КАК НУЖНО РАССУЖДАТЬ КОМПЬЮТЕРУ [†††††]
Введение: компьютер. Я предполагаю, что иногда должна использоваться четырехзначная логика. Следует подчеркнуть, что я употребляю слово «логика» в узком, старом его смысле: логика как органон, средство, критерий вывода.
Следует также учесть, что я употребляю слово «должен» в его прямом, нормативном значении.Мое предположение о полезности четырехзначной логики имеет локальный характер. Оно не является «большим требованием», согласно которому все всегда должны пользоваться этой логикой (в статье такое требование не комментируется), но является «малым требованием», утверждающим, что существуют обстоятельства, при которых некто — не вы — должен отказаться от обычной двузначной логики и использовать вместо нее другую. Для дальнейшего эти обстоятельства являются существенными.
Ситуация, которую я имею в виду, может быть описана следующим образом. Во-первых, проводящим рассуждение интеллектуальным устройством, которое должно использовать четырехзначную логику, является искусственный информационный процессор, т. е. (программированный) компьютер. Уже это первое предположение влечет за собой важное следствие. Иногда в качестве аргумента для сохранения классической двузначной логики выдвигается такой довод: двузначная логика является испытанной и апробированной, а это значит, что она обладает преимуществом привычности. С последним (хотя и не решающим) аргументом готовы согласиться те, кто, как и я, заинтересован в практическом применении логики. Он аналогичен принципу «минимального искажения» Куайна, хотя очень хотелось бы, чтобы эмоциональность тона, сопровождающая слово «привычность», прочно отложилась в памяти. При условии, что в данной ситуации в качестве рассуждающего устройства я рассматриваю компьютер, указанный аргумент не имеет силы. Понятие «привычное для компьютера» лишено смысла, и, разумеется, компьютеру безразлично, какая логика привычна для нас.
В свою очередь для программиста введение в компьютер необычной логики не затрудняет его работу. Вот и все, что я хотел сказать по поводу эмоционального освобождения от двузначной логики.Во-вторых, компьютер должен быть некоторой сложной вопросно-ответной системой определенного типа, причем под словом «сложная» я понимаю систему, которая, отвечая на вопросы, не ограничивается данными, содержащимися в ее памяти в явном виде, но может отвечать на вопросы, основываясь на заключениях, которые она составляет исходя из эксплицитно записанной информации. На сегодняшний день такие устройства как будто еще не созданы, но с ними связаны все наши надежды. Во всяком случае ясно, что коль скоро нет необходимости в рассуждении, вряд ли возникает потребность в логике.
В-третьих, имеется в виду, что компьютер получает информацию, на основе которой он делает заключения, из разных источников. Каждый из источников, возможно, вполне надежен, но ни один из них не может считаться эталоном из эталонов, универсально правдивым информатором. Легко представить себе по меньшей мере две картины. Одна описывает поведение компьютера в ситуации, когда множество людей, способных допускать ошибки, утверждают, что правильно, а что нет, или, что примерно одно и то же, когда один человек обеспечивает компьютер информацией в течение длительного времени. Другая картина изображает компьютер как часть сети искусственных интеллектуальных устройств, с которыми компьютер обменивается информацией. В любом случае существенно, что отсутствует единый, монолитный, безошибочный источник данных для компьютера — входные данные поступают в компьютер из нескольких независимых источников. В таких условиях проявляется типичная особенность информационной ситуации: угроза противоречивости информации. Элизабет, к примеру, сообщает компьютеру, что «Пираты» победили в Серии 1971 г., в то время как Сэм сообщает ему, что «Пираты» не победили. Что в таком случае должен делать компьютер?
Если компьютер является классическим двузначным логи* ком, он должен полностью отказаться сообщать что-либо о ком-либо или, что то же, должен сказать все обо всех..
Плодовитость противоречий в двузначной логике хорошо известна: они никогда не проявляются изолированно, лоиа? лизованно, а заражают всю систему. Конечно, компьютер мог бы отказаться принимать противоречивую информацию. Однако, во-первых, это было бы нечестно либо по отноше* нию к Элизабет, либо по отношению к Сэму, репутации которых являются, по предположению, почти безупречны* ми, и, во-вторых, не секрет, что противоречия могут быть не столь явными. В системе может оказаться необнаруженное противоречие, или, что еще хуже, противоречие, которое остается невыявленным еще долгое время после того, как введенная информация, породившая данное противоречие^: перемешалась с общей информацией, содержащейся в ком* пьютере, и потеряла свои индивидуальные признаки. При этом все же хотелось бы, чтобы компьютер выдавал только такие заключения, которые порождают разумные ответы на наши вопросы.Желательно, конечно, чтобы компьютер сообщал обо всех противоречиях, которые он обнаруживает, и поэтому совершенно нежелательно, чтобы он их игнорировал. Именно в тех случаях, когда существует возможность противоречивости, мы хотим, чтобы компьютер был способен продолжать вести рассуждения разумным способом, даже если имеется скрытое или обнаруженное противоречие. Даже если компьютер обнаружил и сообщил о противоречивости имеющейся в нем информации, например, о том, что в бейсбольном матче «Пираты» одновременно выиграли и проиграли в Серии 1971 г., было бы нежелательно, чтобы эта противоречивость отразилась при ответах компьютера на вопросы о расписании авиарейсов. Однако если компьютер является двузначным логиком, противоречие в информации о состязаниях по бейсболу заставит его собщить, что не-1 возможно добраться из Блумингтона в Чикаго, а также что ежедневно совершается ровно 3000 рейсов из города в город. Шапиро удачно назвал подобную ситуацию «загрязнением информации», так что я предлагаю сохранить чистоту нашей информации.
Таким образом, у нас есть практический довод в пользу рассмотрения ситуации, при которой компьютеру сообщается одновременно, что некое происшествие имело место
в действительности и что оно — выдумка (в одно и то же время, в одном и том же месте, при одних и тех же обстоятельствах и т.
д.).В обсуждаемой нами ситуации можно выделить еще один, четвертый аспект, значение которого мне не до конца понятно, но о котором тем не менее следует упомянуть для правильной оценки последующих рассуждений. Мой компьютер не является совершенным мыслящим устройством, которое, столкнувшись с противоречием, было бы способно сделать нечто большее, чем просто сообщить о его существовании. Совершенное устройство, по-видимому, должно обладать некоторой стратегией, с тем чтобы, обнаружив противоречивость своих представлений, иметь возможность отказаться от них. Так как я никогда не слышал о практической, разумной и чисто механической стратегии для пересмотра представлений при наличии противоречия, то вряд ли я виноват в том, что не снабдил свой компьютер такой стратегией. В то же время пока другие разрабатывают эту чрезвычайно важную проблему, мой компьютер может только устанавливать и сообщать о противоречиях, не устраняя их.
Этот четвертый аспект связан с пятым: на заданные вопросы компьютер должен отвечать строго в терминах полученного сообщения, а не в терминах информации, которая могла быть запрограммирована в нем с целью обеспечить большую эффективность его работы. Например, если компьютеру было сообщено, что «Пираты» выиграли и не выиграли в 1971 г., то компьютер именно так и должен ответить, хотя мы могли бы запрограммировать его для распознавания ложности подобных сообщений. Затронутая проблема и проста и сложна одновременно: если бы компьютер не сообщал о противоречиях в ответ на наши вопросы, мы не имели бы способа узнать о том, что в его базе содержится противоречивая информация. (Мы могли бы, если бы пожелали, запросить компьютер о выдаче нам дополнительного сообщения, например такого: «Мне было сказано, и что «Пираты» выиграли и что они не выиграли; но это, разумеется, неправильно». Однако будет ли такое сообщение полезным?)
Аппроксимационные решетки. Основным понятием настоящей работы является понятие аппроксимационной решетки, предложенное Д.
Скоттом [см., например, Скотт, 1970 — 1972]. Прежде чем продолжать, позвольте сказать о нем несколько слов. Вы будете разочарованы математическим определением аппроксимационной решетки: с мате^ матической точки зрения это не что иное, как полная решете ка; иными словами, это множество А, на котором задац частичный порядок JI, и такое, что для произвольного подмножества X множества А всегда существует наименьшая верхняя грань шХеА и наибольшая нижняя грань гпХеД(для двухэлементных подмножеств пишется XI іу И ХГ1у)#
Однако я не называю полную решетку аппроксимационной,: если она не отвечает следующему нематематическому требованию: для аппроксимационной решетки отношение xjly имеет смысл интерпретировать, как «х приближает у». При-f меры, приведенные Скоттом, содержат решетку «приближенных и переопределенных действительных чисел», при-; чем мы отождествляем приближенное действительное число с интервалом и считаем, что отношение xjly имеет место только в случае у^х. (Единственное) переопределенной действительное число является пустым множеством. В качестве другого примера Д. Скотт предлагает рассмотреть решетку «приближенных и переопределенных функций» из А в В, отождествляемых с подмножествами прямого произведения множеств Ах В. Здесь мы имеем fjlg только в случае, когда feg.
В таких решетках важными являются направленные (directed) множества, т. е. такие, у которых каждая пара элементов х и у имеет верхнюю грань z, также принадлежащую этому множеству. Каждое направленное множество можно представлять как приближенное посредством предельного перехода к своей сумме l_jX, т. е. если X *— направленное множество, то удобно представлять себе сумму і |Х как предел X. (Возрастающая последовательность
ХіЕ. . ..ЕхДІ . . . является частным случаем направленного множества.) Теперь, если обратиться к семейству функций, являющихся отображениями из одной аппроксимационной решетки в другую (или, разумеется, в ту же самую), то, как показал Д. Скотт, важными будут непрерывные функции, т.
е. функции, сохраняющие нетривиальные направленные суммы (т. е. f(i |Х) — і i{fx : хеХ} для всякогонепустого направленного множества X). Это единственные функции, которые сохраняют решетки в качестве аппрок- симационных. Предлагаемая идея столь фундаментальна, что я решил сформулировать ее в виде тезиса, подобно тезису Черча.
Тезис Скотта. При наличии полных решеток А и В, интуитивно воспринимаемых как аппроксимационные, обращайте внимание только на непрерывные функции из А в В, решительно пренебрегая всеми другими функциями, поскольку те нарушают структуру А и В как аппрок- симационных решеток.
Хотя честность вынуждает меня приписать данный тезис Скотту, она же заставляет меня заметить, что формулировка тезиса — моя собственная и что в такой формулировке он может не понравиться Д. Скотту, который, возможно, сочтет более важным другой тезис, сформулированный в том же духе; например, тезис о том, что каждая аппроксимаци- онная решетка (в интуитивном смысле) является непрерывной (в смысле Д. Скотта, [1972]).
В последующем изложении будет видно, в какой мере я опираюсь на тезис Скотта.
Программа. Дальнейший материал этой статьи делится на три части. В части I описывается ситуация, когда компьютер воспринимает только атомарную информацию. Это сильное ограничение, но оно порождает сравнительно простую ситуацию, в которой удобно развить некоторые ключевые идеи. В части II компьютеру разрешается воспринимать информацию, выраженную функционально составными предложениями. В этом случае я предлагаю в качестве нового типа значений некоторых формул отображения эписте- мических состояний в эпистемическиесостояния. В части III компьютеру разрешено также воспринимать импликации, рассматриваемые как правила для улучшения базы данных.
Часть I. Атомарные входные данные
Атомарные предложения и аппроксимационная решетка А4. Здесь и далее мы должны хорошо помнить обстоятельства, в которых оказывается компьютер, и в особенности тот факт, что последний должен быть готов к восприятию и рассмотрению противоречивой информации. Я хочу предложить некоторую естественную технику, которой удобно пользоваться в таких случаях, а именно, когда какая-либо единица поступает на вход как подтверждаемое сообщение, отмечать ее символом «говорит Истину», а когда единица поступает как отвергаемая, отмечать ее символом «говорит Ложь», рассматривая оба высказывания как совершенно равноправные. Легко видеть, что это приводит к четырец,|; возможностям. Каждую единицу информации в массивlt;$|| базы данных компьютер стремится хранить отмеченном одним из следующих четырех способов: 1) только символош! «говорит Истину», показывая тем самым, что сообщрцщД было подтверждено и никогда не было отвергнуто; 2) толькд I символом «говорит Ложь», показывая тем самым, что соо(ь ’ щение было отвергнуто и никогда не подтверждалось! *. 3) символа «говорит» вообще нет; это означает, что компыо»: тер находится в неведении относительно истинностного значения сообщения, ему ничего не было сообщено; 4) ин»ч тересный случай: сообщение может быть помечено одновро* менно и значком «говорит Истину», и значком «говорит ? Ложь». (Напомним, что допущение этого случая представ» ляется практически необходимым, поскольку человек мо* жет ошибаться.)
Эти четыре возможности представляют собой в точности четыре значения многозначной логики, которую я предлагаю компьютеру в качестве практического руководства в рас* суждениях. Дадим этим значениям имена:
Т — «говорит только Истину»;
F — «говорит только Ложь»,
None — «не говорит ни Истины, ни Лжи»;
Both — «говорит и Истину, и Ложь».
Итак, у нас имеется четыре значения, отмеченные как 4= {Т, F, None, Both). Разумеется, эти значения еще не составляют логики, но давайте посмотрим, что мы теперь имеем.
Наше предположение требует, чтобы система, использующая четырехзначную логику, кодировала каждое атомарное предложение, представленное в ее базе данных, вместе с указанием на то, какое из четырех значений это предложение имеет на данном этапе. Отсюда следует, что компьютер не может задать некоторый класс простым перечислением его элементов, предполагая, что неперечислен* ные элементы не принадлежат данному классу. Действительно, поскольку имеется четыре значения, то существует четыре функциональных состояния каждого элемента: компьютеру может быть не сообщено ни одного, а может быть сообщено одно или каждое из утверждений «в классе» И «не в классе». Сами собой возникают две процедуры. Первая должна помечать каждое из сообщений одним из значений Т, F или Both, если про них компьютеру нечто
сообщается, и отмечать отсутствующие сообщения в списке значением None, если у компьютера отсутствует какая- либо информация о данном сообщении. Вторая процедура должна перечислять каждую единицу с одним или двумя значениями «говорит» — «говорит Истину» и «говорит Ложь» не перечисляя элементов, для которых отсутствуют оба значения «говорит». Очевидно, что указанные процедуры эквивалентны, и потому в нашем изложении мы не будем проводить различия между ними, а будем применять одну или другую, когда это окажется удобным.
Та же процедура используется для отношений, однако в последнем случае отмечаются упорядоченные пары. Например, фрагмент корректной таблицы, указывающей победителей Серий и понимаемой как запись отношения между командами и годами, может выглядеть так:
(«Пираты», 1971) Т или («Пираты», 1971) Истина;
(«Ориолес», 1971) F или («Ориолес», 1971) Ложь Однако если Сэм ошибся и дал неправильную информацию после того, как Элизабет уже записала верхнее сообщение, то первая строчка таблицы превратится в
(«Пираты», 1971) Both или («Пираты», 1971) Истина, Ложь.
Чтобы быть точными, будем считать (в этой части статьи), что эпистемическое состояние компьютера формулируется на языке таблицы, где каждому атомарному предложению (прим. 9) приписано одно из четырех значений. Назовем такую таблицу cemati (следуя аналогичному словоупотреблению Р. и В. Раутли [1972]). Говоря формально, сетап является отображением атомарных предложений в множество 4= ~{Т, F, None, Both}. Когда атомарная формула поступает в компьютер как подтверждаемая или отвергаемая, последний изменяет свой наличный сетап, добавляя соответственно символы «говорит Истину» или «говорит Ложь». Компьютер не уничтожает ничего из уже имеющейся информации, и в этом заключается основное достоинство нашего предложения. Другими словами, если сообщение р подтверждается, компьютер отмечает р посредством Т в случае, когда р ранее было отмечено посредством None, и посредством Both в случае, когда р ранее было отмечено посредством F, и, конечно, он оставляет все без изменения, если р уже было отмечено посредством Т, либо посредством Both. На этом мы закончим обсуждение входных сообщений.
Наш компьютер не только принимает информацию на входе, но и отвечает на вопросы. Рассмотрим лишь одно основное соотношение для р, а именно: компьютер отвечает на вопросы одним из следующих четырех способов — «Да», «Нет», «Да и Нет» или «Мне неизвестно», в соответствии со значением р в своем наличном сетапе — Т, F Both щщ None. (Неверно думать, что эти четыре ответа определяются лишь четырехзначной логикой и исключаются при двузначной логике; просто в четырехзначном случае они становятся; более плодотворными [см.: Белнап, 1964; Белнап и Стил, 1975].)
Предупреждение или, как говорит Н. Бурбаки, «опасный поворот» (~): знак «говорит Истину» неэквивалентен Тч Отношения здесь, скорее, следующие. Во-первых, компьютеру говорят «Истина» о некотором предложении А только в случае, когда компьютер отметил А либо посредством 7\ либо посредством Both. Во-вторых, компьютер отмечает А посредством Т только в случае, когда А было сообщено ему как «Истина» и не было сообщено как «Ложь». Аналогичной отношение имеет место между F и «говорит Ложь». Эти отношения вполне очевидны, но на практике приводят к путанице. Пожалуй, лучше всегда читать «говорит Истину» как «по меньшей мере говорит Истину», и Т — как «говорит только Истину».
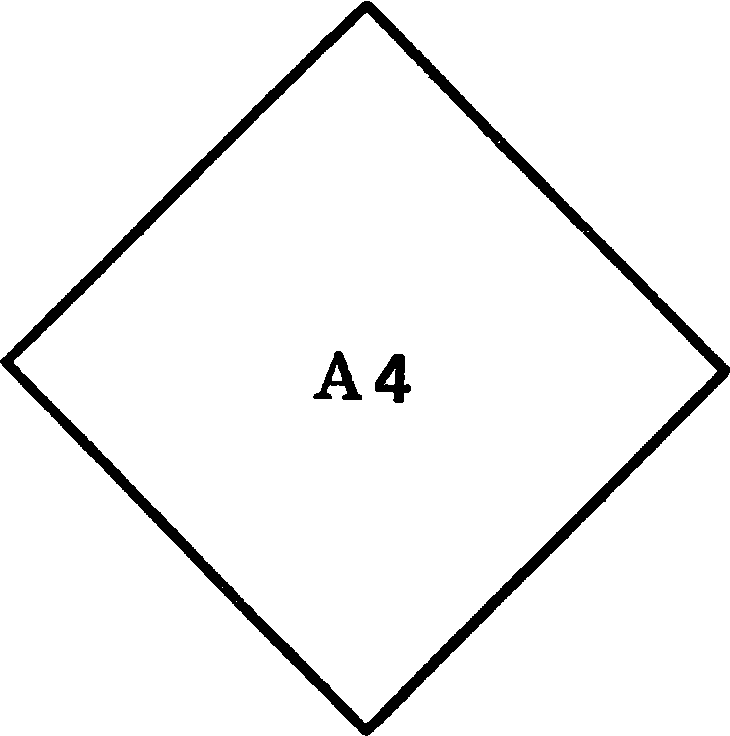
Теперь я хочу сделать очень важное для дальнейшего изложения замечание: введенные четыре значения образуют решетку с отношением порядка «приближает информацию», а в действительности аппроксимационную решетку в указанном выше смысле.
Both
None
Рис. 1 Аппроксимационная решетка А4.
(В этой диаграмме Хассе объединениями (lj) и пересечениями (гл) являются наименьшие верхние и наибольшие нижние грани соответственно, a L повышает значение. Norte является нижней точкой, так как вообще не дает никакой информации. Both является вершиной, так как дает слишком противоречивую информацию, предлагая рассматривать отмеченное этим символом предложение и как «Истину, и как «Ложь».) Как уже отмечалось, Д. Скотт изучал аппроксимационные решетки детально и в более интересном случае, и все же эта небольшая четырехэлементная решетка очень существенна для большей части его работы. Отмечалось также, что в соответствии с тезисом Скотта важными для аппроксимационных решеток типа А4 являются непрерывные функции. К счастью, мы пока не имеем дела с непрерывностью, поскольку в конечном случае- для функции быть непрерывной — то же самое, 4TQ быть монотонной, т. е. сохранять структурный порядок: a Jib влечет fajlfb.Предположим, к примеру, что функция g на А4 принимает значение Т в F и Fb Т: g(7)^F, g(F)=T. Тогда, поскольку g — монотонна, a TLBoth, имеем 7Tg (Both) и аналогично TLg(Both). Отсюда g(Both)=Both. Подобным образом легко посчитать, что если g — монотонна (как все хорошие функции), то g (None)=Norte.
Составные предложения и логическая решетка L4. Теперь функция g не будет просто примером монотонной функции на решетке А4 приближаемых и противоречивых истинностных значений. Фактически она представляет собой отрицание, которое порой называют «первородным грехом логики», но, если мы хотим иметь достаточно богатый язык, что необходимо нашему компьютеру, чтобы тот мог отвечать на простые да-/*ет-вопросы. Для того чтобы понять, почему g действительно является отрицанием, заметим, что значения Т и F, представляющие простой случай, должны быть подобны обычным истинностным значениям «Истина» и «Ложь», поскольку мы, разумеется, хотим, чтобы выполнялись соотношения ~ T=F и ~ F=7\ Теперь же тезис Скотта предоставляет нам единственное решение задачи продолжения отрицания до значений на другой паре элементов. Если отрицание есть хорошая монотонная функция на ап- проксимационной решетке А4, то мы должны иметь ~ No- ne=None и ~ Both=Both.
Суммируем наши рассуждения об отрицании, представив результат в виде таблицы:
|
| None | F | T | Both |
|
| m | tt | tt | m |
|
| None | T | F | Both |
Здесь «tt» в верхнем углу означает, что значение было получено в соответствии с обычной таблицей истинности, в то время как «т» указывает на то, что для получения данного значения пришлось привлечь монотонность. 1
Определив отрицание, перейдем к конъюнкции и дизъ^
Гнкции. Начнем построение истинностной таблицы для них ее Т—F части, а затем привлечем монотонность (по каждо-
| amp; | None | F | T | Both |
| None | m None |
| m None |
|
| F |
| tt F | tt F |
|
| T | m None | tt F | tt T | m Both |
| Both |
|
| m Both | m Both |
| V | None | F | T | Both |
| None | m None | m None |
|
|
| F | m None | tt F | tt T | m Both |
| T |
| tt T | tt T |
|
| Both |
| m Both |
| m Both |
му аргументному месту) и, основываясь на некоторых простых соображениях, продолжим значения, как указано.
Пользуясь только обычными истинностными таблицами и монотонностью, нельзя однозначно, в отличие от отрицания, задать конъюнкцию и дизъюнкцию. Конечно, можно было бы применить некоторые ухищрения, опираясь на интуицию, но здесь нам не хотелось бы поступать таким образом. Лучше, по-видимому, попытаться понять, как далеко можно зайти, оставаясь в рамках чистой теории.
Оказывается, стоит только потребовать, чтобы конъюнкция и дизъюнкция были связаны друг с другом некоторым отношением минимальности, как каждая клетка будет определена однозначно. Здесь можно пойти несколькими возможными путями. Мы выберем путь, равноправный со всеми другими, согласно которому ограничения, стандартно устанавливаемые связками amp; и V, одни и те же.
Это означает, что верны следующие эквивалентности:
аamp;Ь = а тогда и только тогда, когда аVb=b;
aamp;b=b тогда и только тогда, когда а\/Ъ = а.
В самом деле, посмотрим на частично заполненную таблицу для конъюнкции. Мы видим, что Т является единичным элементом: аamp;Т=а для всех а. Таким образом, если конъюнкция и дизъюнкция соответствуют друг другу (как это и должно быть), мы имеем Т=а V 7" для всех а, при этом заполняются две клетки в V -таблице. С помощью подобных рас- суждений заполняется вся таблица, кроме угловых клеток.
Для заполнения угловых клеток мы должны привлечь монотонность (но только после рассмотрения структуры
| amp; | None | F | T | Both |
| None | None | f F | None | m F |
| F | f F | F | F | f F |
| Т | None | F | T | Both |
| Both | m F | f F | Both | Both |
решетки). Например, поскольку FLBoth, по монотонности получаем (Famp;None) С. (Both 8с None), так что F JI (Bothamp;c None). Аналогично None JC F приводит к (Bothamp;None) Z (Bothamp;F), т. e. (BothScNone)LF. Таким образом, из антисимметрии в А4 получаем (Both8cNone)=F. Этиадо- полнительные результаты в сочетании с предыдущими можно свести в следующие таблицы, где «Ї» указывает на использование приведенного выше соотношения между amp; И V* а «т» снова указывает на монотонность.
| V | None | F | T | Both |
| None | None | None | f T | m T |
| Т | None | F | T | Both |
| Т | f T | T | T | f T |
| Both | m T | Both | f T | Both |
Не знаю, удивительно это или нет, но обе таблицы определяют решетку с конъюнкцией в виде пересечения и дизъюнкцией в виде суммы. Эта решетка может быть изображена следующим образом:
т
)
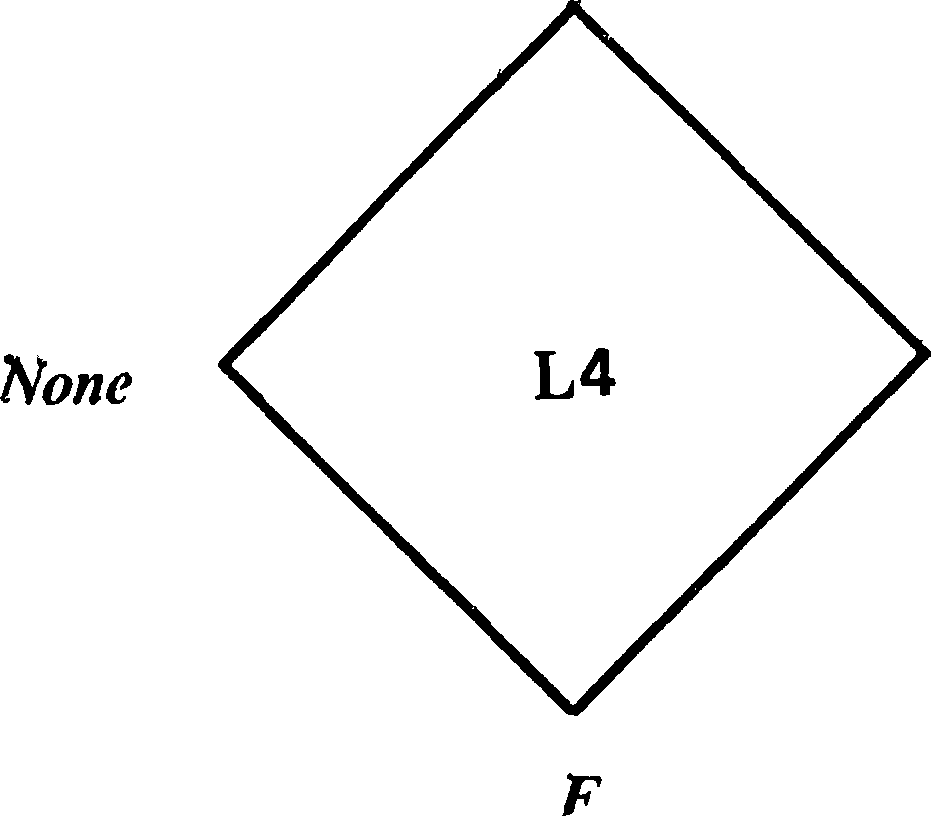
Рис. 2. Логическая решетка L 4.
Условимся называть эту логическую решетку L4, с тем чтобы отличать ее от аппроксимационной решетки А4. Порядок на L4 запишем как а^Ь, пересечение в виде аamp;Ь, а сумму как а V b. Заметим, что в логической решетке оба значения F и Г расположены между None и Both. Это естественно, ибо, как известно, самое худшее сказать о чем-либо, что это — выдумка. Вы предпочтете, по-видимому, совсем ничего не говорить или сказать, что сообщение истинно и в то же время ложно; тогда как лучше всего, разумеется, сказать, что оно — истинно, и не мутить воду. Несомненно, однако, что большинство из вас будет озадачено, если вы посмотрите на правила конъюнкции и дизъюнкции для None и Both : Noneamp;Both=F, a NoneVBoth = T. Теперь прошу только обратить внимание на тот факт, что мы пришли к этим равенствам с помощью всего лишь трех соображений: таблиц истинности для двузначной логики, монотонности и соответствия между amp; и V- Мне придется, однако, еще немного порассуждать на эту тему.
Воспользуемся теперь логическими операциями на L4, чтобы ввести вполне обычным образом семантику для языка, содержащего amp;, V и^. Для произвольного сетапа s, т. е., напомним, для отображения атомарных формул в 4, можно продолжить s обычным индуктивным образом до отображения всех формул в 4 (прим. 10):
s(A amp; В) = s (А) amp; s (В)у s (AVВ) = s (A)Vs (В), s(~ A) = ~s(A).
Это подсказывает нам, как компьютер должен отвечать на вопросы о сложных формулах, основанных на сетапном представлении эпистемического состояния компьютера (то, что было сообщено). Так же как при ответе на вопросы об атомарных формулах, компьютер должен на вопрос относительно А отвечать «Да», «Нет», «Да и Нет» или «Мне неизвестно», в соответствии с тем, будет ли значение А в s (т. е. s(A)) равно Т, F, Both или None.
Приведенные рассуждения, вероятно, показались вам абстрактно-теоретическими, поэтому теперь я хотел бы заняться исследованием отрицания, конъюнкции и дизъюнкции совсем с другой, более интуитивной точки зрения. Вопрос, к которому я собираюсь обратиться, состоит в следующем: если исходить из интуитивного понимания смысла четырех истинностных значений, отмечающих предложения, то как распространить эти значения на составные предложения, при условии, что мы знаем значения их составных частей? Для начала займемся отрицанием.
Придется, кажется, с неизбежностью признать, что ~А должно быть отмечено как «Истина» только в том случае, когда А отмечено как «Ложь», и, наоборот, должно быть отмечено как «Ложь» только в том случае, когда А отмечено как «Истина». Другими словами, ~А должно быть отмечено как по «меньшей мере Истина» только в том случае, когда А отмечено как «по меньшей мере Ложь», и как «по меньшей мере Ложь» только в том случае, когда А отмечено как «по меньшей мере Истина». Рассмотрим теперь соответствующие соотношения:
None — не отмечено никаким символом;
F — отмечено только как «Ложь»;
Т — отмечено только как «Истина»;
Both — отмечено обоими знаками.
Сразу выясняется, что мы должны отметить ~А как Both, если А отмечено Both, и как None, если А отмечено Nonegt; и как Т или F, если А отмечено соответственно как F или 7. Например, если А отмечено None, т. е. не отмечено как «Истина» или как «Ложь», то ~Л также не должно быть отмечено никаким знаком. Если вы ничего не знаете об Л, то вы ничего не знаете и о ~А. Те же соображения верны и для Both: если вы знаете слишком много об Л, то вы также слишком много знаете и о ~А.
Подобным же образом можно сформулировать следующие интуитивные условия для оценки конъюнкции и дизъюнкции.
Отметить (Аamp;В) как «по меньшей мере Ложь» только в случае, когда по меньшей мере одно из предложений А и В отмечено как «по меньшей мере Ложь».
Отметить (Аamp;В) как «по меньшей мере Истина» только в случае, когда оба предложения Л и В отмечены как «по меньшей мере Истина».
Сформулированные условия полностью определяют, как отмечать конъюнкции.
Отметить (A \J В) как «по меньшей мере Истина» только в случае, когда по меньшей мере одно из предложений Л и В отмечено как «по меньшей мере Истина».
Отметить (АуВ) как «по меньшей мере Ложь» только в случае, когда оба предложения А и В отмечены как «по меньшей мере Ложь».
Эти условия вполне однозначно определяют дизъюнкцию, обеспечивая интуитивное соответствие между нашими четырьмя значениями None, Ft Тgt; Both, с одной стороны, и отметками посредством ни одного, одного или обоих знаков «Истина» и «Ложь» — с другой. Более того, такая интуитивная оценка строго согласуется с теоретически обоснованной оценкой, полученной с помощью аппроксимационных решеток Скотта. Рассмотрим, например, одну из свободных угловых клеток Both amp; None=F. Предположим теперь, что А отмечено как «Истина» и «Ложь» одновременно, а В не отмечено никаким знаком (что соответствует Both и None). Тогда мы должны отметить (Аamp;В) как «по меньшей мере Ложь», так как один из членов конъюнкции имеет значение «по меньшей мере Ложь». Мы не должны отмечать это предложение как «по меньшей мере Истина», так как оба его члена не отмечены таким образом. Следовательно, мы должны отметить предложение только как «Ложь»; итак, Bothamp;c None=F. Другими словами, более неформально, в этой ситуации компьютер имеет основание предполагать, что (Аamp;В) сообщает ложное предложение, но никак не предполагает, что это предложение сообщает «Истину». Таким образом, хотя равенство Bothamp;None = F остается удивительным, оно получило некоторое объяснение.
Следствие и вывод: четырехзначная логика. Чего же мы все-таки достигли? Мы еще не получили логику, поскольку еще не имеем правил для порождения и оценки выводов. (В нашем случае мы действительно хотим построить некоторые правила, которые компьютер сможет использовать для порождения того, что он знает неявно, из того, что ему известно явно.) Все, что у нас пока есть,— это четыре интересных значения с указаниями относительно того, как дружественный компьютер должен ими пользоваться, а также три прекрасные связки с полными и обоснованными таблицами для каждой из них. Как известно, множество других связок может быть выражено посредством уже определенных, так что для наших целей этих трех связок вполне достаточно.
Предположим теперь, что имеется высказывание, содержащее наши связки. Вопрос состоит в том, когда его можно считать хорошим. Снова дадим абстрактно-теоретический, а затем интуитивный ответ. (И если будет достаточно времени, еще несколько ответов, ибо действительно вопрос этот чрезвычайно интересен.)
Абстрактный ответ основан на логической решетке, которую мы столь долго обсуждали. Он состоит в том, что следование повышает значение. Другими словами, пусть А и В — произвольные предложения (составленные из переменных посредством отрицания, конъюнкции и дизъюнкции). Будем говорить, что А влечет, или имплицирует, В, если для каждого приписывания одного из четырех значений переменным значение А не превосходит (меньше или равно) значения В. Символически s(A) ^ s(B) для каждого сетапа s. Мы получили корректное определение следования, так как у нас есть решетка значений, которую можно считать как бы градуированной снизу вверх, и, как я предлагал ранее, когда впервые знакомил вас с логической решеткой, вполне можно считать, что None и Both расположены между ужасным F и чудесным Т.
Теперь дадим неформальную оценку понятия вывода, которая будет напоминать неформальные рассуждения, лежащие в основе наших представлений о четырех значениях, задача которых следить за отметками «Истина» и «Ложь». Будем говорить, что вывод В из А общезначим или что А влечет В, если этот вывод никогда не приводит нас от «Истины» к ее отсутствию (т. е. сохраняет истинность), а также никогда не приводит нас от отсутствия «Лжи» к «Лжи» (т. е. сохраняет не-ложность). Выдвигать подобные требования при данной системе отметок вряд ли означает требовать слишком много.
(Заметим, что Дж. Данн [1975] показал, что достаточно рассматривать сохранение истинности, так как если некоторый вывод не всегда сохраняет не-ложность, то, как это может быть показано с помощью несложных технических приемов, он также не может сохранить истинность. Для этого достаточно взять оценку пропозициональных переменных с взаимной заменой Both и None, оставляя без изменений Т и F, и показать, что значение любого составного предложения изменяется таким же образом. Я, однако, согласен, по существу, с замечанием Данна, который предполагает, что «Ложь» действительно во всем аналогична «Истине», так что совершенно естественно установить нашу оценку «общезначимости» или «приемлемости» вывода способом, нейтральным по отношению к этим двум истинностным значениям.)
Наконец, у нас есть логика, т. е. критерий вывода, который использует наш компьютер, чтобы производить выводы, содержащие конъюнкцию, дизъюнкцию и отрицание, а также, конечно, все, что может быть выражено посредством этих связок. Замечу, что эта логика имеет два основных свойства. Во-первых, что наиболее важно, она корнями уходит в практику. Мы уже объясняли, почему было бы хорошо, чтобы наш компьютер рассуждал в терминах четырех значений, и почему логика четырех значений должна быть такой, как она есть. Во-вторых, хотя отдельные шероховатости еще остались, очевидно, что наша оценка общезначимости вывода является математически строгой. Очевидно также, что компьютер, осуществляя вычисления в соответствии с таблицами истинности, может решать, является ли предложенный вывод общезначимым. Существует, однако, другая сторона деятельности логика, заключающаяся в кодифицировании выводов аксиоматическим или полу- аксиоматическим способом, с тем чтобы вывод стал явным и соответственно удобным. Если вывод продолжает казаться таинственным, он неудобен. Этим я хочу сказать, что логик, задавая семантику, стремится, как правило, снабдить ее теорией доказательств, теорией, которая является непротиворечивой и полностью соответствует семантике.
В течение некоторого времени мы занимались такого рода логической деятельностью, хотя вначале возникла теория доказательств и лишь впоследствии — семантика. История вопроса примерно такова. Довольно давно, в 1962 г., А. Андерсон И Я ПреДЛОЖИЛИ раССМОТреТЬ Группу ВЫВОДОВ, КОТО' рые мы назвали тавтологическими следствиями, т. е. группу, включающую в себя все разумные выводы (содержащие связки amp;, V, ~)» которые всякий психически нормальный и достаточно тренированный логик хотел бы сделать. Мы построили различные формализации этих выводов в виде теории доказательств и показали, что восьмизначная матрица достаточна для того, чтобы охарактеризовать эти выводы семантически.
Позже Т. Дж. Смайли сообщил (в письме к нам), что некоторая четырехзначная матрица способна выполнить ту же самую работу, и этими значениями были в точности те, что я предложил в настоящей работе, хотя Смайли использовал числа вместо придуманных нами имен. Именно тогда я узнал о четырех значениях. Смайли, конечно, рассматри- вал свой результат как чисто технический, а не как логиче» ский (в том понимании слова «логический», которое принято в настоящей работе).
Спустя некоторое время Дж. Данн предложил различные семантики для тавтологических следствий [1966], некоторые из которых интуитивные, а некоторые тесно связаны с четырехзначной матрицей Смайли. Данну принадлежит также одна из основных идей, разработкой которых я занимался, а именно отождествление четырех значений с четырьмя подмножествами множества {«Истина», «Ложь»}. В 1975 г. (с некоторым опозданием) Данн уделил в своей работе много внимания интуитивному и техническому значению этой идеи. Другие семантики для тавтологических следствий вместе с интуитивными доводами в пользу их применения были предложены ван Фраассеном [1966], а также Р. и В. Ра- утли [1972]. Алгебраическая структура, соответствующая этой логике, была детально исследована Данном и другими? весь этот материал изложен Данном в главе III книги Ан-* дерсона, Белнапа [1975], где можно также найти генце- новские исчисления и многие другие близкие вопросы (прим. 11).
Мой собственный более глубокий интерес к такой логике и мысль о том, что, быть может, она имеет приложение для компьютера, возникли, частично совпадая по времени, вслед за работой Д. Скотта в Оксфорде в 1970 г., где он был гостем Стрэчи, которому мы приносим, к нашему глубокому сожалению уже после его смерти, благодарность. В работе Скотта четыре значения появились как аппроксимационная решетка, имеющая важное значение, и нетрудно было увидеть их связь с четырьмя значениями Смайли. Осознание важности эпистемической интерпретации пришло совсем недавно.
Независимо С. Шапиро продемонстрировал полезность «релевантных логик» для вопросно-ответных систем и предложил пути реализации соответствующего плана исследоцаї ний [см. Шапиро и Ванд, 1975] (прим 12).
Довольно об истории вопроса. Позвольте теперь кратко сформулировать некоторые семантически общезначимые, а если их собрать воедино, то и семантически полные логические законы. Эта группа логических равносильностей будет избыточной, т. е. будет содержать ряд лишних формул, но напомним читателю, что это обычная плата за удобства»
Я предлагаю компьютеру некоторый набор законов, которые тот может использовать для своих выводов.
Пусть А, В ит. д.— формулы с amp;, V и ~. Пусть А-*В означает, что вывод В из А общезначим при наших четырех значениях, т. е. что А влечет В. Пусть также АФВ означает, что А и В семантически эквивалентны и могут быть вза- имозаменимы в любом контексте. Тогда приводимые ниже формулы составляют полезный (полный) набор логических законов.
А{amp; ... amp;Ап-+В1У ... уВп
при условии, что некоторое А і совпадает с некоторым Ву (условие вхождения);
(АуВ)-^С т. и т. т. (тогда и только тогда), когда А —gt;¦ С и В—*-С\
А Вamp;С т. и т. т., когда А-+В и Л-gt;С;
А-^В т. ит. т., когда ~В-gt;-~А\
AyB^zByA Лamp;В^Вamp;Л;
Ау(ВуС) Ф (АуВ)уС (Аamp;В)amp;С^ Аamp;(Вamp;С); Аamp;(ВуС) Ф (Аamp;В)у(Аamp;С) Ay (Вamp;С) ^ (A\JB)amp; amp;(Ау С)\
(ВуС)amp;А ^ (Вamp;А)у(Сamp;А) (Вamp;С) у А ^ (ВуА)amp; amp;(СУА);
~ ~ Л Ф Л;
~(Аamp;В) Ф ~Ау~В ~ (А У В) ~У~Аamp;~В\
если А-+В и В—*~С, то А-+С;
если А У В и В Ф С, то А Ф С;
Л-gt;В, если Л (Аamp;В) т. и т. т., когда (АуВ) Ф В.
Замечания. Теперь, прежде чем идти дальше, необходимо сделать некоторые замечания. Во-первых, отмечу, что невыводимыми из предлагаемых законов и семантически незначимыми являются парадоксы «импликации» Лamp;^Л В и А Ву~В. В данном контексте нарушение этих логических законов очевидно. Нарушение первого означает просто следующее: если нам одновременно сообщают, что Л — «Истина» и что Л — «Ложь», мы не можем только на основании этого судить обо всем. Действительно, нам может быть ничего не известно о В или известно, что В есть «Ложь». Столь же очевидно нарушение второго закона. Из того факта, что нам сообщили, что Л — «Истина», нельзя сделать вывод, что нам известно что-либо о В. Конечно, онтологически В есть либо «Истина», либо «Ложь», и таким онтологическим истинностным значениям будет уделено должное внимание. Однако для того, чтобы отметить формулу B\J~B как «Истина», нужно либо чтобы В было отмечено как «Истина», либо чтобы В было отмечено как «Ложь», но ведь В может быть никак не отмечено. При другом способе построения контрпримера для А В\/~В можно придать А только значение «Истина», в то время как (B\J~B) будет принимать два значения, потому что два значения может принимать В.
Противоречивые выводы нежелательны в схеме, которая предназначена выдерживать противоречия; коль скоро противоречия представляют собой при описанных нами обстоятельствах реальную угрозу системе, их отсутствие можно только приветствовать.
Я был бы не слишком откровенен, если бы не указал на отсутствие закона, который на первый взгляд кажется более безобидным: (АуВ) amp;~А -gt; В. Можно, конечно, предполагать, что наш компьютер должен быть в состоянии рассудить, что если одно из предложений А и В истинно и это не А, то это должно быть В. Все это верно, и тем не менее (несомненно, что это существенное «тем не менее») здесь недалеко до противоречия. Фактически этот закон допускает следующий вывод:
(А V#) amp; ~А (А amp; ~ А)\/В.
Поэтому, полагая, что антецедент есть «по меньшей мере Истина», мы позволяем компьютеру сделать вывод, что либо В есть «по меньшей мере Истина», либо происходит нечто забавное, а именно: сообщается, что А есть «Истина» и «Ложь» одновременно. В этом-то все и дело. Если причина, по которой (А\/В) amp;~А считается «Истиной», состоит в том, что А отмечено как «Истина» и как «Ложь» одновременно, то мы, разумеется, не хотим продолжать вывод, получая В. Этот вывод совершенно непригоден в ситуации, где противоречивость является реальной возможностью.
Второе замечание касается того, что наши четыре значения были предложены только в связи с выводами и мы, безусловно, не предполагали использовать их для определения того, какие формулы со связками amp;, V и ~ рассматриваются в качестве, так сказать, логических истин. Фактически ни одна формула не принимает всегда значение 7\ и, Следовательно, это свойство не может служить семантиче- ской оценкой логической истины. Существуют, с другой стороны, формулы, которые никогда не принимают значения F, например А \/~А, но множество таких формул даже не замкнуто относительно конъюнкции и не содержит формулы (A \J~A) amp;(B\J ~В), которая может иметь значение F, когда А принимает значение None, а В — значение Both. Таким образом, не стоит и пытаться определить логическую истину по нашим четырем значениям.
В-третьих, рассмотрим онтологию versus эпистемологии. Одна из трудностей, которая часто возникает при попытках применить многозначные логики к реальным практическим задачам, заключается в постоянном смешении онтологического и эпистемологического понимания различных значений. Так, среднее значение Лукасевича, 1/2, употребляется в смысле «не имеет точного истинностного значения» или в смысле «истинностное значение неизвестно». При неформальных истолкованиях отдельных рассуждений, чтобы не пропадал интерес к его работе, логик частенько переходит от онтологического понимания значений к эпистеми- ческому и наоборот. Введенные мною четыре значения явно эпистемические: предложения отмечаются как Т, F, None или Both в зависимости от того, что было сообщено нашему компьютеру, или, говоря слегка метафорически, в зависимости от того, что он думает и знает. Разве отсюда следует, что мы не занимались логикой? Нет, не следует. Конечно, эти предложения имеют истинностные значения независимо от того, что сообщается компьютеру. Кто, однако, станет отрицать, что компьютер не в состоянии использовать действительные истинностные значения предложений, в которых он заинтересован? Все, что, по-видимому, компьютер может использовать в качестве основы для вывода,— это то, что он знает и считает, т. е. то, что ему было сообщено.
Но мы можем поступить еще лучше. Введем онтологию посредством расщепления наших четырех эпистемических значений на два: одно будет соответствовать случаю, когда предложение онтологически истинно, а другое — случаю, когда предложение онтологически ложно. Очевидно, что мы получим теперь восемь значений вместо четырех, каждое из которых представлено в виде упорядоченной пары, левад часть которой есть эпистемическое значение Т, F, None или Both, а правая содержит одно из онтологических значений Фреге: «Истина» и «Ложь». Используя обычные, дву-
значные, классические таблицы для связок и интерпретируя обычным образом импликацию, мы приходим к следующему изображению решетки (причем не аппроксимационной):
(Г, Истина)
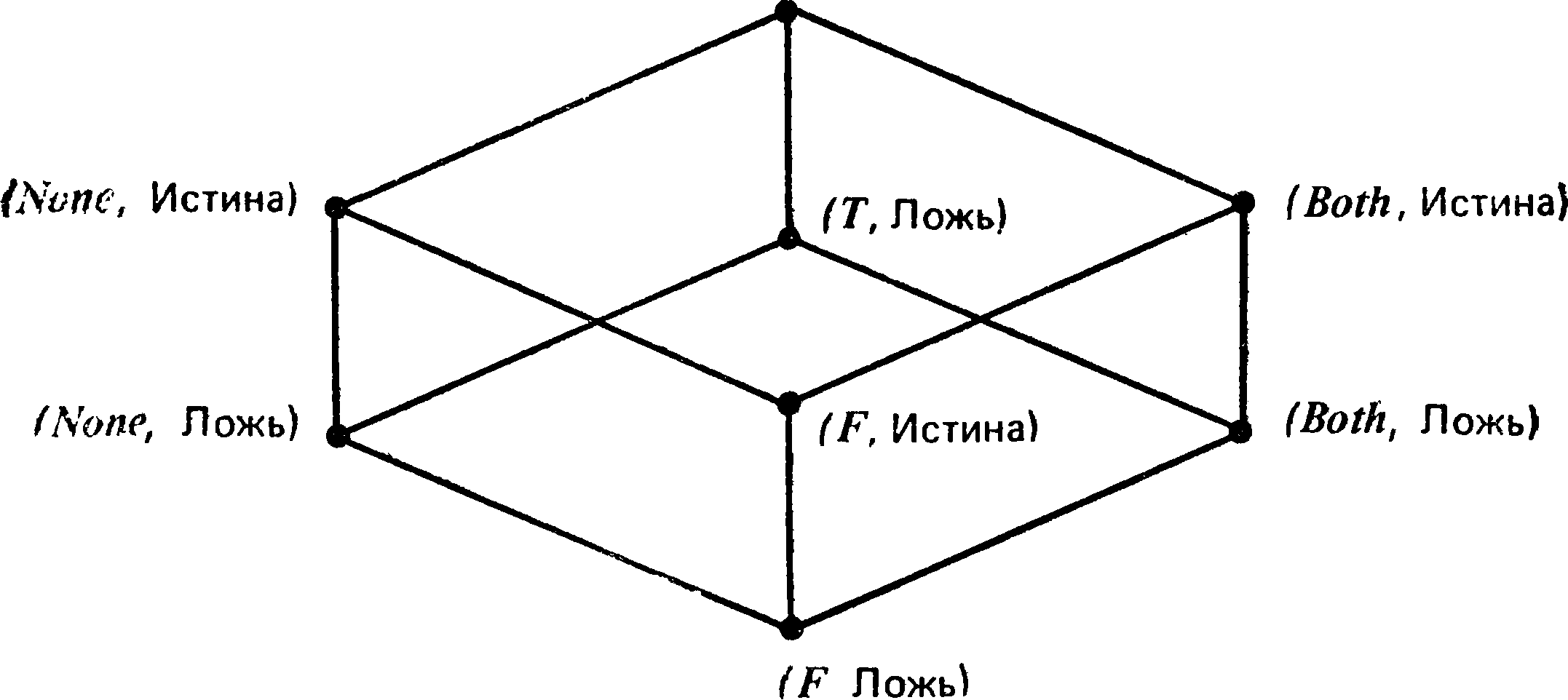
Рис. 3. Решетка восьмизначной логики.
Связки amp; и V могут быть вычислены соответственно как наименьшая верхняя грань (н. в. г.) и наибольшая * нижняя грань (н. н. г.), в то время как парами для отрица-1 ния являются две левые, две центральные, две правые и J. верхняя — нижняя вершины (что не совпадает с булевским^ случаем). Значения в этой новой многозначной логике имеют | сложный статус: они частично эпистемические и частично онтологические. Должны ли мы теперь перейти к этой логике? Любопытно, что для выводов в этом нет никакой необходимости. Действительно, в описанной логике значимы в точности те же выводы, что и при нашем четырехзначном критерии вывода. Этот факт не удивителен по двум причинам. Во-первых, как мы уже отмечали, единственное, чем мы на самом деле пользуемся при выводе,— это эпистемические значения Г, F, None и Bothy представляющие то, что мы знаем и считаем, или, во всяком случае, то, что сообщено авторитетным источником, которому мы, вообще говси ря, доверяем. Во-вторых — и это более прозаическое объяснение,— заметим, что все выводы, установленные с помощью четырехзначного критерия, верны также при двузначной логике. Таким образом, добавление в качестве условия того, что онтологическая истинность должна сохраняться, означает всего лишь добавление условия, которое уже выполнено и не порождает новых ограничений. Следовательно,практические соображения подсказывают, что для оценки выводов нет необходимости переходить от четырехзначной логики к восьмизначной. Перефразируя изречение знаменитого философа, можно сказать: «Не умножай число значений без необходимости».
Если же, однако, по каким-либо причинам (в данный момент я не знаю, по каким именно) кто-то захотел бы оценить логическую истину предложений с amp;, V И ~, то он мог бы воспользоваться следующим критерием: всегда «Истина» (в правой части пары) независимо от того, что сообщается (в соответствии с левой частью пары). Тогда не удивительно, что двузначные тавтологии при таком способе оценки логически истинны, и неудивительно потому, что мы используем только онтологические значения, не принимая во внимание (в восьмизначном случае) всю информацию, заключенную в эпистемических значениях.
Если это не очевидно, то выскажусь яснее: я полагаю, что кодификация функциональных логических истин не очень важна для компьютера. На самом деле, что существенно для компьютера, так это способ рассуждения с функциональными компонентами, а не их сортировка.
Четвертое мое замечание касается существенной роли значений None и Both. Обычно считают, что эти значения должны быть отождествлены и что компьютер находится в одном и том же состоянии, и когда ему сообщается, что А — и «Истина» и «Ложь» одновременно, и когда ему об А ничего не сообщается. А. Кенни и С. Хаак разньь ми путями пришли к подобным идеям. Если вас удовлетворит диалектический афоризм, я мог бы предложить одну из формулировок типа: «Неправильно, но понятно». Дело вот в чем. Во-первых, совершенно очевидно, что значения Both и None не должны отождествляться именно потому (как заметил в одной из бесед X. Харрис), что мы хотим от компьютера, чтобы тот различал для нас, когда сообщается противоречие и когда ничего не сообщается. Конечно, все зависит от точки зрения. Во-вторых, приводимые рассуждения можно истолковать как попытку отождествить рассматриваемые значения, достаточно лишь взглянуть на логическую решетку L4. Both и None занимают в решетке (различные, но) совершенно симметричные положения между F и Т, и в этом смысле они «тождественны». В частности, мы не допускаем выводов, приводящих от Both и None к F, а также выводов, приводящих от Т к Both или None, и, таким образом, трактуем рассматриваемые значения одинаково.
И все же, хотя такой ответ, возможно, полезен, я не вполне им удовлетворен и предпочитаю оставить в данный момент обсуждение незаконченным.
Мое предпоследнее замечание касается предложения о том, чтобы компьютер хранил больше информации, чем я разрешил ему хранить. Возможно, следует подсчитать число случаев, когда компьютеру сообщается «Истина» или когда ему сообщается «Ложь». Возможно, имеет смысл следить за источником сообщений с помощью постоянных помет, например «Сэм говорит Истину в отношении 2200 : 03 на 4 августа 1973 г.». Я не вижу причин, почему эти идеи не должны быть исследованы, но по этому поводу мне хотелось бы сделать два комментария. Первый состоит в том, что вовсе не очевидно, как такая дополнительная информация должна использоваться при ответах на вопросы, при выводах и при введении сложных предложений. Другими словами, простота идеи в случае атомарных предложений не должна вводить в заблуждение. Наше замечание означает только, что полное исследование этого вопроса еще не закончено. Второй комментарий — это практическое указание на то, что за получение дополнительной информации приходится платить дорогой ценой, и эта цена может быть, а может и не быть оправданной. И в тех случаях, когда цена себя не оправдывает, мы возвращаемся к первоначально описанной ситуации.
В заключение хочу упомянуть некоторые альтернативные подходы. А. Гупта заметил, что можно определять значение А по s не непосредственно, как мы это сделали, а с учетом всех непротиворечивых подсетапов s.
Определения: s' является подсетапом s, если s' приближает s, s' JC s; подсетап s' непротиворечив, если он никогда не дает значение Both. Пусть, наконец, s (А) определено по Гупте следующим образом: s(A) = {s'(A) : s' — непротиворечивый подсетап s}, где s' (А) уже определено. Эта идея явно двойственна определению истины, данному ван Фраа- ссеном, при ее оценке по отношению ко всем полным (т. е. когда все пробелы в истинностных оценках заполнены) супероценкам данной оценки. Было отмечено, что если s(p)=Bothgt; тона вопрос о р (при данном s) ответбудет «Да и Нет», как и раньше, а на вопрос о р amp; ~ р ответ будет только «Нет» вместо «Да и Нет».
Оказывается, что идея приведенного определения может быть использована для усовершенствования одного предложения, выдвинутого Решером в работе «Гипотетическое рассуждение» (1964). В этой работе Решер предлагает метод ведения рассуждений при противоречивом множестве посылок, а именно: рассматривать все непротиворечивые подмножества посылок. Трудность, связанная с этой идеей, по моему убеждению, состоит в чрезмерной зависимости от способа разбиения множества посылок на отдельные предложения. Я полагаю, что можно применить предложенное Гуптой понятие, которое позволит представить идею Реше- ра очищенной от вредных примесей, но сохраняющей свои первоначальные привлекательные особенности.
Сходная идея была выдвинута ван Фраассеном: нужно непосредственно просматривать все полные суперсетапы данного сетапа. Тогда на р V ~ Р мы всегда будем получать ответ «Да». Доведение этой идеи до логического конца потребовало бы (аккуратной) комбинации двух упомянутых подходов.
Все эти предложения реальны. Можно, однако, надеяться, что обсуждение ряда альтернативных возможностей будет вращаться вокруг вопроса: «Что мы хотим от компьютера, когда задаем ему вопросы?» На этом пути наши альтернативы перестанут быть просто некоторыми возможностями.
Кванторы. При исследовании вопросов, относящихся к кванторам, сталкиваются с большими сложностями. Коснусь их лишь слегка, полностью сознавая, что их детальное исследование существенно для решения стоящей перед нами задачи.
Во-первых, возникает вопрос, является ли «наша» область действия кванторов конечной или бесконечной. Оба случая одинаково правдоподобны. В последнем проблема заключается втом, как компьютер должен представлять бесконечную информацию при своих конечных возможностях. Из существования такой проблемы не следует, однако, делать вывод, что компьютер не может или не должен иметь дело с кванторами по бесконечным областям. Конечно, компьютеру должно быть разрешено отвечать (если он может) на вопросы типа: «Существует ли число, такое, что ..?»
Во-вторых, возникает вопрос, будет ли компьютер иметь имена для всех объектов в «нашей» области с тем, чтобы мы могли использовать подстановочную интерпретацию кванторов, или же компьютер не имеет имен для всех объектов, и тогда мы вынуждены будем применять интерпретацию «область — значения». И опять обе ситуации равноверо^ ятны, хотя рассмотрение стандартных примеров, подобных вопросам о бейсболе или о полетах на авиалиниях, может привести к мысли, что в ситуации с компьютером все и всегда имеет имя. Тем не менее в одной работе Изнера компьютеру, например, сообщается, что «существует нечто между а и Ь» в ситуации, когда он не получает полного списка имен или объектов для интерпретации данного утверждения. И все же компьютер должен делать выводы и отвечать на заданные ему вопросы. (Конечно, прекрасно, если компьютер придумывает свои собственные имена для «чего-либо», что находится между а и Ь; однако этот случай, хотя и важный, но совсем другого сорта.)
Во всяком случае, семантика, приданная связкам, распространяется на кванторы общности и существования очевидным образом, и я буду предполагать, что это уже сделано. Оказывается, что различные альтернативные возможности не требуют каких-либо различий в отношении логит (за исключением, очевидно, случая, когда область конечна и все объекты имеют имена): общезначимые «следования первой степени» из работы Андерсона и Белнапа [1965] также годятся (дополненные для конечного случая законом, в соответствии с которым конъюнкция, пробегающая по всей области, влечет соответствующее универсальное утверждение).
Часть П. Функционально-составные данные
Моя цель в этой и следующей частях статьи дать краткое изложение полученных результатов и выводов. Они более существенно, чем это было в части I, основываются на аппро- ксимационных решетках и в целом являются более техническими. Тем не менее кое-что может быть рассказано, чтобы у читателя сложилось определенное представление (детально см.: Белнап [1976]). г
Эпистемические состояния. Если мы позволим компьютеру принимать в качестве входных данных не только атомарные, но и сложные формулы типа p\/q, то одного сетапа уже недостаточно для представления эпистемического состояния компьютера. Хорошо известное решение задач этого типа, восходящее по меньшей мере к Карнапу [1942], разработано в эпистемической и доксастической логике
Хинтикки [1962] и применено для компьютера в работах Изнера [1972, 1975]. Оно состоит в использовании для представления эпистемического состояния компьютера, не одного, а целого набора сетапов. Предположим, что это уже сделано. Далее можно применить аппроксимационные идеи для объяснения и определения способа, при котором компьютер отвечал бы на наши вопросы об А в каждом таком состоянии. Это значит, что если Е — эпистемическое состояние компьютера, то мы можем вычислить Е(А), т. е. значение А в Е как одно из четырех наших значений. Предположим, что это также сделано. (Пропущенное определение: E(A)=n{s(A) : sgE}.) Отметим два важных для дальнейшего эпистемических состояния: Tset (А) и Fset (А), которые определяются таким образом, чтобы они отражали то, что сообщается компьютеру, когда А соответственно утверждается или отрицается. (Пропущено: Tset (А) = {s : FJI s(A)} и Fset(A) = {s : FCs(A)}.)
Еще об аппроксимационных решетках. Одно из главных положений, которые можно извлечь из работы Скотта, состоит в том, что если существует одна аппроксимационная решетка, то их существует множество. В частности, семейство всех сетапов образует естественную аппроксимацион- ную решетку AS, а семейство всех эпистемических состояний образует (или почти образует, разные тонкости мы опускаем) другую аппроксимационную решетку АЕ. (Пропущено: s С. s' в AS тогда и только тогда, когда s(p)JC JIs' (р) для всех р\ Е С_ Е' в АЕ тогда и только тогда, когда для каждого s' ? Е' существует s g Е, такое, что s ? s'.)
Формулы как отображения; новый тип значений. Теперь я перехожу к вопросу, представляющему значительный интерес,— к вопросу, на который наши различные аппроксимационные решетки могут пролить существенный свет. Как должен компьютер интерпретировать функционально составленную формулу А, поступающую на его вход? Ясно, что компьютер постарается использовать А для изменения своего наличного эпистемического состояния. Действительно, определение того, как компьютер использует формулу А для преобразования своего наличного эпистемического состояния в новое эпистемическое состояние, заключается в способе, хорошем способе приписывания формуле А значений. Сказать так — не значит сказать слишком много. Мы хотим непременно связать с каждой формулой преобразование, отображение эпистемических состояний в новые эпистемические состояния. Более того, мы хотим также знать, что компьютер должен делать, когда формула А отрицается. Таким образом, мы фактически связываем с формулой А две функции: одна представляет преобразование эпистемических состояний, когда А утверждается, а другая — когда А отрицается. Обозначим эти две функции через Л+ и Как определить их?
Напомним, что функция А+ должна отображать одни состояния в другие: А + (Е) = Е'. Основная идея определения того, что нам хотелось бы иметь в качестве Е', связана с аппроксимационными решетками. Во-первых, в рассматриваемой ситуации мы предполагаем, что компьютер всегда использует входные данные для увеличения своей информации или по крайней мере никогда не использует входные данные, чтобы отбросить часть своей собственной. (Последнее может составить предмет отдельной работы; хотелось бы узнать, хотя бы теоретически, как поступать в таком случае, но я этого не знаю.) На языке приближений мы можем сказать точнее: Е? Л+ (Е). Во-вторых, А + (Е) определенно должно сообщать не меньше, чем утверждение А : Tset (A) JI А+ (Е). В-третьих, наконец, мы безусловно хотим, чтобы А+(Е) было минимальным искажением Е, которое придает А значение «по меньшей мере Истина». «Минимальное искажение» — это прекрасное выражение Куайна, но, имея аппроксимационную решетку, можно придать этой метафоре точный смысл. А именно нужно, чтобы А+(Е) было наименьшим из тех эпистемических состояний, которые удовлетворяют нашим первым двум условиям. Таким образом, мы должны определить
А+ (Е) = Е lj Tset (А),
так что получается в точности минимальное искажение Е, которое отмечает А как «по меньшей мере Истина». (Напомним, что в любой решетке х lj у есть «наименьшая (минимум) верхняя грань».) Приняв такое определение А + , ле|gt; ко понять, что A-(E) должно быть минимальным искажением Е, которое отмечает А как «по меньшей мере Ложь»:
A-(E) = Ei_iFset(A).
Данные определения придают точный смысл А как входной информации, но они имеют один недостаток: множества Tset и Fset могут быть бесконечными или по крайней мере большими — столь большими, что компьютер не сможет с ними работать. По этой причине, а также ради самого компьютера было предложено другое определение А+ и А“ в работе Белнапа [1976], на этот раз индуктивное, но заимствующее многое от идеи минимального искажения. Здесь мы это определение опускаем.
Еще по теме КАК НУЖНО РАССУЖДАТЬ КОМПЬЮТЕРУ [†††††]:
- Мышление, как известно, есть, прежде всего, способность рассуждать, уметь делать на основе исходных посылок умозаключения.
- Почему я так быстро сдаюсь, когда покупатель говорит «нет»? Как долго нужно настаивать?
- О том, как воссоединить разделившийся город, и об ошибочности мнения, что для удержания городов нужно сеять в них раздоры
- Компьютер в целом
- Как Луизе Реборедо стимулировать креативность своих подчиненных? Что ей нужно сделать, чтобы создать комфортный климат для творческих людей, которые могут прийти в компанию в будущем?
- 13. В то время как аристотелики признают других и доверяют им больше чем нужно, себе они доверяют меньше чем следует
- Мой компьютер — все внутри
- Бирюкова Л.П., Пастухова Л.Б.. Учимся рассуждать. Учебное пособие по развитию и культуре речи. - Чебоксары: Изд-во ЧГПУ им. И.Я. Яковлева,1999. - 110 с., 1999
- Структура и компоненты персонального компьютера
- Компьютер и модем
- Речевое взаимодействие человека с компьютером
- Взаимосвязь компьютера с основными компонентами педагогического процесса
- Что же надо знать, чтобы защитить свой компьютер?
- Специальные технические средства опознавания пользователя компьютера
- Лексика и фразеология компьютерного языка непрофессионалов Образ компьютера в разговорной речи
- Специальное программное обеспечение по защите информации компьютера
- Техника безопасности при работе с компьютером
- Классификация компьютеров
- Обслуживание компьютера.