3.2 Поиск в бинарных деревьях
В разделе 1 мы использовали двоичный поиск для поиска данных в массиве. Этот метод чрезвычайно эффективен, поскольку каждая итерация вдвое уменьшает число элементов, среди которых нам нужно продолжать поиск.
Однако, поскольку данные хранятся в массиве, операции вставки и удаления элементов не столь эффективны. Двоичные деревья позволяют сохранить эффективность всех трех операций – если работа идет с “случайными” данными. В этом случае время поиска оценивается как O(lg n). Наихудший случай – когда вставляются упорядоченные данные. В этом случае оценка время поиска – O(n). Подробности вы найдете в работе Кормена [2].Теория
Двоичное дерево – это дерево, у которого каждый узел имеет не более двух наследников. Пример бинарного дерева приведен на рис. 3.2. Предполагая, что Key содержит значение, хранимое в данном узле, мы можем сказать, что бинарное дерево обладает следующим свойством: у всех узлов, расположенных слева от данного узла, значение соответствующего поля меньше, чем Key, у всех узлов, расположенных справа от него, – больше. Вершину дерева называют его корнем, узлы, у которых отсутствуют оба наследника, называются листьями. Корень дерева на рис. 3.2 содержит 20, а листья – 4, 16, 37 и 43. Высота дерева – это длина наидлиннейшего из путей от корня к листьям. В нашем примере высота дерева равна 2.

Рис. 3.2: Двоичное дерево
Чтобы найти в дереве какое-то значение, мы стартуем из корня и движемся вниз. Например, для поиска числа 15, мы замечаем, что 16 < 20, и потому идем влево. При втором сравнении имеем 16 > 7, так что мы движемся вправо. Третья попытка успешна – мы находим элемент с ключом, равным 15.
Каждое сравнение вдвое уменьшает количество оставшихся элементов. В этом отношении алгоритм похож на двоичный поиск в массиве. Однако, все это верно только в случаях, когда наше дерево сбалансировано.
На рис. 3.3 показано другое дерево, содержащее те же элементы. Несмотря на то, что это дерево тоже бинарное, поиск в нем похож, скорее, на поиск в односвязном списке, время поиска увеличивается пропорционально числу запоминаемых элементов.
Рис. 3.3: Несбалансированное бинарное дерево
Вставка и удаление
Чтобы лучше понять, как дерево становится несбалансированным, посмотрим на процесс вставки пристальнее. Чтобы вставить 18 в дерево на рис. 3.2 мы ищем это число. Поиск приводит нас в узел 16, где благополучно завершается. Поскольку 18 > 16, мы попросту добавляет узел 18 в качестве правого потомка узла 16 (рис. 3.4).
Теперь мы видим, как возникает несбалансированность дерева. Если данные поступают в возрастающем порядке, каждый новый узел добавляется справа от последнего вставленного. Это приводит к одному длинному списку. Обратите внимание: чем более “случайны” поступающие данные, тем более сбалансированным получается дерево.
Удаления производятся примерно так же – необходимо только позаботиться о сохранении структуры дерева. Например, если из дерева на рис. 3.4 удаляется узел 20, его сначала нужно заменить на узел 37. Это даст дерево, изображенное на рис. 3.5. Рассуждения здесь примерно следующие. Нам нужно найти потомка узла 20, справа от которого расположены узлы с большими значениями. Таким образом, нам нужно выбрать узел с наименьшим значением, расположенный справа от узла 20. Чтобы найти его, нам и нужно сначала спуститься на шаг вправо (попадаем в узел 38), а затем на шаг влево (узел 37); эти двухшаговые спуски продолжаются, пока мы не придем в концевой узел, лист дерева.

Рис. 3.4: Бинарное дерево после добавления узла 18
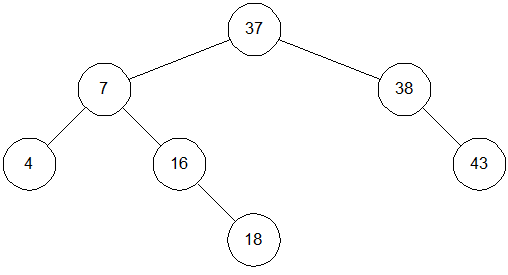
Рис. 3.5: Бинарное дерево после удаления узла 20
Реализация
Реализация алгоритма на Си находится в разделе 4.6. Операторы typedef T и compGT следует изменить так, чтобы они соответствовали данным, хранимым в дереве. Каждый узел Node содержит также указатели left, right на левого и правого потомков, а также указатель parent на предка. Собственно данные хранятся в поле data. Адрес узла, являющегося корнем дерева хранится в укзателе root, значение которого в самом начале, естественно, NULL. Функция insertNode запрашивает память под новый узел и вставляет узел в дерево, т.е. устанавливает нужные значения нужных указателей. Функция deleteNode, напротив, удаляет узел из дерева (т.е. устанавливает нужные значения нужных указателей), а затем освобождает память, которую занимал узел. Функция findNode ищет в дереве узел, содержащий заданное значение.
Еще по теме 3.2 Поиск в бинарных деревьях:
- 4.6 Коды для бинарных деревьев
- Метод ветвей и границ относительно бинарных деревьев. Примеры задач, основные этапы, алгоритм нахождения оптимального решения
- Бинарно множественная философия в бинарно множественном разветвляющемся мире Binary plural philosophy in binary plural branching world
- 1.5. Свойства бинарных отношений. Специальные бинарные отношения
- Свойства бинарных отношений.
- 5.5 Многокритериальный выбор на языке бинарных отношений
- §12. Понятие бинарного отношения между элементами одного множества
- Свойства бинарных отношений
- Бинарная теория залога
- 1.6. Операции над бинарными отношениями
- Деревья и циклы.
- Кодировка дерева
- Деревья