ПОСТСКРИПТУМ (МАЙ 1967 Г.)
С тех пор как настоящая статья была написана, мое мнение по некоторым поднятым в ней вопросам изменилось. Двух таких вопросов я хотел бы коснуться здесь,
1) 0 множественных референционных индексах и трансформации с respectively
Теперь я полагаю, что использование признака [± объединительная)] при ИГ с однородностью — это весьма искусственный прием, который в рамках адекватного описания рассмотренных здесь явлений необходимо заменить какими-либо иными, теоретически более удовлетворительными средствами.
Одно из таких средств было затронуто в неявной форме при характеристике семантических представлений различных значений фразы (87). Символ у, выступающий в этих представлениях, может рассматриваться (в соответствии с предложением П, Постала) как индекс при глаголе:3 V/
Объединительно: у х.м [х goy to Cleveland]
V з
Разделительно: х.Му [х goyx to Cleveland]
Дж, Росс обратил мое внимание на то, что «объединительное» и «разделительное» значения таких фраз, как (84) и (87), ведут себя по-разному при номинализации:
(130) John and Harry’s departure for Cleveland.
‘Отъезд Джона и Гарри в Кливленд’ (объединительно).
(131) John’s and Harry’s departures for Cleveland. ‘Отъезды Джона и Гарри в Кливленд,1 (разделительно).
(132) The departures of John and of Harry for Cleveland, (разделительно).
Различие индексов при глаголах в исходных выражениях объясняет различие в числе соответствующих отглагольных существительных: при «объединительном» значении глагол имеет индивидуальный индекс у, а при «разделительном» значении — множественный индекс {yi, г/а}, где yi соответствует отъезду Джона, а у2— отъезду Гарри. Таким образом, различие между индивидуальными и множественными индексами характерно не только для существительных, но и для глаголов.
Множественный индекс у глагола выступает также при наличии адъюнктов twice ‘дважды’, many times ‘много раз’ и т. п. Ср. следующие примеры:(133) John denied the accusation five times.
‘Джон пятикратно [= пять раз] отводил обвинение.’
(134) John’s five denials of the accusation.
‘Пять отведений обвинения Джоном,1
(135) *John’s denials of the accusation five times.
Семантически five times ‘пять раз’ эквивалентно слову five ‘пять’ в five horses ‘пять лошадей’: выражение five
times означает, что мощность некоторого множества равна пяти. Слово times — это, так сказать, пустая морфема, с помощью которой к личному глаголу присоединяется количественное числительное [107]5.
Отглагольное существительное (‘отъезд’) в (131) стоит во множественном числе, аналогично существительному wives в (141):
(141) John and Harry love their wives.
‘Джон и Гарри любят своих жен.1
Единственное число wife ‘жену* было бы уместно здесь, только если бы речь шла о многомужестве. В (141) можно добавить слово respective без всякого изменения смысла:
(142) John and Harry love their respective wives. ‘Джон и Гарри любят своих жен — каждый свою соответственно.’
Добавление прилагательного respective возможно также для фраз (131) и (132):
(143) John’s and Harry’s respective departures for Cleveland.
(144) The respective departures of John and Harry for Cleveland.
Поскольку respective и respectively тождественны no смыслу и находятся в дополнительном распределении (respective присоединяется к существительному, a respectively — к глагольной составляющей или к предложению), то приходится принять два следующих утверждения:
— фраза (142) получается с помощью той же самой трансформации, что и фраза (145):
(145) John and Harry love Mary and Alice respectively. ‘Джон и Гарри любят Мэри и Элис соответственно.’;
— глубинные структуры фраз (142) и (145) различаются только тем, что в (142) мы имеем John’s wife и Harry’s wife, а в (145) — Магу и Alice.
Из приведенных соображений следует, что «разделительное» значение фразы (84) выводится из
(146) John gpyt to Cleveland and Harry goy, to Cleveland.
посредством трансформации с respectively, которая и объясняет наличие множественного индекса у go в данном («разделительном») значении фразы (84).
Здесь, однако, встает следующая проблема: всем рассмотренным фразам соответствуют аналогичные фразы с подлежащим во множественном числе (без однородности):
(87) These men went to Cleveland.
‘Эти люди уехали в Кливленд.’
(147) Those men’s respective departures for Cleveland. ‘Отъезды этих людей в Кливленд (каждого по отдельности).’
(148) The respective departures of those men for Cleveland (то же).
(149) Those men love their respective wives.
‘Эти люди любят своих жен (каждый свою).’
Однако если respective вводится посредством трансформации с respectively, которая, как это предполагалось до сих пор, применяется к конъюнктивно-сочиненным структурам, то каким же образом respective должно появляться в примерах (147) — (149), где нет сочиненных групп? Здесь возможны два решения: либо соответствующим образом
обобщить трансформацию с respectively, либо выводить все ИГ множественного числа из глубинных сочиненных групп. Второе решение, предлагаемое Посталом, представляется на первый взгляд привлекательным, в частности, потому, что в ряде случаев (см., например, (58)) именные группы множественного числа действительно приходится выводить из глубинных сочиненных групп. Имеется, однако, следующий существенный довод против этого решения. В самом деле, для обеспечения правильной семантической интерпретации количество сочиненных групп в глубинной структуре любой ИГ множественного числа должно равняться количеству объектов, о которых идет речь: так, в глубинной структуре выражения the 63, 428 persons in Yankee stadium ‘63 428 человек на стадионе «Янки»’ не удастся обойтись всего двумя сочиненными группами. Однако ИГ во множественном числе далеко не всегда обозначает точно определенное количество объектов:
(150) Не has written approximately 50 books.
‘Он написал приблизительно 50 книг.’
(151) There were very few persons at the football game. ‘На футболе было очень мало людей.’
(152) There were an enormous number of persons at my party.
‘На моей вечеринке было ужасно много людей.’
(153) How many times have you failed your French examination?
‘Сколько раз ты проваливался на экзамене по французскому языку?’
Названные ИГ множественного числа невозможно представить и как дизъюнкции всех конъюнкций, имеющих число членов в пределах, задаваемых выражениями типа approximately fifty ‘приблизительно пятьдесят’ и т. п., поскольку эти пределы могут очень сильно меняться в зависимости от того, о чем идет речь: так, в (151) под ‘очень мало’ может пониматься 5000, а в (152) под ‘ужасно много’— 50. Кроме того, в некоторых случаях, когда употребить неопределенное обозначение количества невозможно, числительное, которое называет точно определенное количество, лежащее в тех же пределах, вполне употребимо*:
(154) Those five men are Polish, Irish, Armenian, Italian, and Chinese, respectively.
‘Эти пять мужчин — поляк, ирландец, армянин, итальянец и китаец соответственно.’
(155) *Those several men are Polish, Irish, Armenian, Italian, and Chinese, respectively.
‘Эти несколько мужчин — поляк, ирландец, армянин, итальянец и китаец соответственно.’
Таким образом, чтобы описать вывод фраз типа (141) —
(149) , нам придется изменить формулировку трансформации с respectively так, чтобы она была применима и к тем структурам, где нет конъюнкции, но есть ИГ во множественном числе, или, вернее, ИГ с множественным индексом. При этом pluralia tantum допускают respectively только в том случае, если они имеют множественный индекс; фраза
(156) The scissors are respectively sharp and blunt.
‘Эти ножницы соответственно остры и тупы.’
может означать только, что речь идет о д в у х парах ножниц. Тем самым точная формулировка трансформации с respectively должна предусматривать множественный индекс.
Это, разумеется, вполне естественно — ведь задача данной трансформации состоит в том, чтобы «распределять» квантор общности по обозначениям отдельных объектов. В самом деле, все рассматриваемые фразы могут быть представлены как содержащие квантор общности; в результате применения трансформации с respectively получается трансформ, где вместо вхождений переменной, связанной этим квантором, выступает образ множества, являющегося областью определения подкванторной переменной. Например, семантическое представление фразы (149) имеет вид:Хм l°ves *‘s wife].
где М — множество людей, о которых идет речь.
Фразе (142) можно приписать представление
Y , Гх loves x‘s wifel,
*€ {*i. x,} L j’
где Xi— John, a x2— Harry0. В самих этих фразах мы имеем those men или John and Harry на месте одного из вхождений связанной переменной х и притяжательное местоимение their на месте ее другого вхождения. При этом слово wife должно стоять во множественном числе, поскольку после применения трансформации с respectively та ИГ, в которую входит wife, имеет множественный индекс — индекс, отвечающий множеству всех жен, о которых идет речь. (142) отличается от (145) тем, что имя функции, выступающее в (142) в подкванторном выражении [/ (x)=x's wife], является единицей языка: знание слова wife относится к владению английским языком (то есть к competence говорящего), тогда как в (145) аналогичная функция вводится ad hoc для данной фразы [/ (х1)=Магу, f (х2)=Alice]2’.
Из сказанного можно сделать вывод, что те представления фраз, к которым применима трансформация с respectively, предполагают наличие не только множественных индексов, но и кванторов; подобные представления следует называть скорее семантическими, нежели синтаксическими.
Так мы подошли ко второму важному вопросу, по которому мое мнение изменилось.
2) 0 статусе глубинной структуры как особого уровня представления высказываний
Полемизируя с многими частностями грамматической теории Н.
Хомского, выдвинутой в С h о ш s к у, 1965, я принимал основные положения этой теории в целом и, в частности, был согласен с гипотезой о том, что грамматика состоит из трех основных компонентов: базовый (= порождающий) компонент, задающий множество правильно построенных глубинных структур; семантический компонент, устанавливающий соответствие между глубинными структурами и их семантическими представлениями, и трансформационный компонент, устанавливающий соответствие между глубинными структурами и их поверхностносинтаксическими представлениями. Тем самым предполагается существование трех уровней представления языковых высказываний. Два последних, а именно семантический и поверхностно-синтаксический уровни, не вызывают сомнения; они оба, по крайней мере имплицитно, присутствуют во всех известных лингвистических концепциях. Однако введение промежуточного уровня глубинных структур нуждается в специальном обосновании. Действительно, a priori не ясно, почему грамматика не может быть устроена иначе и состоять, например, из следующих компонентов: порождающий семантический компонент (=правила образования), который задавал бы множество правильно построенных семантических представлений, и трансформационный компонент (= правила преобразования), который обеспечивал бы соответствие между семантическими и поверхностно-синтаксическими представлениями — примерно так же, как трансформационный компонент грамматики Хомского устанавливает соответствие между глубинными структурами и их поверхностными реализациями. При этом обязанность доказывать существование уровня глубинных структур лежит, разумеется, на тех исследователях, которые его постулируют,— аналогично тому, как в фонологии доказывать существование «фонемного» уровня, промежуточного между лексико-фонологическим (= системнофонемным, или морфофонемным) и фонетическим представлениями, должны именно те, кто на нем настаивает. Приверженцы трансформационной грамматики, как правило, пренебрегали необходимостью специально обосновывать введение уровня глубинных-структур, так же как фонологи-дескриптивисты пренебрегали необходимостью обосновывать введение фонемного уровня. Причина в обоих случаях одна и та же: фонологи всегда трактовали фонемный уровень как свою область, а морфонологию — как terra quasi incognita, так что попытки дать общее описание морфонологии были редкими, да к тому же обычно носили скорее программный и даже анекдотический характер (см., например, Harris, 1951, глава 14). Совершенно так же представители трансформационной школы целиком ушли в синтаксис и не сумели найти общий подход к описанию соответствий между семантическим и поверхностно-синтаксическим представлениями, хотя такой подход необходим для того, чтобы решить, разумно ли разбивать механизм, задающий это соответствие, на два компонента, один из которых был бы системой семантических (= проекционных) правил, а другой — системой синтаксических трансформаций.Когда Халле, Лиз и другие приняли весьма общий подход к описанию соответствий между лексико-фонологическим и фонетическим представлениями, они обнаружили некие единые явления, которые не удавалось описать как таковые в рамках грамматики, имеющей две отдельные системы правил — «морфонологические» и «фонетические» (= allo- phonic) правила, соотносящиеся через «фонологический» уровень. Так, например, ассимилятивное озвончение в русском языке оказывается фонетическим правилом в случае [cl, [£] и [х], номорфонологическим правилом в случае всех прочих шумных, так что в грамматике, имеющей фонологический уровень, озвончение пришлось бы описывать посредством двух отдельных правил, принадлежащих к разным компонентам грамматики. Естественно, встает вопрос, не обнаружатся ли подобные явления, когда будет принят общий подход к соответствиям между синтаксисом и семантикой. Я утверждаю, что такой пример был только что продемонстрирован: это трансформация с respectively. С одной стороны, она описывает соответствие между представлением, включающим кванторы и связанные переменные, и представлением, включающим обычные ИГ; таким образом, она делает то, что в С h о ш s к у, 1965 отводится на долю проекционных правил. С другой стороны, однако, как указал Пол Постал (устное сообщение 8 мая 1967 г.), она выполняет операцию, которую принято считать синтаксической трансформацией — сочинительным сокращением (conjunction reduction): ср. вывод фразы (84) из сложносочиненного предложения. Постал подчеркивает, что если снять ограничение, требующее, чтобы сочинительное сокращение применялось к паре сочиненных структур, между которыми имеется только одно различие, то сочинительное сокращение окажется частным случаем трансформации с respectively. Так различие между
(157) That man loves Mary and Alice.
‘Тот человек любит Мэри и Элис.’
(158) Those men love Mary and Alice respectively.
‘Те люди -любят Мэри и Элис соответственно.*
полностью сводится к тому, имеют ли в глубинных структурах данных фраз два разных вхождения ИГ that man одинаковые или разные индексы. И та и другая фраза выводятся из
(159) That man loves Mary and that man loves Alice. ‘Тот человек любит Мэри, и тот человек любит Элис.’
посредством трансформации с respectively, и в обоих случаях получается сочиненное подлежащее that man and that man, которое должно быть сокращено по специальному правилу; однако если оба вхождения группы that man имеют одинаковый индекс, то теоретико-множественное объединение их индексов равно этому индексу (jci U*i=*i), и в результате применения ряда сокращающих трансформаций получается (157). Из всего этого я делаю вывод, что преобразование с respectively не может быть описано как единое явление в грамматике, выделяющей специальный уровень глубинных структур, и, следовательно, что такая концепция грамматики должна быть отвергнута в пользу изложенной выше альтернативы, выдвинутой Лакоффом и Россом (см. Lakoff — Ross, 1967).
Если принять этот вывод, то синтаксический и семантический компоненты грамматики, предполагаемые теорией Хомского, должны быть заменены одним компонентом — одной системой правил, преобразующих семантическое представление через ряд промежуточных представлений в поверхностно-синтаксическое представление. Здесь, однако, сразу же встает вопрос: не окажутся ли в данном компоненте — вместо единой системы однородных правил — правила двух принципиально разных типов, а именно правила, определенные на семантических представлениях, и правила, определенные на синтаксических представлениях?
Чтобы ответить на этот вопрос, необходимо сначала выяснить, насколько те и другие представления различаются по своей формальной природе. На Техасской конференции по языковым универсалиям Джордж Лакофф показал, что между этими двумя типами представлений различия могут оказаться гораздо меньшими, чем это предполагалось до сих пор. Лакофф отметил, в частности, наличие почти точного соответствия как между большинством базовых синтаксических категорий и элементарными термами математической логики, так и между правилами, которые Росс и Лакофф предложили в качестве универсальных правил базового компонента, и общеизвестными правилами образования в логике. Так, «правило релятивизации» NP=>NP S соответствует правилу логики, гласящему, что из терма х и предиката / можно построить терм \х : f (х)}, то есть ‘такие х, что f (х)’. Далее, в семантических представлениях также выделяются составляющие, группировка которых может быть показана с помощью скобок и, следовательно, представлена в виде дерева. Поскольку категории, высту-
Лающие в Правилах образования математической логйкй, соответствуют синтаксическим категориям, семантические представления (в основу которых должен, как я предполагаю, лечь язык математической логики) можно рассматривать как деревья, помеченные символами синтаксических категорий. Наконец, нет никаких априорных соображений против линейного порядка составляющих в семантических представлениях. В этой связи надо отметить, что существует ошибочное мнение (приводящее к ряду недоразумений), будто выражения, одинаковые по смыслу, обязательно должны иметь одинаковые семантические представления. Однако понятие «смысловое тождество» прекрасно можно определять как отношение эквивалентности между семантическими представлениями: два выражения называются тождественными по смыслу, если их семантические представления эквивалентны (но не обязательно тождественны). Например, фразы
(160) I spent the evening drinking and singing songs.
‘Я провел вечер, выпивая и распевая песни.1
и
(161) I spent the evening singing songs and drinking.
‘Я провел вечер, распевая песни и выпивая/
могут иметь семантические представления, различающиеся порядком сочиненных предложений, но эквивалентные в силу правила рДч эквив qAp. Таким образом, ничто не мешает трактовать семантические представления как упорядоченные деревья, узлы которых помечены символами синтаксических категорий; тогда единственное формальное различие между семантическими и синтаксическими представлениями заключается в типе составляющих, являющихся терминальными узлами дерева. Тем самым с формальной точки зрения правила преобразования семантических представлений в поверхностно-синтаксические — это правила, отображающие одно множество упорядоченных размеченных деревьев на другое множество упорядоченных размеченных деревьев. Среди этих правил должны быть не только присоединения (adjunctions), элиминации (deletions) и перестановки (permutations), известные из теории Хомского (Chomsky, 1965), но и правила лексического заполнения (lexical insertion transformations), подставляющие лексические единицы вместо определенных фрагментов размеченного дерева. Однако правила лексического заполнения необходимы в грамматике и с точки зрения теории Хомского, поскольку, например, прономинализация предполагает введение новых лексических единиц (местоимений) вместо поддеревьев, заполненных до этого другими лексическими единицами. При этом некоторые правила лексического заполнения должны применяться в самом конце процесса вывода фразы, как показывают следующие два примера®: (1) Выбор выражений the former или the latter может производиться лишь после того, как выполнены все трансформации, перемещающие ИГ во фразе. (2) Если в результате прономинализации оказываются сочиненными два одинаковых местоимения, то их необходимо заменить новым местоимением (на этот факт мне указал Джон Росс):
(162) Не and she live in Boston and Toledo respectively. ‘Он и она живут в Бостоне и Толидо соответственно.’
(163) *Не and he live in Boston and Toledo respectively.
(164) They live in Boston and Toledo respectively.
‘Они живут в Бостоне и Толидо соответственно.’
Н. Хомский утверждает (Chomsky, 1965), что лексическое заполнение производится в процессе работы базового компонента, если только оно не обусловливается другими трансформациями, как в примере (164). Против этой точки зрения высказывались возражения двух типов: с одной стороны, Дж. Грубер полагает (Gruber, 1965), что лексические единицы, образующие пары типа buy/sell ‘покупать/продавать’ и send/receive ‘посылать/получать’, вводятся в глубинную структуру в результате применения трансформаций, предшествующих лексическому заполнению; с другой стороны, Лакофф и Росс (L а к о f f — Ross, 1967) считают, что многие идиомы должны вводиться в глубинную структуру после применения ряда трансформаций. Таким образом, в одном случае определенные трансформации должны работать в процессе порождения раньше, чем это предполагается теорией, развиваемой в Chomsky, 1965, а в другом случае некоторые лексические заполнения должны осуществляться позже, чем допускает теория Хомского.
Принятие той концепции грамматики, которую я здесь отстаиваю, ведет к следующему интересному выводу: лексические единицы могут вводиться в глубинную структуру
на место составляющих, возникших в результате применения трансформаций. Многие из сравнительно недавно предложенных трансформаций можно, следовательно, рассматривать как правила комбинирования семантических составляющих до лексического заполнения; такими трансформациями являются, например, различные номинализации и образование производных каузативов и инхоативов (L а- k о f f, 1965). Тем самым различие между «трансформационно выводимыми» и «лексическими» единицами, которое многие лингвисты (в особенности Н. Хомский — см. Chomsky, 1971) считают весьма важным, оказывается, по-видимому, иллюзорным.
ПРИМЕЧАНИЯ [108]
а (К с. 238). Из того, что sadi и sad2 — это разные лексические единицы, вовсе не следует, что между ними нет ничего общего. Было бы точнее сказать, что sad2 означает ‘вызывающий состояние «sadx»’ [то есть грустный^ грустьі — это определенное состояние психики человека, а грустный2='вызывающий грусть^; так я и поступил в своей работе 1968 г. (см. М с С a w 1 е у, І968а).
ь (К с. 243—244). Не исключено, что этот пример доказывает лишь, что разные люди могут приписывать слову bachelor разные значения, то есть для одних оно означает ‘не состоящий в браке* [и применимо к людям любого пола], а для других — только ‘неженатый* [и применимо лишь к мужчине].
с (К с. 244—245). В то время, когда я писал это, я полагал, что подобное правило должно отличаться от трансформации, стирающей в выражении ‘каузирует того, кто носит ее [=одежду], чувствовать себя Х-ово* все, кроме символа «Х-ово». Однако теперь я не вижу, как можно было бы обосновать данное мнение. Далее, оказалось, что мое утверждение, будто всякое английское прилагательное, обозначающее температуру, может быть применено и к одежде с соответствующим изменением смысла, разумеется, ошибочно; так, lukewarm ‘тепловатый’ обозначает температуру, однако нельзя назвать какую-либо одежду lukewarm.Правильнее было бы говорить не об обозначении температуры, а об обозначении температурных ощущений: вода или пища могут быть lukewarm, однако человеку не может быть lukewarm [I am warm/cold ‘Мне тепл о/хол одно’, но не *1 am lukewarm ‘Мне тепловато’]. (Данным уточнением я обязан Алену С. Принсу.)
“ (К с. 245). Ален С. Принс обратил мое внимание на то, что данное явление не ограничивается сочетаниями прилагательных с названиями одежды. В самом деле, во фразах типа:
This blanket isn’t warm enough. ‘Это одеяло недостаточно теплое.’; The fire is warm. букв. ‘Огонь теплый.*; The breeze is cool. ‘Бриз прохладен.* речь идет только о температурных ощущениях человека, а не о
реальной температуре называемых объектов (температура огня может быть выше 300°С, а про это вряд ли можно сказать warm; говорить же о собственной температуре бриза вообще бессмысленно). Принс отметил также, что подобная многозначность характерна для названий не только температурных, но и многих других телесных ощущений:
This sweater is itchy.‘Этот свитер вызывает зуд.’ при I feel itchy. ‘Я испытываю зуд’;
This bed is comfortable. ‘Эта кровать удобна.* при I feel comfortable. ‘Мне удобно.* и т. п.
е (К с. 250). Те факты, которые, по-видимому, противоречат последнему утверждению, приводятся в Y и с к, 1969, и К а у е, 1971. Что же касается трактовки грамматического числа, предлагаемой в настоящей статье, то против нее в Р е г 1 m u 11 е г, 1972 выдвинут ряд серьезных возражений.
7 (К с. 252). Строго говоря, это в действительности неверно. Вложенные вежливые формы возможны, например, в преувеличенно (до подобострастия) предупредительной речи, скажем в стандартных обращениях проводников на железной дороге:
O-wasuremono gozaimasen yoo-ni go-tyuui kudasai ‘Ваши-драгоцен- ные-вещи не-соблаговолите-ли-Вы не оставить, пожалуйста*.
8 (К с. 253). Местоимение one (или его антецедент) само вполне может быть антецедентом для возвратного местоимения, и поэтому оно также должно иметь референционный индекс:
A tall Armenian kicked himself, and then a short one slapped himself. ‘Один высокий армянин лягнул себя, и тогда другой, маленький, армянин шлепнул себя*.
Н. Хомский, возражая против содержания сноски 6 (к с. 253), утверждает, что в соответствии с его концепцией референционных индексов, объектная NP в John has a blue hat. ‘У Джона есть синяя шляпа.’ вовсе не обязана иметь индекс (Chomsky, 1970, р. 220). Однако только что приведенный пример показывает, что подход Хомского требует, чтобы подобные составляющие снабжались индексами: в противном случае возвратные местоимения во фразах John kicked himself. ‘Джон лягнул себя.’ и A tall Armenian kicked himself. ‘Один высокий армянин лягнул себя.* должны вводиться по-разному, что явно нелепо.
h (К с. 258). Я позволил себе абстрагироваться от несогласованности времен во фразе (48).
1 (К с. 260). Трактовка согласования, предложенная здесь, весьма убедительно критикуется в К и г о d а, 1969.
/ (К с. 260). Обсуждая вопрос о грамматическом числе, я оставил в стороне «вещественные» существительные — обозначения аморфных масс, в частности веществ (=mass nouns). Вещественные выражения обычно остаются вне поля зрения логиков, интересующихся семантикой естественных языков; так, квантификация вещественных выражений до сих пор не описана сколько-нибудь удовлетворительным образом. Хотя в Parsons, 1970 есть много интересного, мне представляется, что его подход — рассматривать все возможные разбиения массы на дискретные части, а затем применять к множествам этих дискретных частей обычную квантификацию — в целом принят быть не может. Я предпочел бы описание, основанное на таком понятии ‘быть частью*, которое было бы равно применимо и к массам, и к множествам, причем .обычная квантификация оказывалась бы частным случаем.
к (К с. 265). И не утверждаю, что фраза (62) в действительности четырехзначна, то есть что она имеет значения фраз (63)—(66), Мои примеры показывают только, что независимо от того, указано Ли грамматическое число у именных групп в исходной структуре и каково оно, предлагаемая здесь трактовка индексов обязательно требует, чтобы результирующая ИГ была во множественном числе. Как мне кажется, фраза (62) неоднозначна в отношении числа ровно в той же степени, в какой фраза My cousin and my neighbor hurt themselves неоднозначна в отношении рода ‘Мой кузен/моя кузина и мой сосед/моя соседка ушиблись*. А именно, я полагаю, что обе эти фразы не являются неоднозначными; однако мне неизвестен какой-либо формальный критерий, с помощью которого можно было бы решать вопрос об однозначности/неоднозначности фраз в подобных случаях.
1 (К с. 269). В Q u a n g, 1969, показано, что предложение Лакоффа и Питерса не может быть принято. т (К с. 270). Вместо
гем I* хорошо играет в теннис]
‘для всякого х, принадлежащего М, верно, что х хорошо играет в теннис’ я должен был бы писать
хем Iх Х°Р°Ш0 играет в теннис]
‘для всякого х, такого, что х принадлежит М, верно, что х хорошо играет в теннис’.
Такая запись применима и в тех случаях, когда речь не идет о множествах, принадлежности множеству и т. п.:
х -человек Iх смертен] ‘все люди смертны*.
п (К с. 272). Из сказанного не вполне ясно, в каком именно смысле употреблено здесь слово «эквивалентный». В более поздней работе — М с С a w 1 е у, 1970,— в явной форме отмечено, что логическая эквивалентность (два высказывания называются логически эквивалентными, если каждое из них может быть выведено из другого) — это более слабое свойство, чем тождество смыслов; там же даны примеры различных, но логически эквивалентных смыслов. Как указал Дж. Лакофф (на конференции, где данная статья была зачитана в качестве доклада), выписанное здесь «правило эквивалентности» фактически не отличимо от трансформации сочинительного сокращения, хотя я полагал, что правило эквивалентности позволит обойтись без указанной трансформации. Один из существенный недостатков моего подхода заключается в том, что я рассматривал только достаточно простые примеры — типа (70). Сформулированные мной предложения не позволяют увидеть, как должны выводиться предложения типа
John burned a Confederate flag and then was arrested by officer Snopes. ‘Джон сжег знамя Конфедерации и был арестован офицером по имени Сноупс’.’
или Frank seems to know nothing and is easy to please.
‘Фрэнк, как кажется, ничего не знает и ему легко доставить удовольствие’.
Дело в том, что эти предложения содержат сочиненные группы, возникшие в результате применения трансформаций. Таким образом, трансформация сочинительного сокращения оказывается необходимой.
0 (К с. 273). Когда я писал это, я еще не понимал, что слишком вольное использование «признаков» в синтаксисе только мешает правильному пониманию реального положения дел. К счастью, у меня хватило здравого смысла, чтобы позже отвергнуть «признаковый подход» (см. «Постскриптум» к настоящей статье) и тем самым приблизиться к истине.
Р (К с. 275). Подобная запись имеет тот недостаток, что она создает ошибочное представление, будто формула имеет структуру типа X (X (. . .)) — наподобие формул с квантором V» см. выше. Более удачной была бы запись с одним квантором X, связывающим сразу любое число переменных.
8 (К с. 277). Катц и Постал в свое время видели возможность перформативного анализа: «Поскольку, с одной стороны, невозможны императивные высказывания типа *Want to gol ‘Хоти идти!* или *Норе to be famous! ‘Надейся быть знаменитым!*, а с другой — фразы типа *1 request that you want to go. ‘Я требую, чтобы ты хотел идти.* и *1 request that you hope to be famous. ‘Я требую, чтобы ты надеялся быть знаменитым.*, можно было бы считать, что все императивные конструкции выводятся из предложений вида:
IVERB gq iest you that you will MAIN-VERB ‘Я ЕЛкТОЛтребовать, чтоГы ты ГЛ. і О Л’ (Katz — Postal, 1964, p. 149). Хотя Катц и Постал указали ряд существенных преимуществ перформативного анализа по сравнению с использованием признака императива, они все же не приняли этот анализ, отметив только, что «он заслуживает дальнейшего исследования». Расхождение между аргументами в пользу перформативного анализа, выдвинутыми в Katz — Postal, 1964, и окончательно принятой Катцем и Посталом трактовкой императива заставляет думать о том, что между самими авторами существовали разногласия.
г (К с. 277). См. теперь S a d о с к, 1969; Ross, 1970; Rutherford, 1970.
5 (К с. 284). Позже я обнаружил и другие, вполне приличные идиомы этого типа, например: Keep your shirt cnf ‘He кипятись Г
* (К с. 289). Теперь мне кажется, что этот факт абсолютно несуществен.
и (К с. 290). По-видимому, внимательный читатель уже понял, что сказанное здесь означает отказ от сформулированного выше допущения, будто фразы типа (142) выводятся из конъюнктивно сочиненных структур. Мне следовало бы прямо сказать, что я отвергаю старый анализ в пользу нового.
v (К с. 291). Предложенная здесь трактовка имеет по крайней мере три серьезных недостатка:
(i) Неясно, как поступать в случаях, когда сочиняются не именные группы, а какие-либо иные составляющие, например: Mutt and Jeff are tall and short respectively. Букв. ‘Матт и Джефф—высокий и низкий соответственно*.
(ii) Неясно также, как быть с такими сочиненными группами, которые выводятся посредством трансформаций (см. примеры в примечании ", с. 272).
(iii) Неясно, как обеспечить правильный порядок однородных членов, то есть как, например, добиться того, чтобы в (145) получалась составляющая Магу and Alice, а не Alice and Магу. (Удивительно, что эту трудность заметил, по-видимому, один Постал. Позор всем прочим лингвистам!)
Что же касается того факта, что respective и respectively — это одна и та же единица, то это гораздо легче доказать, чем может показаться на первый взгляд. Для этого достаточно рассмотреть примеры фраз, в которых имеется более чем две сочиненные составляющие (или составляющие во множественном числе) и respective встречается наряду с respectively; см. мои статьи «The annotated respective» и «А program for logic» в сборнике М с С a w 1 е у, 1973, р. 121—132 и 285—319. Однако, как это показано во второй из названных статей, действительно адекватное описание лексемы respective(ly) требует гораздо более глубокого понимания сочинения, чем то, которого я достиг к моменту написания данной статьи, и даже чем то, которое есть у меня сейчас.
w (К с. 296). Эти два примера в действительности ничего не доказывают. Описанные здесь явления можно учесть с помощью соответствующих поверхностных ограничений, применяемых независимо от того, где именно производится интересующее нас лексическое заполнение.
I. БАЗИСНАЯ ТЕОРИЯ
Мне хотелось бы рассмотреть ряд вопросов, связанных с теорией грамматики. Я считаю, что грамматика языка — это система правил, которые устанавливают соответствие между звуками и смыслами, при этом и фонетическое и семантическое представления заданы некоторым способом, не зависящим от описываемого языка. Я считаю, что понятие «возможная поверхностная синтаксическая структура» для произвольного естественного языка определяется как дерево (или НС-структура), вершиной которого является
символ S, а узлы помечены символами из конечного набора: S, NP, V, . . . Понятие «дерева», или «НС-структуры», может быть определено одним из обычных способов с использованием таких терминов, как «предшествовать», «подчинять» или «быть помеченным». Тем самым грамматика определяет бесконечное множество поверхностных структур. Кроме того, я считаю, что грамматика включает систему грамматических трансформаций, отображающих НС-структуры друг в друга. Каждая трансформация определяет класс правильных пар упорядоченных НС-структур . Эти трансформации, или условия правильности к двум смежным НС-структурам Р[ и Р1 + 1, определяют бесконечный класс К конечных последовательностей НС-структур, причем каждая из последовательностей Pi, . . ., Р„ удовлетворяет следующим условиям:
(і) Р„— поверхностная структура;
(и) Каждая пара Pl( PU1 удовлетворяет условиям правильности, заданным трансформациями;
(iii) Не существует Р0 такой, что Р0, Pi, , . Ря удовлетворяет условиям (І) И (ІІ).
Элементы класса К называются синтаксическими структурами, порожденными грамматикой. Я считаю, что грамматика включает лексикон, то есть набор лексических единиц, снабженных фонологической, семантической и синтаксической информациями. Таким образом, предполагается следующее:
Лексическая трансформация, ассоциируемая с некоторой лексической единицей I, отображает НС- структуру Р, содержащую некоторую подструктуру Q, которая не содержит лексических единиц в НС-структуре Р\ полученной посредством замены Q на I.
Другими словами, лексическая трансформация — это условие правильности, накладываемое на пары НС-структур Рі и Рі+і> гДе Рі и Pi+i различаются только в одном отношении; там, где в структуре Pj находится подструктура Q, в структуре Р1+1 представлена соответствующая лексическая единица. Описанная схема может варьироваться в зависимости от того, в каком месте грамматики применяются лексические трансформации, применяются ли они в одном компоненте грамматики или в разных и т. п.
Можно считать, что трансформации, или условия правильности, накладываемые на пары НС-структур, выполняют «функции фильтров», блокирующих возможность преобразования НС-структуры Pj в НС-структуру Pi+1, если пара (Pi( Р1+1) не отвечает условиям правильности. Система трансформаций играет роль фильтра, который задает класс правильных последовательностей НС-структур, отсеивая все пары НС-структур, которые в каких-то отношениях нарушают условия правильности, или, другими словами, ни одна из них не получается из другой посредством трансформации. Поскольку трансформации определяют возможные преобразование только для упорядоченных пар НС-структур, я буду называть трансформации «локальными условиями на преобразования». Локальное условие на преобразование можно определить следующим образом. Пусть P/Ci — это НС-структура Р1( отвечающая условиям Сі. Трансформация, или локальное условие преобразования,— это пара вида (Р/Сх, Р1+1/С2), где С і и С2 — условия, задающие классы входных и выходных НС- структур соответственно. Предполагается следующее:
сх=с; и с; с2=с2 и с;
Сх = с2
СіфСГш
С(Ф означает отношение «иметь в качестве пресуппозиции». Тогда пресуппозицию можно изобразить следующим образом:
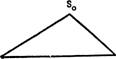
S.
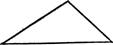
Здесь S2 является пресуппозицией S,. Во многих случаях, аналогичных рассмотренным выше, S2 не является пресуппозицией для So.
турно независимое от других компонентов смысла. Наш спо соб записи семантического представления отражает эту традиционную точку зрения; при этом наше дальнейшее изложение ни в коей мере не зависит от состоятельности этой точки зрения.
Я буду называть обрисованную выше теорию грамматики «базисной теорией», исходя исключительно из соображений удобства, отнюдь не имея в виду, что она действительно является базисной в каком бы то ни было аспекте — онтологическом, психологическом или концептуальном. Эта теория лежит в основе большинства работ по порождающей семантике начиная с 1967 г. Следует отметить, что по сравнению с предшествующими теориями порождающая семантика (в том виде, в каком она сформировалась к 1967 г.) допускает гораздо большую вариативность. Так, порождающая семантика не выдвигает требования использования трансформаций лексического заполнения структуры лишь в специальном компоненте, в котором трансформации других типов (нелексические) запрещены. Порождающая семантика оставляет свободу выбора решения вопроса о том, допустимо ли пересечение лексических и нелексических трансформаций.
Из сказанного выше должно быть очевидно, что базисная теория не включает требования «направленности преобразований» — ни от фонетики к семантике, ни от семантики к фонетике
Тем не менее отдельные высказывания некоторых специалистов по трансформационной грамматике могут создать у читателя ошибочное представление, что эти авторы принимают понятие направленности. Например, Хомский отмечает (Chomsky, 1971): «Свойства поверхностной
структуры играют важную роль в семантической интерпретации». Однако, как неоднократно указывает сам Хомский в этой же работе, понятие направленности преобразований не имеет смысла; поэтому приведенное выше высказывание Хомского следует трактовать как эквивалентное следующему: «Семантические представления играют важную роль при определении свойств поверхностной структуры». Оба эти высказывания можно заменить одним, более нейтральным: «Семантические представления и поверхностные структуры соотносимы друг с другом посредством системы правил». В базисной теории предусмотрено понятие трансформационного цикла (в смысле Chomsky, 1975): циклические правила применяются к НС-дереву последовательно «снизу вверх» — от самого «нижнего» символа S, затем к следующему символу S более высокого уровня и т. д. Мы считаем, что применение циклических трансформаций начинается с некоторой НС-структуры Рк и заканчивается на некоторой НС-структуре Рь где к
Еще по теме ПОСТСКРИПТУМ (МАЙ 1967 Г.):
- М.В.ПАНОВ. РУССКАЯ КІНЕТИКА. «ПРОСВЕЩЕНИЕ» МОСКВА-1967, 1967
- Постскриптум.
- ПОСТСКРИПТУМ
- Государство Израиль 1967—1976
- ДОПОЛНЕНИЕ (Май 2003 г.)
- В.В. ШКВАРКИН (1894-1967)
- 1967 Аутсайдер пушкинской эпохи
- 1967 О стихотворении М. Ю. Лермонтова "Парус"
- , 1992. С. 15. 8 Фасмер М. Этимологический словарь русского языка: В 4 т. М., 1967. Т. 2. С. 266; Шанский
- Конец Великогерманского рейха (апрель — май 1945)
- ДЕКАРТ - ЕЛИЗАВЕТЕ 29 [Эгмонд, май или июнь 1645 г.]
- НАЧАЛЬНЫЙ ЭТАП НАЦИОНАЛЬНОЙ РЕВОЛЮЦИИ (МАЙ 1925 г. - ИЮНЬ 1926 г.)
- §3. Характер американо-германских взаимоотношений в преддверии Второй мировой войны (май-август 1939 г.)
- Приложение 8. Законотворческая деятельность депутатов Государственной думы Ярославской области третьего созыва Второй этап анкетирования (март-май 2003 г.)
- Приложение 12. Сводные данные по количественным показателям эффективности работы общественных приемных депутатов Государственной думы Ярославской области третьего созыва Второй этап анкетирования (март-май 2003 г.)
- 5. Розвиток сімейного законодавства про шлюб та сім`ю в 1967-70-х рр. Кодекс про шлюб та сім`ю України 1969 р.
- Международное морское право 1973