(17) John’s dissertation deals with premarital sex among the Incas.
‘Диссертация Джона посвящена добрачной половой жизни у инков.’
(18) John’s dissertation weighs five pounds.
‘Диссертация Джона весит 5 фунтов.’
В (15) и (17) речь идет соответственно об эстетическом и информационном объекте, а в (16) и (18) — об их физических воплощениях. Заметим в связи с этим, что (19) — вполне нормальная фраза, а (20) — нет:
(19) I am halfway finished with writing my dissertation, which deals with premarital sex among the Incas. ‘Я наполовину уже написал свою диссертацию, которая посвящена добрачной половой жизни у инков.’
(20) *1 am halfway finished with writing my dissertation, which weighs five pounds.
‘Я наполовину уже написал свою диссертацию, которая весит 5 фунтов.’
Еще один случай овеществления указан в W і е г z b і с- k а, 1967а; это различие между значениями собственного имени в (21) и (22):
(21) John thinks that the world is flat,
‘Джон думает, что земля плоская.’
(22) John weighs 200 pounds. ‘Джон весит 200 фунтов/
В (21) John — некое лицо, в (22) — тело этого лица.
Данное различие иллюстрируется и известным примером Лакоффа (L а к о f f, 1968):
(23) * James Bond broke the window with himself. ‘Джеймз Бонд разбил окно собой.’,
из которого ясно, что словосочетание James Bond, обозначающее лицо, и словосочетание James Bond, обозначающее тело этого лица, не являются идентичными с точки зрения правил введения возвратных местоимений в английском языке [95]. Здесь также мы видим, что каждая лексическая единица, обозначающая человека, имплицирует существование «физически» идентичной лексической единицы, обозначающей тело этого человека; поэтому в словарь достаточно включать только лексические единицы первого типа. Рассматривая проблему метафоры, У. Вейнрейх (Weinreich; 1966а, разд. 3,5) предлагает правила (=construal rules; см. наст, сб., с. 147—162), опирающиеся на аналогичные соображения. Это правила, которые «создают» новую лексическую единицу, изменяя семантическое представление некоторой уже имеющейся в словаре лексической единицы таким образом, чтобы оно стало совместимым с семантическим представлением фразы, в которой исходная лексическая единица оказалась бы аномальной. Впрочем, правила Вейнрейха, создающие только «аномальные» (в том или ином отношении) лексические единицы для использования их исключительно в специальных, поэтических целях, необходимо строго отграничивать от правил получения производных лексических единиц типа warm (обеспечивающий достаточную температуру), dissertation (материальный предмет) и John (тело Джона); эти последние правила создают лексические единицы, ничуть не более аномальные, чем исходные.
Сочетаемостные ограничения
Обратимся теперь к сочетаемостным ограничениям (СО). В большинстве работ по трансформационной грамматике они относятся к базовому компоненту грамматики. Так, в соответствии cChomsky, 1965, базовый компонент включает правила, приписывающие каждому субстантивному узлу «внутренне присущие» ему признаки, например: 1+ одуш(евленное)] или (— одуш], 1+ человек] или [— человек]; кроме того, имеются правила, приписывающие глагольному узлу признаки [одушевленное подлежащее]; [подлежащее не-человек1 и т.
п.— в зависимости от того, какие признаки приписаны группе подлежащего, прямого дополнения и другим составляющим; наконец, в каждый узел, снабженный набором подобных признаков, подставляется любая лексическая единица, такая, что ее собственные признаки не противоречат признакам этого узла. Подчеркнем, что Хомский понимает СО как ограничение на пару лексических единиц, например: . Иначе трактуются СО в Katz — Fodor, 1963: здесь соблюдение/нарушение любых СО определяется не в базовом, а в семантическом компоненте грамматики, и СО считается ограничением не на пару лексических единиц, а на пару Слексическая единица, целая составляющая>, то есть, например, Сглагол, группа подлежащего>. Точнее, СО к глаголу указывает, какими свойствами должно обладать семантическое представление группы подлежащего; проверка выполнения такого СО заключается в построении семантического представления для группы подлежащего и установлении наличия/отсутствия в этом представлении требуемого свойства. Не ясно, считают ли Катц и Фодор, что подобные «семантические СО» должны использоваться вместо «синтаксических СО», предложенных в С h о т- s к у, 1965, или же наряду с этими последними.Вообще вопросу о том, какие СО необходимы — только синтаксические СО, или только семантические СО, или же и те и другие,— уделялось до сих пор удивительно мало внимания. Н. Хомский, бегло упомянув об этом вопросе (Chomsky, 1965, р. 153—154), отказывается от его серьезного рассмотрения, как будто дело полностью сводится к выбору формы записи. В действительности, однако, разные ответы на этот вопрос влекут существенно различные следствия на уровне описания фактов. Мне хотелось бы привести аргумент в пользу той точки зрения, что сочетаемость вполне адекватно описывается в терминах семантических СО (типа предложенных в Katz — Fodor, 1963) и что для синтаксических СО Хомского, а также для использования громоздкого аппарата «сложных символов» (предполагаемых синтаксическими СО) достаточных оснований нет.
Рассмотрим сначала следующий вопрос: пусть имеется глагол или прилагательное, снабженное некоторым СО; спрашивается, к чему именно относится это СО — ко всей именной группе, выступающей в роли подлежащего, дополнения, определяемого и т.
п., или только к вершине этой группы? Нетрудно привести примеры, подтверждающие истинность первого ответа. Так, во фразе(25) [97]Му buxom neighbor is the father of two.
‘Моя полногрудая соседка — отец двоих детей.’* нарушено то же самое СО, что и в (26):
(26) *Му sister is the father of two.
‘Моя сестра — отец двоих детей.’
Это нарушение связано в (25) со всей группой подлежащего в целом, но вовсе не с ее вершиной: фраза
(27) My neighbor is the father of two.
*Мой сосед — отец двоих детей.’
не нарушает никаких СО.
Кроме того, неизвестны случаи, когда глагол, при котором некоторая лексическая единица в роли вершины группы подлежащего невозможна, допускал бы в этой роли именную группу, где смысл данной лексической единицы был бы распределен между определяемым и определением (например, не существует глагола, при котором в роли подлежащего была бы допустима группа an unmarried man ‘неженатый мужчина’, но не было бы допустимо существительное a bachelor ‘холостяк’)[98].
Из сказанного следует, что, если мы хотим знать, удовлетворяет ли некоторая составляющая данному СО, мы должны рассматривать семантическое представление этой составляющей в целом, а не представление одной лексической единицы — ее вершины. Зададимся теперь вопросом, какова в точности та информация об этой составляющей, которая необходима для определения ее соответствия некоторому СО. Я утверждаю, во-первых, что любая информация, фигурирующая в семантическом представлении какой- либо единицы, может фигурировать и в соответствующих СО и, во-вторых, что никакой другой информации в СО не требуется. В доказательство первого утверждения достаточно сослаться на то, что на каждой странице любого большого словаря можно найти слова, которые предполагают невероятно специфичные СО, опирающиеся на практически неограниченное множество семантических свойств. Например, глагол diagonalize ‘приводить к диагональному виду* требует в качестве прямого дополнения именную группу, обозначающую матрицу (в математическом смысле), глагол devein ‘вынимать внутренности’—дополнения, обозначающего какой-либо из видов креветок, а прилагательное benign ‘доброкачественный’ требует определяемого, обозначающего ‘опухоль’.
Что же касается моего второго утверждения (о том, что СО связаны исключительно с семантической информацией),
то нетрудно показать следующее: различные несемантические признаки, обычно приписываемые существительным, например собственное/нарицательное, грамматический род, грамматическое число и т. д., не играют с точки зрения СО никакой роли. Во всех примерах, которые приводят в качестве довода против этого положения, ограничения на сочетаемость основываются в конечном счете на семантике. Так, может показаться, будто глагол name ‘называть’ связан с СО, ссылающимся на признак [собственное]:
(28) They named their son John.
‘Они назвали своего сына Джоном.’, но не
(29) *They named their son that boy.
‘Они назвали своего сына этим мальчиком.*
Однако существуют абсолютно нормальные фразы, где в качестве соответствующего дополнения глагола name выступает вовсе не имя собственное:
(30) They named their son something outlandish.
букв. ‘Они назвали своего сына чем-то диковинным.*
Ясно, что СО для глагола name должно требовать, чтобы его второе дополнение обозначало то, что может быть именем; при этом неважно, будет вершина этого дополнения именем собственным или нет.
Точно так же обстоит дело с грамматическим числом. На первый взгляд глаголы типа count ‘считать, пересчитывать’ требуют дополнения во множественном числе:
(31) I counted the boys. ‘Я пересчитал мальчиков.’, но не
(32) *1 counted the boy. ‘Я пересчитал мальчика.’
Тем не менее возможны фразы типа (33):
(33) I counted the crowd. ‘Я пересчитал толпу.’,
где count имеет дополнение в единственном числе. Поэтому СО к глаголу count должно требовать дополнения, называющего совокупность, а вовсе не просто дополнения во множественном числе. Аналогичным образом в английском языке нет глаголов, которые допускали бы в качестве подлежащих только те именные группы, которые могут заменяться местоимением she, то есть обозначением существ женского пола, кораблей и стран *.
Все сказанное и заставляет полагать, что все СО следует формулировать исключительно в терминах семантических свойств и что для проверки соблюдения того или иного СО требуется обращаться только к семантическому представлению интересующей нас составляющей и ни к чему больше. Тогда, если в базовый компонент грамматики вводится специальный аппарат отсеивания структур, нарушающих те или иные СО, этот аппарат будет лишь дублировать то, что и без него выполняется семантическими проекционными правилами. Поэтому СО необходимо устранить из базового компонента, каковой должен быть устройством, порождающим множество глубинных структур, безотносительно к тому, нарушают эти структуры какие-либо СО или нет.
Прежде чем завершить обсуждение СО, я хотел бы коснуться одного типа случаев, которые могут показаться аргументом против развиваемой здесь точки зрения на СО. В таких языках, как японский и корейский, некоторые лексемы, выступающие во фразах различных уровней вежливости, характеризуются сочетаемостными ограничениями, которые на первый взгляд представляются связанными с не-семантическими признаками лексических единиц, а не с семантическими признаками более крупных составляющих. Например, японские глаголы aru и gozaru оба значат ‘иметься, быть у’, но второй употребляется только в ситуациях, требующих особо почтительного стиля высказываний. В таких ситуациях должны употребляться и местоимения соответствующего стиля, поэтому
(34) Watakusi-wa zidoosya-ga gozaimasu.
‘У-меня автомобиль есть.’ [watakusi ‘я’ — место- имение почтительного стиля] — совершенно правильная фраза.
(35) Ore-wa zidoosya-ga aru.
‘У-меня автомобиль есть.’—
тоже правильная фраза, однако допустимая только в ситуации, где возможен в высшей степени разговорный, неформальный стиль общения [ore ‘я’ — местоимение разговорного стиля].
Находиться одновременно в одном предложении местоимение ore и глагол gozaru не могут:
(36) *Ore-wa zidoosya-ga gozaimasu.
Заметим, что подобные ограничения на совместную встречаемость существенно отличаются в целом ряде отношений от того, что обычно понимают под «сочетаемостными ограничениями». Во-первых, по-видимому, нет непроизвольного способа решить, который из двух рассматриваемых элементов определяет выбор другого. Во-вторых, ограничение здесь накладывается не на пару конкретных составляющих, скажем на глагол и его дополнение, а глобально на все высказывание: наличие почтительного глагола типа gozaru исключает появление разговорных и просторечных местоимений типа ore, boku или kimi где бы то ни было в данном предложении и вообще во всем тексте. В-третьих, все СО, обсуждавшиеся до сих пор, не зависят от того, где именно фигурируют соответствующие составляющие — в главном или в придаточном предложении; в отличие от них ограничения на совместную встречаемость, относящиеся к уровням вежливости, применяются по-разному в независимых и придаточных предложениях. Например, морфема -mas — показатель вежливости — присоединяется к глаголам только в независимых предложениях; в придаточных она не употребляется, независимо от стиля речи, то есть от того, какие местоимения фигурируют в этих придаточных К Отсюда следует, что данное явление имеет иную формальную природу, нежели ограничения, описываемые очерченной выше теорией семантических СО или теорией синтаксических СО, выдвинутой Н. Хомским (Chomsky, 1965). Я склонен полагать, что выбор и глаголов и местоимений зависит здесь от признаков, приписываемых всему тексту в целом, а не отдельным лексическим единицам: в частности, морфема вежливости -mas присоединяется специальным правилом к подходящему глаголу, когда подобные признаки имеют место.
Если принять изложенную точку зрения на СО, то дискуссия по проблемам «утоньшения» синтаксической классификации, которая ведется уже довольно давно, оказывается явно беспредметной. Словарная статья каждой лексической единицы должна содержать всю семантическую информацию, необходимую для исчерпывающего описания значения этой единицы; кроме того, в ней должны быть указаны и все трансформации, неприменимые к данной единице. Сверх же этого не требуется ничего.
Теперь я коснусь вопроса о так называемых референ- ционных индексах. Хомский указывает (Chomsky, 1965, р. 145), что трансформации, предполагающие идентичность двух именных групп, требуют не только физической тождественности самих этих групп, но и тождественности их денотатов, или референтов (referents). Так, во фразе
(37) A man killed a man. ‘Человек убил человека’, говорящий имеет в виду двух разных людей, а во фразе
(38) A man killed himself. ‘Человек убил себя.*
— одного и того же человека.
Хомский предлагает учесть это обстоятельство следующим образом: базовый компонент грамматики должен приписывать каждой именной группе[99] некий «индекс», обозначающий референт-денотат этой группы; тогда идентичность составляющих должна пониматься как идентичность всего, включая индексы. Так, глубинные структуры фраз
(37) и (38) различаются только тем, что оба вхождения именной группы a man [100] имеют в (37) разные индексы, а в (38) — одинаковые:
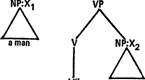
kill a man
A man killed a man
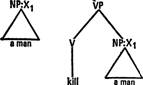
к II a man
A man killed himself
(Глагольное время в структурах не показано.)
Поскольку (37) и (38) различаются не только синтаксически, но и по смыслу, различие в индексах должно отражаться не только в синтаксических, но и в семантических представлениях фраз (37) и (38). В этой связи кажется целесообразным, чтобы семантическое представление фразы состояло не просто из признаков в смысле Катца — Фодора (Katz — Fodor, 1963), а из предикатов (в логическом смысле термина) и референционных индексов. Тогда основное значение слова man ‘мужчина’ будет представляться не набором признаков {человек, мужской пол, взрослый}, а выражением
‘человек (х) Д мужской пол (я) Д взрослый (х)’, где х — переменная. Проекционное правило, строящее семантическое представление для именной группы, содержащей слово man, будет подставлять вместо переменной х референ- ционный индекс этой группы. Подобное правило формализует такое представление об именных группах типа that man ‘тот мужчина’, в соответствии с которым свойства ‘быть человеком’, ‘быть мужского пола’ и ‘быть взрослым’ и т. п. не просто упоминаются, а предицируются относительно индивидуума, обозначаемого данной именной группой.
Прежде чем двинуться дальше, необходимо дать некоторые разъяснения относительно статуса референционных
нимает меня здесь, не зависит от того, как представляются артикли в глубинной структуре. Поэтому я буду писать просто a man, имея в виду именную группу, которая может быть реализована на поверхности как a man, и не вдаваясь в сложный вопрос, должен ли артикль присутствовать в данном случае в глубинной структуре.
Индексов и содержания термина «обозначать» (=англ, refer). В настоящей статье термин «обозначать» используется применительно к предполагаемому говорящим референту именной группы, а не к ее реальному референту; иначе говоря, референционные индексы соответствуют мыслительной картине мира, складывающейся в мозгу говорящего [101], а не реальным вещам в реальном мире. Такой подход к индексам необходим, если семантическая теория должна описывать и высказывания о воображаемых объектах, а также высказывания, отражающие ошибочные представления о фактах. С точки зрения лингвистики совершенно не важно, истинно ли мнение говорящего относительно того, о чем он говорит; так, лингвисту вовсе не обязательно знать, существуют ли ангелы-хранители и небеса, для того, чтобы приписать фразе
(39) My guardian angel is helping me to get to heaven. ‘Мой ангел-хранитель помогает мне попасть на небеса.’
соответствующее семантическое представление. При таком понимании выражения «предполагаемый (говорящим) референт» можно говорить, что индекс не просто представляет референт, но прямо является предполагаемым референтом; в мышлении говорящего обязательно должны присутствовать определенные единицы, которые он (правильно или ошибочно) соотносит с индивидуальными сущностями реального мира; именно эти единицы обозначаются термином «предполагаемый референт» и выступают в качестве референционных индексов в семантическом представлении тех фраз, которые произносит говорящий. Отсюда следует, в частности, что когда говорящий узнает новое собственное имя, то усваиваемая им семантическая информация является индексом, то есть мыслительной единицей, соответствующей тому реальному индивидууму, который носит данное имя. Усвоение собственных имен — это, по-видимому, явление того же порядка, что и усвоение большого количества неязыковой информации: когда говорящий видит кого-либо в первый раз, он добавляет к своему концептуальному репертуару новую единицу, а к своему запасу сведений и мне-
ний — набор возможных утверждений об этой единице, соответствующий тем фактам относительно нового знакомого, которые говорящий наблюдал в действительности или якобы наблюдал; узнав чье-либо имя, говорящий просто добавил к своим познаниям о данном лице еще один факт. Таким образом, референционные индексы — это неязыковые единицы, используемые наряду с языковыми единицами в представлениях высказываний.
Поскольку в английском языке многие собственные имена даются и мальчикам и девочкам и вообще любое английское имя может в принципе принадлежать не только человеку любого пола, но даже лошади или кораблю, то фраза
(40) Gwendolyn hurt himself. ‘Гвендолин ушибся.’
сама по себе не должна считаться аномальной *, хотя ее использование по отношению к любому из лиц, реально носящих имя Гвендолин, может казаться странным; однако использование фразы (40) столь же странно, сколь странно употребление применительно к женщине абсолютно правильной фразы My neighbor hurt himself. ‘Мой сосед ушибся.’
В японском языке мы встречаемся с несколько иной ситуацией. Там большинство имен может быть дано либо только мальчику, либо только девочке; более того, многие имена могут быть даны только первому сыну, только второму сыну и т. п. [102] Поэтому в японском в отличие от английского языка следует приписывать личным именам семантические представления, включающие такие компоненты, как ‘мужской пол’ и ‘перворожденный’ (=‘первенец’).
Референционные индексы и связанная с ними информация играют определенную роль при выборе местоименных форм. В английском языке выбор между he, she и it или между who и which определяется общими сведениями о референте замещаемой именной группы, а не конкретной лексемой, выступающей в качестве ее вершины. Ср. фразы
(41) - (43):
(41) Fafnir, who plays third base on the Little League team, is a fine boy.
‘Фафнир, который играет на третьей линии в команде Малой лиги, хороший парень.’
(42) They called their son Fafnir, which is a ridiculous name. букв. ‘Они назвали своего сына Фафниром, что является смешным именем.’, но не
(43) *They called their son Fafnir, who is a ridiculous name.
Различие в выборе относительных местоимений связано с различиями референционных индексов при соответствующих именных группах: в (41) именная группа Fafnir обозначает человека, а в (42) и (43) — имя. Аналогично, в
(44) My neighbor hurt himself. ‘Мой сосед ушибся/
и
(45) My neighbor hurt herself. Букв. ‘Мой сосед ушиблась/
возвратное местоимение выбирается по-разному, в зависимости от того, известен ли говорящему пол соседа, о котором идет речь.
Иное описание фраз (44) — (45) предложено Хомским (см. Chomsky, 1965). В соответствии с трактовкой Хомского базовый компонент грамматики приписывает каждому существительному полный набор признаков, фигурирующих в синтаксических и морфологических правилах (в частности, в правилах выбора местоимений). Тогда глубинные структуры фраз (44) и (45) будут различаться за счет того, что существительное neighbor будет иметь в одной структуре признак [+ мужской пол], а в другой — [— мужской пол]. Однако такое решение неубедительно, поскольку оно требует признать фразу типа
(46) My neighbor is tall.
‘Мой сосед/соседка высок/высока (ростом)/
неоднозначной: ведь ей отвечают две разные глубинные структуры (в одной neighbor имеет признак [+ мужской пол], в другой — [— мужской пол]). Более того, трансформация, строящая фразы типа
(47) The neighbors are respectively male and female, букв. ‘Соседи являются соответственно мужчиной и женщиной/,
должна будет игнорировать признаки [+ мужской пол] и [—мужской пол], приписанные двум вхождениям существительного neighbor в глубинной структуре (47'), к которой применяется эта трансформация:

Учитывая эти недостатки единственного известного мне альтернативного описания фраз типа (44) — (45), я прихожу к выводу, что различие между (44) и (45) отвечает не различию в их глубинных структурах, а различию ситуаций, соответствующих разным употреблениям одной фразы с одной и той же глубинной структурой. Вот еще один возможный довод в пользу такого решения. Фраза
(48) My neighbor is a woman and has suffered an injury. ‘Мой сосед — женщина, и она получила телесное повреждение.’
должна быть признана синонимичной с (45) А, то есть перифразой для (45), если в глубинной структуре фразы (45) neighbor имеет признак [— мужской пол]. Однако это противоречит интуитивному представлению о перифразах. Обе фразы — и (45) и (48) — передают информацию о том, что некий индивидуум, называемый my neighbor, получил телесное повреждение; однако именно фраза (48), но не
(45) будет выбрана говорящим, если он хочет сообщить, что этот индивидуум — женщина. Фразу (45) употребят тогда, когда нужно просто сообщить, что данное лицо получило телесное повреждение, причем можно предполагать, что слушающему многое об этом лице известно заранее, в частности то, что это женщина. Информация в (45) и (48) передается по-разиому; эту разницу можно выразить в терминах «смысл» (meaning) и «пресуппозиция» (presupposition): информация о том, что данное лицо получило телесное повреждение, входит в смысл как фразы (45), так и фразы (48), однако информация о том, что это лицо — женщина, входит в смысл только фразы (48); во фразе (45) эта информация относится к пресуппозициям.
В действительности выбор местоимения-заменителя в английском языке не полностью определяется пресуппозициями. В самом деле, такой грамматический признак местоимения, как число, зависит не только от информации о референте замещаемой группы. Благодаря наличию plurala tantum одна и та же вещь может быть обозначена именной группой и в единственном, и во множественном числе; местоимение-заменитель должно иметь то же грамматическое число, что и выбранная именная группа:
(49) John gave me the scissors; I am using them now. ‘Джон дал мне ножницы; я ими сейчас пользуюсь.1,
но не
(50) *John gave me the scissors; I am using it now. *‘Джон дал мне ножницы; я им сейчас пользуюсь.’
(51) John gave me the two-bladed cutting instrument; I am using it now.
‘Джон дал мне режущий инструмент с двумя лезвиями; я им сейчас пользуюсь.’,
но не
(52) *John gave me the two-bladed cutting instrument; I am using them now.
*‘Джон дал мне режущий инструмент с двумя лезвиями; я ими [=инструментом] сейчас пользуюсь.’.
В языках, имеющих грамматический род, местоимения- заменители обычно согласуются в роде с существительным, которое является вершиной группы-антецедента. В некоторых языках (например, в немецком) местоимение-заменитель всегда согласуется в роде с существительным — вершиной группы антецедента, тогда как в других языках (например, в идиш и во французском) оно согласуется в роде с этим существительным не всегда, а только если оно не обозначает лицо; если же оно обозначает лицо, форма местоимения зависит от пола данного лица, но не от рода соответствующего существительного. Для местоимений в дей- ктическом (то есть неанафорическом) употреблении выбор рода всегда делается на основе пресуппозиций относительно референта: когда в комнату входит девушка, человек может спросить по-немецки у своего соседа Wie heiBt sie? ‘Как ее зовут?’, хотя позже в разговоре он будет обозначать ту же самую девушку das Madchen и употреблять в качестве анафорического местоимения es. Правила выбора местоимений в немецком, французском и английском языках имеют следующую общую особенность: именной группе приписываются некоторые грамматические признаки, присущие существительному — вершине данной группы (во французском это верно лишь для групп, которые не обозначают лиц). Прономинализация, то есть введение местоимений, состоит в элиминации именной группы при сохранении референ- ционного индекса и указанных грамматических признаков; форма замещающего местоимения определяется на основе этих признаков и пресуппозиций, относящихся к референту группы (референт же задается индексом). При введении местоимения в дейктической функции именной группе не приписаны признаки числа и рода, так что выбор местоимения делается исключительно на основе информации о референте*.
Однородные члены, сочинительное сокращение и множественное число
До сих пор я говорил о референционных индексах как о таких определенных единицах в концептуальном аппарате говорящего, каждая из которых осознается как соотносящаяся с индивидуальным объектом. Это действительно так в случае именных групп единственного числа (ИГ,г)Л Однако именная группа множественного числа обозначает не объект, а множество объектов. При этом именная группа множественного числа №Тр1 также должна иметь референционные индексы: точно так же, как ИГ^, любая ИТрі может удовлетворять или не удовлетворять условиям тождественности — в зависимости от ее референта. Поскольку \\Тр1 обычно обозначает множество, ее референционный индекс должен вести себя как множество; и в самом деле, существуют синтаксические явления, свидетельствующие о том, что над индексами, по-видимому, возможны теоретикомножественные операции и что синтаксические правила должны предусматривать использование результатов этих операций.
Рассмотрим однородные (=сочиненные) определенйя в выражениях следующего типа:
(53) the male and female employees ‘служащие мужского и женского пола’;
(54) new and used books
‘новые и подержанные книги’;
(55) the string quartets of Prokofiev and Ravel ‘струнные квартеты Прокофьева и Равеля’,
Заметим, что в (53) имеются в виду вовсе не служащие, которые принадлежат одновременно и мужскому и женскому полу, а совокупность служащих мужского и служащих женского пола. Поэтому (53) можно перефразировать как
(56) the male employees and the female employees ‘служащие мужского пола и служащие женского пола’.
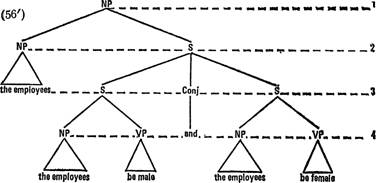
Я полагаю, что цепочки однородных определений данного типа имеют глубинную структуру типа (56') (указания о времени глаголов опущены).
Здесь оба вхождения существительного employees, подчиненные узлу S [строка 2], имеют разные референционные индексы, например А и В. Определительное предложение, относящееся к NP the employees [строка 21, удовлетворяет условиям трансформации с respectively; ее применением (56') дает (57'):
157') NP
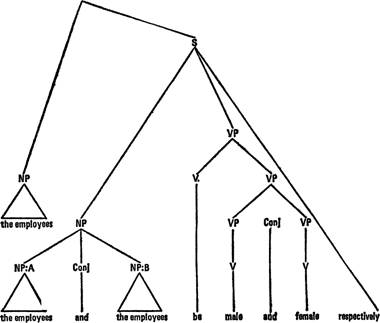
Поддерево дерева (57') с вершиной S описывает недопустимое в английском языке предложение:
(57) *The employees and the employees are male and female respectively.
Однако к (57 ) должна быть применена обязательная трансформация, сокращающая конъюнктивно сочиненную группу подлежащего the employees and the employees в the employees. (Эта сокращающая трансформация необходима в грамматике английского языка ради получения таких фраз, как
(58) These boys ate respectively Polish and Irish. ‘Эти мальчики являются соответственно поляками и ирландцами.’,
поскольку конструкция с respectively невозможна при формально идентичных сочиненных подлежащих.) В результате получается структура (58'):
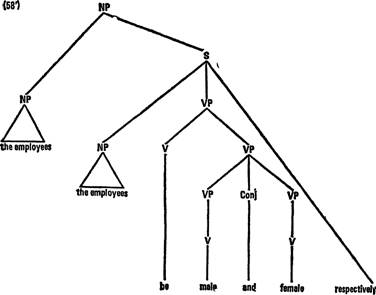
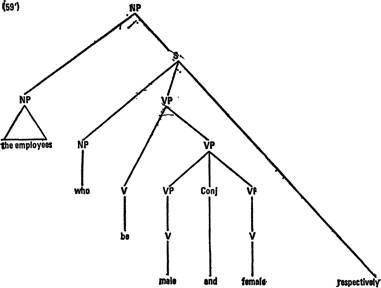
К этой структуре применяется трансформация релятивизации, превращающая вхождение the employees во вложенном предложении в относительное местоимение. В результате получается структура (59') [см. с, 263], которая может быть реализована как
(59) the employees who are male and female respectively ‘служащие, которые являются мужчинами и женщинами соответственно’.
Слово respectively, а также относительное местоимение вместе со связкой могут элиминироваться (факультативно); в этом случае цепочка однородных предикатов male and female обязательно ставится перед существительным — с с помощью общеизвестного правила препозиции определений (Smith, 1964; L а к о f f, 1965), так что получается
(63).
В результате применения трансформации с respectively образуется именная группа, содержащая цепочку однородных определений; эта ИГ должна иметь референционный индекс, поскольку она участвует в трансформациях, требующих совпадения индексов; например, эта ИГ может иметь при себе описательное (но не ограничительное) придаточное определительное. Я предлагаю считать референ- ционным индексом подобной ИГ теоретико-множественное объединение индексов ее компонентов. Тогда в (57') ИГ the employees and the employees получает индекс А и В; этот индекс останется и после применения сокращающего правила (то есть в (58')).
Поскольку к (53) можно присоединить описательное придаточное, например:
(60) The male and female employees, who say they are dissatisfied, are actually very well paid.
‘Служащие мужского и женского пола, которые заявляют, что они не удовлетворены, в действительности оплачиваются очень хорошо.’,
и поскольку соответствующее правило требует совпадения референционных индексов, необходимо иметь возможность убедиться, что индекс у ИГ в присоединяемом придаточном равен A U В.
Решение иметь для ИГ с конъюнктивным сочинением в качестве ее референционного индекса теоретико-множественное объединение индексов ее компонентов позволяет объяснить некоторые интересные факты, связанные с сочинением и множественным числом. Только на основе неязыковых сведений я знаю, что правильной перифразой для (55) является (61):
(61) the string quartets of Prokofiev and the string quartet of Ravel ‘струнные квартеты Прокофьева и струнный квартет Равеля’.
Однако, если бы мне предъявили совершенно аналогичное выражение, включающее имена не известных мне композиторов, например:
(62) the string quartets of Eierkopf and Misthaufen ‘струнные квартеты Эйеркопфа и Мистхауфена’,
я не мог бы сказать, какая из четырех возможных перифраз является правильной*:
(63) the quartet of Eierkopf and the quartet of Misthaufen ‘квартет Эйеркопфа и квартет Мистхауфена’;
(64) the quartets of Eierkopf and the quartet of Misthaufen ‘квартеты Эйеркопфа и квартет Мистхауфена’;
(65) the quartet of Eierkopf and the quartets of Misthaufen ‘квартет Эйеркопфа и квартеты Мистхауфена’;
(66) the quartets of Eierkopf and the quartets of Misthaufen ‘квартеты Эйеркопфа и квартеты Мистхауфена’.
При этом существенно, что, какова ни была бы правильная перифраза — у Эйеркопфа и Мистхауфена по одному квартету, у обоих по нескольку квартетов, у одного один квартет, а у другого несколько,— все равно в (62) необходимо множественное число quartets. Это доказывает, что морфема множественного числа не должна выступать в глубинной структуре; она может вводиться специальным правилом в зависимости от того, имеет ли данная именная группа множественный индекс. Точнее, морфема множественного числа присоединяется к любому существительному, которое непосредственно подчиняется узлу «именная группа», имеющему множественный индекс.
Заметим, что понятие множества, как оно используется здесь применительно к английскому синтаксису и семантике, отличается от математического понятия множества. В математике допускаются одноэлементные множества и даже пустое множество, тогда как для правил, интересующих нас здесь, существуют только не менее чем двухэлементные множества. Наша «теория множеств» игнорирует различие между элементом и одноэлементным множеством и допускает объединение элементов: XiUx2={xi, х2}. Подобная трактовка элементов и множеств делает возможным единообразное описание разных случаев грамматического согласования в числе. В работах по трансформационной грамматике (например, Lees, 1960, р. 44) согласование в числе между сказуемым и подлежащим описывается посредством правила, которое ставит сказуемое во множественном числе, либо если подлежащее содержит морфему множественного числа, либо если имеется ряд однородных подлежащих. Ясно, однако, что множественное число сказуемого определяется не столько морфемой множественного числа при подлежащем, сколько «множественностью» всей группы подлежащего. Эта множественность в общем соответствует различию между множеством (в оговоренном выше, то есть нематематическом, смысле) и элементом, хотя данное соответствие и не является вполне точным; его нарушают pluralia tantum типа scissors ‘ножницы’, требующие сказуемого во множественном числе, даже если они имеют индивидуальный индекс.
Для обеспечения согласования в числе необходимы следующие упорядоченные правила.
а) Приписать узлу «именная группа» признак [+ plural], если он имеет множественный индекс, и признак [— plural] в противном случае.
б) Приписать узлу «именная группа» признак [+ plural], если он непосредственно подчиняет существительное с пометой «pluralia tantum».
в) Приписать сказуемому признак [+ plural] или [— plural] в зависимости от того, какой признак — ([+ plural] или [— plural]) — имеет подлежащее.
Множественный индекс необходим для обеспечения правильного согласования в;
Здесь оба глагола стоят во множественном числе, хотя семантически каждый из них связан с подлежащим в единственном числе: сочиненное подлежащее, возникшее в результате применения трансформации с respectively требует согласования по множественному числу, так что (69) грамматически недопустимо:
(69) *John and Harry likes the play and is disappointed by it respectively,
Из этих примеров следует, что правило, обеспечивающее согласование сказуемого с подлежащим, не может быть представлено формулой того типа, какими обычно пользуются для изображения трансформаций: это правило должно приписывать согласовательный признак числа не просто одному глаголу, а сразу всем однородным глаголам в составе сочиненного сказуемого (трансформация, создающая грамматическую множественность, то есть сочиненное подлежащее, в то же время создает и сочиненное сказуемое).
Выше рассматривались сочиненные именные группы (ИГ), возникшие в результате применения трансформации с respectively. Как же обстоит дело с другими конъюнктивно сочиненными ИГ? Н. Хомский (Chomsky, 1957, р. 35— 37) предложил считать, что все сочиненные группы получаются из множеств простых предложений; тогда, например, предложение
(70) John and Harry are erudite, ‘Джон и Гарри эрудиты.’
представляет собой результат применения сочинительной трансформации к структурам предложений John is erudite. ‘Джон эрудит.’ и Harry is erudite. ‘Гарри эрудит’. Эта же идея выступает в слегка измененной форме в С h о m s к у, 1965, р. 225; там (все?) сочиненные группы трактуются как выводимые из сочиненных предложений, так что (70) получается посредством трансформации сочинительного сокращения (conjunction reduction) из структуры, которая реализуется в виде
(71) John is erudite and Harry is erudite.
‘Джон эрудит и Гарри эрудит.1
Известно, однако, что некоторые сочиненные группы не могут быть выведены из сочиненных предложений, например:
(72) John and Harry are similar. ‘Джон и Гарри похожи/
или
(73) John and Mary embraced, ‘Джон и Мэри обнялись/. Отметим, что предложение
(74) *John is similar.
является неправильным; оно допустимо лишь как результат эллипсиса в случаях типа
(75) Max is a fool; John is similar.
букв. ‘Макс дурак; Джон таков же/
Выражения типа
(76) *John embraced. ‘Джон обнялся/
абсолютно недопустимы.
Лакофф и Питерс предложили считать, что (70) имеет в качестве глубинной структуры конъюнкцию предложений, тогда как глубинной структурой для (72) является простое предложение с конъюнкцией подлежащих (L а к о f f — Peters, 1966):
Еще по теме Регулярная неоднозначность:
- Неоднозначные ситуации “серой зоны”
- 2. Неоднозначность действия фактора на разные функции.
- Культура развитого социализма: противоречивость и неоднозначность
- Обязательность и регулярность
- § 12. Регулярные и нерегулярные аффиксы
- Регулярные реализации
- § 1. Абсолютная регулярность фонетических изменений
- 1.5 Анализ локальной регулярности
- 5.16. Регулярна інформація про емітент
- 2.4. Представление регулярных функций интегралами