ПОИСК В СТРУКТУРАХ
5.4.1. ЗАДАЧИ ПОИСКА
Под поиском понимается определение местоположения некоторой переменной или элемента данных в структуре. Практически любой обработке информации предшествуют процедуры поиска, с помощью которых осуществляется доступ к обрабатываемым данным.
Процедуры поиска разнообразны. Ниже рассматриваются некоторые типичные задачи, решаемые в процессе поиска.К поисковой процедуре сводится -задача ассоциативного доступа к переменной, когда по известному значению переменной требуется определить ее адрес. При селективной обработке таблиц и списков поиск местоположения требуемых элементов осуществляется по известным значениям ключевых записей. При обработке символьных строк применяется поиск известной цепочки символов в заданной строке для обнаружения различных ключевых слов. Приведенные далее программы предназначены в основном для иллюстрации типичных поисковых процедур, но они могут быть использованы как элементарные при разработке реальных программных комплексов.
5.4.2. ПРОСТОЕ СРАВНЕНИЕ МАССИВОВ
Эта операция выполняет побайтное сравнение заданных массивов, т. е. первый байт одного массива сравнивается с первым байтом второго массива, второй байт — со вторым и т. д. Если при очередном сравнении будет установлено неравенство байтов, дальнейшее сравнение прекращается, так как одного этого факта достаточно, чтобы сделать вывод о неравенстве массивов. Программа сравнения имеет следующий вид:

Непосредственное сравнение выполняется путем организации итерационного цикла. В начале каждой итерации проверяется значение счетчика текущей длины, и если оно равно нулю, то производится выход из цикла. Доступ к байтам, которые подлежат сравнению, осуществляется с помощью двух указателей, которые адресуют текущие байты соответственно первого и второго массивов.
Если при очередном сравнении флаг Z равен нулю, т. е. байты не равны, выполнение цикла прекращается. В конце итерации модифицируются указатели массивов и счетчик текущей длины. Значение выходного параметра записывается в регистр (А) в теле цикла непосредственно перед командами условного перехода с помощью команды МѴІ, которая не изменяет состояние флагов микропроцессора. Этот прием позволяет достигнуть большей компактности программы, но увеличивает время ее выполнения.В программе предусмотрено сохранение значений входных параметров. В некоторых случаях при выполнении операции сравнения необходимо не только знать факт неравенства массивов, но и установить адреса байтов, по которым произошло несовпадение. Это можно обеспечить, если убрать из текста программы команды записи в стек и команды восстановления из стека, а также команду возврата, причем команды условного перехода, обеспечивающие выход из цикла, заменить командами условного возврата. Тогда в-случае несовпадения массивов наряду с признаком в регистре (А) в регистровые пары (D, Е) и (Н, L) будут возвращены адреса несовпадающих байтов соответственно первого и второго массивов. Если необходимо обеспечить обработку несовпадающих байтов с помощью внешней подпрограммы, например для индикации их адресов и значений, следует команду условного перехода заменить командой условного вызова CNZ подпрограммы обработки.
5.4.3. ПОИСК ОДНОБАЙТНОГО КОДА В МАССИВЕ
Задача состоит в определении адреса байта при известных его значениях и границах области памяти, в которой он может быть расположен. Программа поиска имеет вид:

Поиск заданного байта производится с помощью итеративного цикла, в котором исходный байт последовательно сравнивается с каждым байтом массива. При первом же успешном сравнении осуществляется возврат из программы. Адрес байта, подлежащего сравнению на текущей итерации, располагается в регистровой паре (Н, L), что автоматически обеспечивает требуемое значение выходного параметра при успешном поиске.
Выход из цикла выполняется при нулевом значении счетчика текущей длины, контролируемого в начале каждой итерации. Программа позволяет обнаружить только первое вхождение искомого кода в заданный массив. Если требуется определить адрес всех байтов, содержащих заданный код, или подсчитать их количество, нужно циклически вызывать указанную программу до тех пор, пока в регистровую пару (Н, L) не будет возвращен признак неудачного поиска.5.4.4. ПОИСК ПОСЛЕДОВАТЕЛЬНОСТИ КОДОВ В МАССИВЕ
Задача формулируется следующим образом: имеются два массива Ап В, причем длина массива А больше длины массива В; необходимо определить местоположение копии массива В в массиве А (если она имеется). Задачу в такой постановке приходится решать, когда требуется отыскать в некоторой строке заданную цепочку символов.
Алгоритм выполнения данной поисковой процедуры заключается в скользящем сравнении массива В с массивом А: массив В сравнивается с начальным фрагментом массива А, начинающегося с первого байта массива А, длина которого равна длине массива В, затем сравнение производится с фрагментом массива А, начинающимся со второго байта этого массива, и т. д. (рис. 5.4). Программа поиска имеет вид:


Рис. 5.4. Схема скользящего сравнения двух массивов.
Необходимое число сравнений для полного поиска определяется разностью длин массивов Л и В, которая вычисляется в начальном фрагменте программы. При извлечении значений длин массивов из стека в макрокоман-
де XTRN номер слова в стеке указывается с учетом того, что в начале программы были произведены две загрузки в стек.
Скользящее сравнение массивов организовано в виде итеративного цикла. Сравнение массива В с фрагментом массива А выполняется с помощью подпрограммы СРВНІ (она описана на с. 225—226). После каждого вызова подпрограммы анализируется признак результата сравнения, который устанавливается подпрограммой СРВНІ в регистре (А).
Если сравнение было успешным, т. е. копия массива В найдена в массиве А, формируется соответствующее значение выходного параметра и осуществляется возврат из программы. В противном случае поиск продолжается, адрес начала очередного фрагмента массива А инкрементируется, а в конце каждой итерации число сравнений декрементируется. Когда оно достигает нулевого значения, выполнение цикла скользящего сравнения прекращается и осуществляется возврат из программы. Полученное нулевое значение используется в качестве индикатора неудачного поиска без дополнительной установки выходного параметра. В программе обеспечено сохранение значений всех входных параметров, передаваемых через регистры и через стек.5.4.5. ПОИСК ЭЛЕМЕНТА ТАБЛИЦЫ ПО КЛЮЧУ
Ниже описывается процедура поиска элемента простой таблицы, формат которой приведен на рис. 5.5. В таблице, состоящей из т элементов длиной п байт, требуется определить адрес элемента, первый байт которого совпадает с заданным. Поиск заключается в просмотре первых байтов всех элементов и сравнении их значений с заданным. Программа поиска имеет вид:


Рис. 5.5. Структура таблицы
Для организации цикла сравнения используются две рабочие переменные — указатель таблицы, который содержит адрес первого байта очередного элемента, и счетчик, содержащий количество непросмотренных элементов. На каждой итерации производится сравнение значения байта, адресуемого указателем, с заданным кодом. Если они равны, то поиск завершается и осуществляется возврат из программы. При этом текущее значение указателя таблицы возвращается в качестве выходного параметра. В противном случае вычисляется новое значение указателя путем добавления к его текущему значению длины элемента. Хотя величина длины элемента помещается в одном байте, для ее хранения выделяется регистровая пара. Это сделано для упрощения модификации указа
теля, которая выполняется одной командой DAD.
В конце итерации значение счетчика декрементируется. После просмотра всех элементов (факт окончания просмотра определяется нулевым значением счетчика) в выходной параметр записывается признак неудачного поиска и выполняется возврат из программы. В программе существуют ограничения на количество т элементов в структуре
5.4.6. ПОИСК ЭЛЕМЕНТА СПИСКА
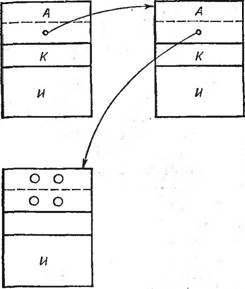
Поиск в списке предполагает определение адреса элемента, содержимое поля ключа которого равно заданному. Структура списка приведена на рис. 5.1. Для решения задачи необходимо просмотреть весь список, сравнивая при этом содержимое поля ключа каждого элемента с заданным значением. Программа поиска имеет следующий вид:

Б программе просмотр элементов списка выполняется с помощью итеративного цикла. Для полного определения местоположения элемента в однонаправленном списке необходимо знать адрес не только данного элемента, но и предыдущего, так как в однонаправленных списках отсутствуют адресные ссылки назад. С этой целью в программу вводятся два указателя: один содержит адрес начала текущего элемента и расположен в регистровой паре (В, С), второй — адрес начала предыдущего элемента и помещается в регистровой паре (Н, L). Первоначально значение первого указателя равно адресу начала списка, а второго — нулю. На каждой итерации анализируется поле ключа одного элемента. После этого указатели меняются местами, и если обнаруживается, что поле ключа текущего элемента равно заданному, осуществляется возврат из программы. В противном случае в первый указатель загружается значение поля связи текущего элемента. Если новое значение первого указателя равно нулю (а это означает окончание списка), выполнение цикла прекращается, в регистровую пару (Н, L) загружается признак неудачного поиска и выполняется возврат из программы.
5.4.
Еще по теме ПОИСК В СТРУКТУРАХ:
- Область поиска A*
- Советы по поиску
- Основы поиска
- Поиск программного обеспечения
- 3.2 Поиск в бинарных деревьях
- Поиск картинок
- Глава 3. Инструменты поиска
- Общее планирование поиска
- Утилиты поиска
- Archie — система поиска файлов