3.1 Хеш-таблицы
Для работы с словарем требуются поиск, вставка и удаление. Один из наиболее эффективных способов реализации словаря – хеш-таблицы. Среднее время поиска элемента в них есть O(1), время для наихудшего случая – O(n).
Прекрасное изложение хеширования можно найти в работах Кормена[2] и Кнута[1]. Чтобы читать статьи на эту тему, вам понадобится владеть соответствующей терминологией. Здесь описан метод, известный как связывание или открытое хеширование[3]. Другой метод, известный как замкнутое хеширование[3] или закрытая адресация[1], здесь не обсуждаются. Ну, как?Теория
Хеш-таблица – это обычный массив с необычной адресацией, задаваемой хеш-функцией. Например, на hashTable рис. 3.1 – это массив из 8 элементов. Каждый элемент представляет собой указатель на линейный список, хранящий числа. Хеш-функция в этом примере просто делит ключ на 8 и использует остаток как индекс в таблице. Это дает нам числа от 0 до 7 Поскольку для адресации в hashTable нам и нужны числа от 0 до 7, алгоритм гарантирует допустимые значения индексов.
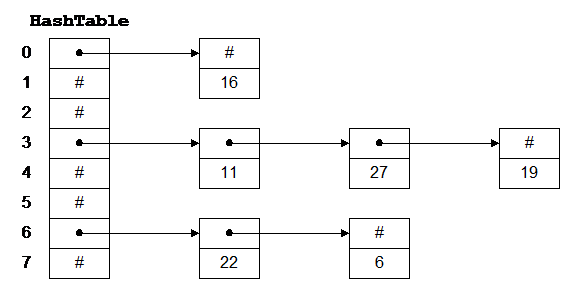
Рис. 3.1: Хеш-таблица
Чтобы вставить в таблицу новый элемент, мы хешируем ключ, чтобы определить список, в который его нужно добавить, затем вставляем элемент в начало этого списка. Например, чтобы добавить 11, мы делим 11 на 8 и получаем остаток 3. Таким образом, 11 следует разместить в списке, на начало которого указывает hashTable[3]. Чтобы найти число, мы его хешируем и проходим по соответствующему списку. Чтобы удалить число, мы находим его и удаляем элемент списка, его содержащий.
Если хеш-функция распределяет совокупность возможных ключей равномерно по множеству индексов, то хеширование эффективно разбивает множество ключей. Наихудший случай – когда все ключи хешируются в один индекс.
При этом мы работаем с одним линейным списком, который и вынуждены последовательно сканировать каждый раз, когда что-нибудь делаем. Отсюда видно, как важна хорошая хеш-функция. Здесь мы рассмотрим лишь несколько из возможных подходов. При иллюстрации методов предполагается, что unsigned char располагается в 8 битах, unsigned short int – в 16, unsigned long int – в 32.· Деление (размер таблицы hashTableSize – простое число). Этот метод использован в последнем примере. Хеширующее значение hashValue, изменяющееся от 0 до (hashTableSize - 1), равно остатку от деления ключа на размер хеш-таблицы. Вот как это может выглядеть:
typedef int hashIndexType;
hashIndexType hash(int Key) { return Key % hashTableSize; }
Для успеха этого метода очень важен выбор подходящего значения hashTableSize. Если, например, hashTableSize равняется двум, то для четных ключей хеш-значения будут четными, для нечетных – нечетными. Ясно, что это нежелательно – ведь если все ключи окажутся четными, они попадут в один элемент таблицы. Аналогично, если все ключи окажутся четными, то hashTableSize, равное степени двух, попросту возьмет часть битов Key в качестве индекса. Чтобы получить более случайное распределение ключей, в качестве hashTableSize нужно брать простое число, не слишком близкое к степени двух.
Мультипликативный метод (размер таблицы hashTableSize есть степень 2n). Значение Key умножается на константу, затем от результата берется необходимое число битов. В качестве такой константы Кнут[1] рекомендует золотое сечение 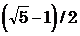 = 0.6180339887499. Пусть, например, мы работаем с байтами. Умножив золотое сечение на 28, получаем 158. Перемножим 8-битовый ключ и 158, получаем 16-битовое целое. Для таблицы длиной 25 в качестве хеширующего значения берем 5 младших битов младшего слова, содержащего такое произведение. Вот как можно реализовать этот метод:
= 0.6180339887499. Пусть, например, мы работаем с байтами. Умножив золотое сечение на 28, получаем 158. Перемножим 8-битовый ключ и 158, получаем 16-битовое целое. Для таблицы длиной 25 в качестве хеширующего значения берем 5 младших битов младшего слова, содержащего такое произведение. Вот как можно реализовать этот метод:
/* 8-bit index */
typedef unsigned char hashIndexType;
static const hashIndexType K = 158;
/* 16-bit index */
typedef unsigned short int hashIndexType;
static const hashIndexType K = 40503;
/* 32-bit index */
typedef unsigned long int hashIndexType;
static const hashIndexType K = 2654435769;
/* w=bitwidth(hashIndexType), size of table=2**m */
static const int S = w - m;
hashIndexType hashValue = (hashIndexType)(K * Key) >> S;
Пусть, например, размер таблицы hashTableSize равен 1024 (210).
Тогда нам достаточен 16-битный индекс и S будет присвоено значение 16 – 10 = 6. В итоге получаем:typedef unsigned short int hashIndexType;
hashIndexType hash(int Key) {
static const hashIndexType K = 40503;
static const int S = 6;
return (hashIndexType)(K * Key) >> S;
} Аддитивный метод для строк переменной длины (размер таблицы равен 256). Для строк переменной длины вполне разумные результаты дает сложение по модулю 256. В этом случае результат hashValue заключен между 0 и 244.
typedef unsigned char hashIndexType;
hashIndexType hash(char *str) {
hashIndexType h = 0;
while (*str) h += *str++;
return h;
} Исключающее ИЛИ для строк переменной длины (размер таблицы равен 256). Этот метод аналогичен аддитивному, но успешно различает схожие слова и анаграммы (аддитивный метод даст одно значение для XY и YX). Метод, как легко догадаться, заключается в том, что к элементам строки последовательно применяется операция “исключающее или”. В нижеследующем алгоритме добавляется случайная компонента, чтобы еще улучшить результат.
typedef unsigned char hashIndexType;
unsigned char Rand8[256];
hashIndexType hash(char *str) {
unsigned char h = 0;
while (*str) h = Rand8[h ^ *str++];
return h;
}
Здесь Rand8 – таблица из 256 восьмибитовых случайных чисел. Их точный порядок не критичен. Корни этого метода лежат в криптографии; он оказался вполне эффективным [4]. Исключающее ИЛИ для строк переменной длины (размер таблицы £ 65536). Если мы хешируем строку дважды, мы получим хеш-значение для таблицы любой длины до 65536. Когда строка хешируется во второй раз, к первому символу прибавляется 1. Получаемые два 8-битовых числа объединяются в одно 16-битовое.
typedef unsigned short int hashIndexType;
unsigned char Rand8[256];
hashIndexType hash(char *str) {
hashIndexType h;
unsigned char h1, h2;
if (*str == 0) return 0;
h1 = *str; h2 = *str + 1;
str++;
while (*str) {
h1 = Rand8[h1 ^ *str];
h2 = Rand8[h2 ^ *str];
str++;
}
/* h is in range 0..65535 */
h = ((hashIndexType)h1
Еще по теме 3.1 Хеш-таблицы:
- 4.5 Коды для хеш-таблиц
- Исследование цветового зрения по полихроматическим таблицам Е. Б. Рабкина и пороговым таблицам Е. Н. Юстовой
- Таблицы и графики дисконтирования Натуральные логарифмы Статистические таблицы Формулы производны
- Таблица 8 – Таблица для SWOT-анализа
- 1.5.4 Построение таблиц
- Работа с таблицами
- 7.3. Таблицы смертности
- Формирование таблиц Spreadsheet
- Электронные таблицы
- Таблицы смертности
- Сведем их в таблицу (см.
- Таблица V.
- в) Таблицы смертности
- 4. Отыскивание чисел по таблице Шульте (табл. 4—8)