М. Халле О РОЛИ ПРОСТОТЫ В ЛИНГВИСТИЧЕСКИХ описаниях* [81]
Почти с самого возникновения абстрактного подхода к изучению языка предлагались какие-то схемы классифи- кации звуков речи. Это и не удивительно, поскольку вполне очевидно, что звуки речи образуют различные пересекающиеся классы.
Так, например, все конечные звуки в словах ram, ran, rang обладают свойством назальности, то есть они возникают в тот момент, когда опущено мягкое нёбо, и воздух может проходить через нос. Аналогичным образом звук [т], так же как звуки [р] и [Ь], образуется в тот момент, когда губы сомкнуты или, как сказали бы фонетисты, этот звук имеет губно-губную артикуляцию. Таким образом, отдельные звуки речи можно охарактеризовать как комплексы назальности, определенного места артикуляции и некоторых других свойств. Из всех подобных свойств складываются различные системы классификации.Такие системы, конечно, отличаются одна от другой, и вплоть до настоящего времени фонетисты не пришли к какой-либо единой системе, которую можно было бы применить к любому описанию языка. В дальнейшем я буду пользоваться термином «различительные признаки» (distinctive features), который ввел в обиход Роман Якобсон.
Система различительных признаков отличается от всех других тем, что она состоит из бинарных свойств. Если мы будем строить свою классификацию на основе различительных признаков, то о звуках речи мы должны будем говорить только в терминах двузначных характеристик, то есть таких свойств, которыми данный звук может или не может обладать.
Способ характеристики отдельных звуков речи в терминах различительных признаков показан на рис. 1. В этой системе звук [s] характеризуется как негласный, согласный, ненизкий, некомпактный, резкий, неносовой, непрерывный, глухой;звук [ш] описывается как негласный, согласный, низкий, некомпактный, нерезкий, носовой, прерывный, звонкий. Следовательно, знаки алфавита s и ш, которыми мы условно обозначаем эти звуки, являются не чем иным, как сокращениями, заменяющими комплексы только что упомянутых признаков.
Ниже мы будем рассматривать звуки именно как такие комплексы, а не как неделимые сущности. Будет показано, что подобный подход открывает путь для дальнейших исследований в этой области.Заметим, что с помощью указанных признаков очень удобно описывать различные классы звуков речи. Так, например, все звуки, представленные на рис. 1, относятся к классу согласных и в качестве таковых обладают признаками «негласный» и «согласный». Можно заметить также, что единственными согласными, которым свойственны признаки «ненизкий» и «резкий», являются звуки [s Z с 3 s z], а звуки [р b f v ш] обладают общими признаками «резкий, некомпактный». С другой стороны, [ш] и [s] не имеют таких признаков, которые бы отличали их и только их от других согласных. Если бы мы захотели охарактеризовать с помощью различительных признаков класс, содержащий только звуки [ш] и [s], нам пришлось бы составить длинный, громоздкий список признаков. Мы будем говорить, что множество звуков речи образует естественный класс в том случае, если для описания этого класса требуется меньшее количество признаков, чем для характеристики любого отдельного звука в классе. Следовательно, первые три множества звуков образуют естественные классы, а множество, содержащее [ш] и [s], класса не образует.
| гласный------------------------------------------------------------------ | ||||||||||||||||
| согласный + | + | + | + | + | + | + | + + | + | + | + | + | + | + | + | + | + |
| низкий + | + | + | + | + | + | + | ||||||||||
| компактный — | — | — | — | — | + + | ----- | — | — | — | — | — | + | + | + | + | |
| резкий — | — | — | + | + | — | — | ----- | — | — | — | + | + | + | + | + | + |
| носовой — | — | + | — | — | — | — | ----- | — | — | + | — | — | — | — | — | — |
| непрерывный — | ■ — | — | + | + | — | — | ----- | + | 4- | — | + | + | — | — | + | + |
| звонкий — | + | + | — | + | — | + | - + | — | + | + | — | + | — | + | — | + |
Рис.
1. Различительные признаки согласных в английском языке.Якобсон показал, что при описании самых различных лингвистических фактов мы обычно встречаемся с множеством звуков, которые образуют естественные классы в системе различительных признаков, и что классы звуков, требующие для своей характеристики длинных, громоздких списков различительных признаков, встречаются редко. В качестве примера рассмотрим образование множественного числа имен существительных в английском языке. Каждый говорящий по-английски знает из практики, что только в тех случаях, когда существительное оканчивается на [s z s z с j], при образовании множественного числа к нему добавляется слог [iz]. Но, как мы уже видели, именно этот класс согласных исчерпывающе характеризуется признаками «ненизкий, резкий». Такое совпадение является важным, поскольку различительные признаки не составлялись специально для того, чтобы дать удобное описание правил образования множественного числа английских существительных.
Сделанные выше замечания наводят на мысль о целесообразности использования особого понятия экономии описания. Хотелось бы, чтобы в той части лингвистического описания, которая имеет отношение к звуковому аспекту языка, экономия измерялась количеством используемых при описании различительных признаков. Чем меньше упомянуто в описании признаков, тем больше его экономия. Не трудно заметить, что в простых случаях, как мы того и ожидали, можно найти подтверждения этому критерию. Если налицо две формулировки, из которых одна применима ко всем согласным, а другая — только к резким, то мы, не колеблясь, должны сказать, что первая является более общей и более экономичной. Но это касается и количества различительных признаков, поскольку, говоря о классе всех согласных, достаточно упомянуть только признаки негласный и согласный, в то время как для обозначения класса резких согласных мы должны характеризовать его еще и как резкий, то есть к общим признакам, характеризующим класс всех согласных, добавить еще один признак.
Аналогичным образом правило, применяемое без ограничений, мы считаем более общим, а следовательно, и более простым, чем правило, которое применяется лишь в определенных контекстах. Последнее также потребовало бы упоминания большего количества признаков, чем правило, применяемое без ограничений, поскольку здесь нужно было бы назвать по крайней мере еще один различительный признак, чтобы отличить один контекст от другого.Предложенный критерий имеет, однако, и другие интересные следствия. Для обнаружения их вернемся к образованию множественного числа английских имен существительных. При образовании множественного числа можно констатировать следующее:
(а) [4-z] добавляется, если основа оканчивается на звук, который является негласным, согласным, ненизким и резким;
(б) [sj добавляется, если основа оканчивается на звук, который является негласным, согласным, глухим и нерезким; или: негласным, согласным, глухим, резким и низким;
(в) [z] добавляется, если основа оканчивается на звук, который является гласным; или: негласным, согласным, звонким и нерезким; или: негласным, согласным, звонким, резким и низким.
Следует заметить, что приведенные выше три формулировки не упорядочены по отношению друг к другу, и именно это обстоятельство делает их такими громоздкими. Мы можем их значительно упростить, если сформулируем их в следующем виде:
Для образования множественного числа:
(А) добавляется [4-z], если основа оканчивается на звук, который является негласным, согласным, ненизким, резким;
(Б) добавляется [s], если основа оканчивается на звук, который является негласным, согласным и глухим;
(В) добавляется [г].
Относительная длина этих двух групп формулировок графически отражает их относительную простоту. Поэтому упорядочение в данном случае является обязательным, если мы желаем, чтобы наш критерий простоты был удовлетворительным.
Предложение о необходимости упорядочения применения правил не является новым. Любое описание, которое использует фразы типа «во всех других случаях», для того чтобы избежать необходимости подробной расшифровки того, чем могли бы быть эти «другие случаи», устанавливает порядок среди дескриптивных формулировок.
Новым здесь является только то, что причина установления порядка указывается совершенно точно, то есть непосредственно вытекает из предложенного критерия простоты. Заметим, однако, что упорядочение, установленное на такой основе, не является универсальным, поскольку в некоторых случаях упрощения описания может и не быть.Теперь рассмотрим гипотетический диалект английского языка [82], который отличается от стандартного языка в двух отношениях.
Там, где стандартный язык в положении, кроме начального, имеет непрерывный (фрикативный) согласный, наш диалект содержит прерывный (взрывной).
Там, где стандартный язык имеет несколько идентичных прерывных согласных в слове, в диалекте они все, за исключением первого, заменяются гортанным взрывным.
Примеры:
I II III
cuff (cup) [к'л р] puff [р'лр] pup [р'л9
gave (gabe) [g'eb] brave [br'eb] babe [b' e9
sauce (sought) [s'ot] toss [t'ot] taught [t'o9
lies (lied) [I'ajd] dies [d'ajd] died fd'aj9
Следует заметить, что в диалекте допускаются слова с несколькими идентичными взрывными согласными — это видно из примеров второго столбца. Но в каждом из этих примеров второй взрывной соответствует фрикативному стандартного языка.
Фонетические особенности этого диалекта регулируются следующими двумя упорядоченными правилами, не функционирующими в стандартном языке:
1. Если в слове имеется несколько идентичных негласных, согласных прерывных (взрывных), то все они, кроме первого, становятся негласными, несогласными прерывными (то есть в терминах различительных признаков, гортанными взрывными). См. примеры в столбце III.
2. В положении, кроме начального, негласные, согласные непрерывные становятся прерывными.
Я думаю, что эти формулировки, предложенные Эппл- гейтом, относятся скорее к фонологической системе диалекта, чем к описанию фонологической системы стандартного языка. Как мне кажется, более правильным было бы в данном случае сказать, что диалект отличается от стандартного языка только двумя относительно маловажными дополнительными правилами нижнего уровня, чем утверждать (что мы должны были бы сделать, если бы отбросили предложенное решение), что диалект отклоняется от стандартного языка в гораздо большей степени и в связи с этим обладает или иным фонемным составом по сравнению со стандартным языком, или совершенно отличной от последнего дистрибуцией фонем.
Нужно подчеркнуть, что в формулировках, предложенных Эпплгейтом, упорядочение правил имеет решающее значение. Если, например, правило 1 будет действовать после правила 2, то прерывные, согласно правилу 2, окажутся превращенными в гортанные взрывные, согласно правилу 1, и тогда невозможно будет объяснить примеры второго столбца. Без упорядочения правил мы должны будем принять неинтуитивные альтернативы, упомянутые выше.Если рассматривать процесс синтезирования высказывания как своего рода исчисление, конечные результаты которого передаются в качестве команд органам речи, а последние в свою очередь производят акустический сигнал, возбуждающий наши органы слуха, то описанные правила будут просто шагами в исчислении. Мы обнаружили, что при упорядочении этих шагов особым образом наше исчисление становится менее трудоемким. Теперь мы могли бы задать вопрос, не отражает ли порядок правил хронологической последовательности появления их в языке. Прошел ли, например, только что подвергнутый обсуждению диалект английского языка сначала стадию, на которой он был идентичен стандартному языку, а затем стадию, на которой он отличался от стандартного языка только наличием гортанных взрывных, согласно правилу 1, но отсутствием прерывных, образованных по правилу 2?
Если порядок правил можно рассматривать в этом свете, тогда предложенный критерий простоты описания становится важным средством для понимания истории языков, так как он дает нам возможность реконструировать различные стадии развития языка даже при отсутствии внешних доказательств, таких, например, какие представляют записи речи или заимствования из других языков.
Этот взгляд на фонологические правила языка отнюдь не является новым. Мне бы хотелось доказать, что реконструкция истории европейских языков, которая явилась, по-видимому, наиболее важным достижением лингвистики девятнадцатого столетия, оказалась возможной только благодаря использованию предложенного критерия экономии для установления порядка в дескриптивных формулировках; было принято допущение, что установленный порядок отражает их относительную хронологическую последовательность. Наиболее наглядно это можно, пожалуй, проиллюстрировать на примере законов Гримма и Вернера, которые с полным основанием относятся к числу самых серьезных достижений в исследованиях по индоевропеистике. Эти законы описывают стадии эволюции германских языков, происшедших из индоевропейского праязыка,— стадии, которые, как это следует заметить, не подтверждены никакими внеязыковыми доказательствами.
Предполагается, что индоевропейский праязык должен был обладать единственным фрикативным согласным [s], который был глухим, и довольно сложной системой взрывных, из которых для наших целей необходимо рассмотреть только два — глухой и звонкий. Законы Гримма и Вернера описывают то, что произошло с этими согласными в процессе эволюции германских языков.
Интересующая нас часть закона Гримма состоит из двух правил, формулируемых следующим образом:
Г.-l. В определенных контекстах, удовлетворяющих некоторому условию Сь природа которого не интересует нас в данном случае, негласные, согласные, глухие прерывные (взрывные) становятся непрерывными (фрикативными). (Именно в соответствии с этим законом можно сказать, что англ. five сходно с греч. pente, русск. pjat’ «пять» и скр. рапса).
Г.-2. Негласные, согласные, звонкие прерывные (взрывные) становятся глухими. (Г.-2 устанавливает соответствие между англ. ten и греч. deka, русск. desjat’ «десять» и скр. daga).
Существующие учебники подтверждают, что эти два правила вошли в язык именно в указанном порядке, потому что (и это особенно важно, поскольку нет иных доказательств), если бы Г.-2 действовал раньше Г.-l, то глухие непрерывные, образованные по правилу Г.-2, стали бы прерывными, согласно правилу Г.-l. Такая аргументация, как мы видим, соответствует изложенным выше соображениям (см. пример, взятый из английского диалекта). Единственный новый фактор здесь состоит в том, что порядку правил, который не имел хронологического значения в английском примере, здесь придано хронологическое значение.
В более позднее время германский язык подвергся влиянию закона Вернера, который можно сформулировать следующим образом:
В. В контекстах, удовлетворяющих некоторому условию С2, негласные, согласные, глухие непрерывные (фрикативные) становятся звонкими.
Если, как думает большинство из нас, закон Вернера стал действовать в языке гораздо позже, чем закон Гримма (Л-1), то мы должны допустить, что на этой стадии язык обладал глухими непрерывными двоякого происхождения: звуком [s], который пришел неизменным из индоевропейского праязыка, и глухим фрикативным, полученным в результате действия закона Гримма (правило Л-1). Тот факт, что закон Вернера применяется без различия к глухим фрикативным, полученным из этих двух источников, всегда приводился в качестве решающего аргумента для доказательства того, что закон Вернера действовал позже закона Гримма. Однако этот аргумент будет иметь вес только в том случае, если мы изберем такой критерий экономики описания, который будет совпадать с установленным выше. Приведенные факты можно исчерпывающе объяснить (как и в случае с именами существительными множественного числа в английском языке) следующими тремя неупорядоченными правилами.
В контекстах, удовлетворяющих условиям Сі и С2, негласные, согласные, глухие прерывные становятся звонкими и непрерывными.
В контексте С2 звук Ш, то есть полный перечень его признаков, требующий упоминания целого ряда характеристик, становится звонким.
С помощью предложенного критерия простоты мы должны отвергнуть неупорядоченные правила, так как они требуют большего количества признаков по сравнению с упорядоченными альтернативами Г.-l и В. Поскольку не имеется внеязыковых доказательств того, что язык изменялся согласно законам Гримма и Вернера, то принятие этих законов как исторического факта полностью базируется на соображениях простоты. Но соображения простоты,— безусловно, соображения очень веские, ибо, как заметил профессор Куайн, мы конструируем картину нашего мира на основе того, «что существует плюс простота законов, посредством которых мы описываем и экстраполируем то, что существует».
Общеизвестно, что наблюдается поразительное различие и столь же поразительное сходство между естественным языком, таким, как английский, и языками или системами обозначений в математике. На одном полюсе мы имеем богатства сложнейших систем естественных языков, особенно на уровне структуры предложения, на другом — простоту и изящество математических обозначений. Некоторые из синтаксических особенностей английского языка имеют четкую функцию указателя роли и соподчинения, но до сих пор еще не ясно, почему существует такое разнообразие средств указания на роль и соподчиненность, если можно воспользоваться одним-единственным средством, которое избрал Лукасевич или которое принято в польской префиксальной системе нотации. Далее, можно привести длинный список других сложностей английского синтаксиса, функции которых совершенно непонятны. Многие типы прерывных составляющих могут служить примерами этих синтаксических приемов без какой-либо определенной функции.
Для объяснения многих из не раскрытых ранее особенностей английского синтаксиса[83] мы воспользуемся так
называемой «гипотезой глубины». Психологи измерили то, что они называют объемом непосредственной памяти. Мы способны запомнить с одного взгляда и правильно воспроизвести приблизительно семь взятых наугад десятичных цифр, около семи не связанных между собой слов, •около семи наименований. Это уже давно известно, а специально изучено в Гарвардском университете Джорджем Миллером[84]. По-видимому, нам приходится считаться с этим ограничением, когда мы говорим. Мы можем вспомнить сразу лишь около семи грамматических или синтаксических ограничений. Гипотеза глубины гласит, что, приняв во внимание ограничение памяти, можно понять многие сложные черты английского синтаксиса. Синтаксис английского языка располагает разнообразными средствами для того, чтобы автоматически удерживать высказывание в пределах, определяемых ограничением, а также многими средствами, позволяющими успешно обойти это ограничение таким образом, чтобы компенсировать потерю экспрессивной силы из-за указанной ограниченности объема непосредственной памяти. Гипотеза глубины предсказывает, что все языки имеют усложненные синтаксические особенности, служащие той же цели. Это утверждение требует проверки.
Ограничение объема непосредственной памяти не должно, по-видимому, оказывать какого-либо влияния на структуру математических обозначений, поскольку они являются обозначениями письменными.
Чтобы понять, каким образом ограничение объема памяти влияет на синтаксическую структуру языка, нужно обратиться к простой модели построения предложения. Эту модель можно легко запрограммировать для вычислительной машины. Она и в самом деле была предназначена для использования в системе механического перевода. Важные в лингвистическом отношении особенности этой модели можно понять, лишь приняв во внимание два допущения. Первое допущение: для описания синтаксиса языка необходимо применить анализ по непосредственно составляющим. Но поскольку такое описание является статическим, нужно ввести еще и аспект времени (то есть поря-„ док следования операций для данной модели) — и это
второе допущение. Оно предполагает, что слова предложения появляются каждое по одному в их естественной временной последовательности, то есть слева направо, в соответствии с обычной орфографией, и что для правил грамматики непосредственно составляющих применяется метод расширения, то есть раскрытие сверху вниз, как показано на наших диаграммах.
S —• NP + VP
NP Т + N
VP ■> V + NP
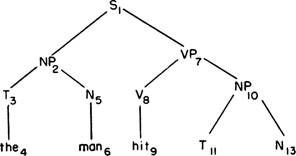
the,2 ball|4
Рис. 1. Построение предложения включает применение грамматических правил, подобных тем, какие приведены справа. Для этих правил применяется метод расширения, и расширяются они слева направо. Номера индексов показывают порядок применения правил.
у -------------------------------------------------------------------------- * the
fsj .■ ■» man
N ► ball
V * hit
На рис. 1 показано, как действовали бы эти допущения при реальном построении предложения с помощью данной модели. Где-то в памяти машины хранится перечень правил грамматики непосредственно составляющих, подобных приведенным справа, который обеспечивает непосредственно составляющие для каждой конструкции данного языка. Предполагается, что этот перечень правил является конечным и что в лингвистическом отношении безразлично, в каком порядке эти правила перечисляются. Любой порядок годится. Например, может оказаться удобным алфавитный порядок. На вершине дерева находится символ S, обозначающий предложение. Первое правило, которое следует применить, предписывает расширить символ S до его непосредственно составляющих: именной группы (NP) — подлежащего и глагольной группы (VP) — сказуемого. Затем именная группа подлежащего расширяется до артикля (Т) и имени (N), и так далее (в соответствии с приведенными правилами). Порядок расширения конструкций до их составляющих обозначается индексами. Этот порядок во всех случаях предусматривает в первую
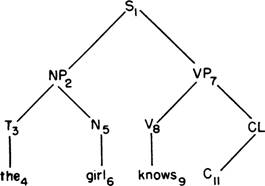
Рис. 2. Неограниченно длинные предложения можно получить путем повторного применения определенных правил. Здесь правило S-^NP+VP применялось в узле 1 и затем вновь в узле 13.
очередь расширение левостороннего члена каждой конструкции, а после того, как будет достигнут конец ветви,— возвращение к следующему, более высокому, правостороннему члену. Таким путем слова производятся в их обычном порядке, слева направо.
Хотя принятая нами грамматика состоит из конечного числа правил, наша машина благодаря своим особенностям может произвести любое предложение, выбранное из бесконечного множества предложений. Она делает это путем повторного применения правил неограниченное число раз, вновь и вновь создавая придаточные предложения внутри предложения. Рис. 2 показывает, как одно и то же правило может быть применено дважды. На вершине дерева предложение S расширяется до NP и VP, а справа оно расширяется до NP и VP снова, но уже в зависимом предложении. Так может продолжаться без конца. Например: The girl knows that the papers reported that the woman said that the man... и т. д. «Девочка знает, что газеты сообщили, что женщина сказала, что мужчина...».
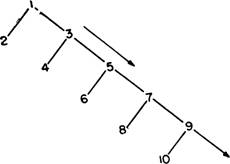
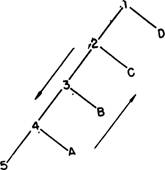
Каким образом ограниченность объема памяти отражается в нашей модели, можно понять из нижеследующего. При выдаче предложения машина должна как-то запоминать, что ей предписывается правилами грамматики данного языка делать далее. Расширив S до подлежащего NP и сказуемого VP, она переходит к расширению самой левой составляющей NP. Но где-то в своей памяти она должна записать информацию о том, что когда она закончит со всеми ветвями, зависящими от NP, она обязана расширить некоторое VP, так как иначе она не получит грамматически правильного английского предложения. Подобным же образом после расширения NP до Т и N она должна отослать N в запоминающее устройство на то время, пока она расширяет Т. Таким образом, всякий раз, когда машина спускается по левой ветви, она должна записывать в своей оперативной памяти один символ для каждого шага, сделанного вниз по этой ветви. На левой диаграмме рис. 3 машина работает над узлом 5 некоторого предложения. Она отослала в запоминающее устройство четыре названия узлов, отмеченных кружками. На диаграмме справа этаже самая структура показана на более поздней стадии. Машина закончила с узлом 5, получила узлы 6 и 7 из своей памяти и расширила их, а теперь работает над узлом 11. Она все еще имеет в своей памяти четыре символа: два из записанных первоначально и два новых, которые появились в результате расширения узлов 7 и 10. В конечном счете ей придется вернуться и расширить их все.
Если в соответствии с правилами грамматики разрешается производить неограниченно длинные предложения (или, что то же самое, если перечень предложений бесконечен), то, спрашивается, какого объема оперативная память потребуется машине? Неограниченно большого? Попробуем исследовать этот вопрос. На рис. 4, слева, показана регрессивная структура. Мы называем ее регрессивной структурой потому, что машине приходится спускаться по стволу, расширяя узлы 1, 2, 3, 4 и 5 и записы-
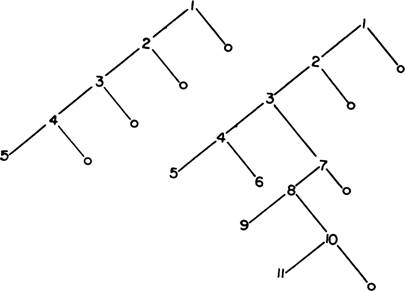
Рис. 3. Применяя правила, необходимо удерживать в оперативной памяти символы, обеспечивающие грамматическое завершение предложения. Кружками представлены названия узлов, которые сохраняются в оперативной памяти на указанных двух стадиях построения предложения. Цифры показывают порядок применениі правил.
Регрессивная Прогрессивная
структура структура
Рис. 4. Регрессивная структура, подобная представленной слева, требует, чтобы запоминался дополнительный символ для каждого шага вниз. Структура, имеющая глубину, равную четырем, требует запоминания четырех символов А, Ву С и D. Прогрессивная структура, подобная представленной справа, может расширяться неограниченно, путем использования оперативной памяти, которая может сохранить только один символ.
вая в своей памяти некоторое количество символов (в данном случае четыре, потому что имеются четыре нерасширенных ветви), после чего она должна вернуться наверх и расширить по очереди ветви, отходящие от А, 5, С и D. Данная регрессивная структура имеет глубину, равную четырем. Глубина узла численно равна количеству символов, записанных в оперативной памяти непосредственно перед тем, как очередной узел должен быть расширен. Справа представлена прогрессивная структура. Машина может продолжать спускаться вдоль главного ствола, производя расширения по мере продвижения и ни разу не возвращаясь назад, причем при каждом шаге она отсылает в оперативную память только один символ, всякий раз выбирая его снова из памяти й расширяя его. Понятно, что регрессивные структуры, становясь все более длинными, требуют все большего и большего запоминания, тогда как прогрессивные структуры этого не требуют. Последние могут продолжаться бесконечно, удовлетворяясь минимумом памяти.
Остается описать схему, представленную на рис. 5. Если бы память позволяла запоминать одновременно только три символа, то можно было бы построить структуру, подобную представленной на рис. 5, но было бы невозможно построить такую структуру, которая проникла бы за пунктирную линию. Мы уже говорили, что человек может запомнить одновременно и воспроизвести только около семи наименований. Английские предложения можно представить деревьями, которые как бы ограничены пунктирной линией на глубине, равной примерно семи. Таким образом, структура английского языка оказывается внутренне асимметричной в том смысле, что она не располагает такими возможностями ветвления влево, какие имеют место при ветвлении напразо. Интересно, что системы обозначений в математике и символической логике не имеют этого ограничения. По существу своему они являются письменными языками. Проблема запоминания дальнейших шагов разрешается математиком при помощи просмотра того, что он написал; продолжая записывать, он не обязан хранить все написанное в своей памяти. Напротив, при устном общении приходится держать в голове высказанную часть сообщения, имея ограничение на объем непосредственной памяти, равное приблизительно семи названиям.
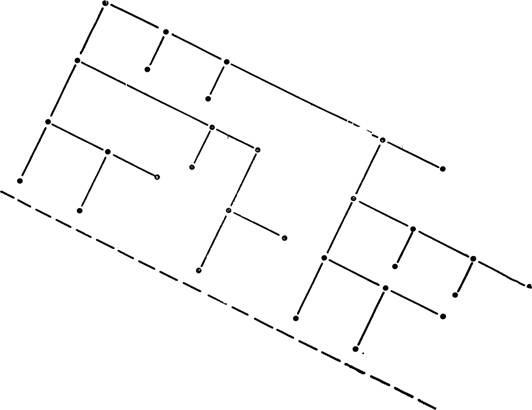
Рис. 5. Если оперативная память может хранить только три символа, то структуры, которые могут производиться при этом, ограничиваются глубиной, равной трем, и никогда не смогут проникнуть за пунктирную линию.
Утверждать, что очень глубокие структуры допускаются в английском языке, но не употребляются из-за ограничения памяти, нельзя. Суть дела здесь в следующем: грамматика английского языка строится таким о0разом, что в ней исключаются слишком глубокие конструкции, а взамен их вводятся конструкции меньшей глубины. Именно этим и объясняется большая сложность английского языка по сравнению с системами обозначения в математике и символической логике.
Одной из наиболее удивительных особенностей английского синтаксиса является связь системы частей речи с правилами порядка слов. Мы имеем в виду следующее. Бозьмем, к примеру, предложение Very clearly projected
pictures appeare «Очень четко спроектированные [на экран] изображения появились». Это чисто регрессивная структура с глубиной, равной четырем.
На рисунке 6 показано, как строится это предложение. Считая вниз от вершины, мы имеем сначала глагол «appeared», затем существительное «pictures», затем прилагательное «projected», затем наречие «clearly» и наконец вторичное наречие «very» особого, ограниченного класса.
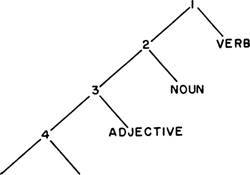
SEC- ADVERB ADVERB
Рис. 6. Иерархия частей речи в английском языке служит для подсчета регрессивных шагов и помогает избежать предложений слишком большой глубины. В английском языке отсутствует аналогичный подсчет в прогрессивном направлении.
Дальше продолжать построение этой структуры в регрессивном плане весьма затруднительно. Система частей речи обеспечивает способ автоматического подсчета шагов вниз по регрессивной ветви и прекращения расширения конструкции прежде, чем она пересечет предел глубины. Ясно, что эта система представляет собой схему подсчета и не связана со значением слов, потому что нередко оказывается возможным передвигать слова вниз и вверх по этой лестнице, относя их в соответствии с этим то к одним, то к другим частям речи. Например, в сочетании a very clear projection «очень четкая проекция [на экран]» причастное прилагательное projected «спроектированный» становится существительным projection «проекция», а наречие clearly «четко» — прилагательным clear «четкий». Неизменными остаются и категории частей речи, которые служат для учета длины регрессии. Для английского языка характерно, что он не располагает средствами для подсчета в прогрессивном направлении.
Существует немало прогрессивных конструкций, которые могут продолжаться бесконечно. Прежде всего это координация (co-ordination) [^сочинительная связь], которая, например, имеет место в длинной цепочке коорди- нативных именных групп. В прогрессивном направлении она может продолжаться бесконечно. Затем нужно отметить модель накапливания нескольких прилагательных перед именем существительным. Но когда мы сталкиваемся с подчиненными придаточными предложениями, мы должны рассмотреть их более детально.
Рис. 7. Неограниченное применение правила А, соответствующее схемам, показанным слева, привело бы к структурам, превышающим любой предел глубины. Эти структуры грамматически неправильны. Неограниченное применение в соответствии со схемами, данными справа, не приводит к беспредельному возрастанию глубины.и поэтому они безопасны.
На рис. 7 представлены разнообразные структуры, предполагающие повторное применение правила А. Структуры, находящиеся слева от пунктирной линии, были бы грамматически неправильными, потому что требуемая ими возможность неограниченного применения правила А привела бы к неограниченному возрастанию глубины. Таким образом, мы были бы введены в заблуждение, стремясь к достижению слишком большой глубины. Структуры, находящиеся справа, не приводят к ошибке, поскольку они могут встретиться на самом деле. В английском языке имеется значительное количество структур, включающих подчиненные придаточные предложения, которые могут повторяться в неограниченном числе. Эти структуры аналогичны данным справа. В качестве примера приведем придаточное дополнительное предложение: I watched him watch Mary watch baby feed the kitten «Я наблюдал, как он наблюдал, как Мэри наблюдала, как ребенок кормил котенка». Или придаточное дополнительное предложение другого типа: I imagined him hearing the announcer reporting Bill catching Tom stealing third base «Я вообразил, что он слышал, как диктор сообщил, что Билл «запятнал» Тома, который пытался достичь третьей «базы дома»». Или, например, придаточное предложение с that [относительное «что»]: John said that Paul said that Bill said that he had won the race «Джон сказал, что Поль сказал, что Билл сказал, что он выиграл гонки». Но придаточное предложение с that можно поставить также в качестве придаточного-подлежащего перед глаголом, и это уже будет регрессивная конструкция. Ее нельзя повторять неограниченно, например: That it is true is obvious «То, что это справедливо, очевидно». Теперь рассмотрим два придаточ- ных-подлежащих с that: That that it is true is obvious isn’t clear «То, что то, что это справедливо, очевидно, не ясно». Грамматически это построение неправильно. Эта структура расположена в левой половине рис. 7 ближе к пунктирной линии. Вместо нее в английском языке употребляется «вводящее» it — одно из типичных усложнений английского синтаксиса: It isn’t clear that it is obvious that it is true «Не ясно, что очевидно, что это справедливо».
Наконец, надо сказать, что существует еще одна прогрессивная структура, которую можно расширять неограниченно — это дополнительное придаточное предложение с what (вопросительное «что»): Не knows what should have been included in what came with what he ordered «Он знает, что следовало бы включить в то, что пришло с тем, что он заказывал». Но если придаточное предложение с what выступает в позиции подлежащего, тогда повторение не должно иметь места. Вот попытка использовать сразу три придаточных-подлежащих с what: What what what he wanted cost would buy in Germany was amazing «Что, что, что он хотел бы заплатить, купило бы в Германии, было поразительно». Это грамматически неправильное построение. Оно является регрессивной структурой. Вместо нее, используя три принятые в грамматике усложненные структуры — прерывную составляющую, пассивный залог и номинализацию,— можно построить заменяющую ее прогрессивную структуру: It was amazing what could be bought in Germany for the cost of what he wanted «Было поразительно, что можно было бы купить в Германии за ту цену, за которую он хотел».
Прерывные составляющие в английском языке служат, по-видимому, для того, чтобы отложить построение потенциально глубоких структур до момента, когда будет достигнута точка наименьшей глубины, осуществляя это путем перенесения структур из левой части дерева в правую. Приведем интересный пример. Если пассивный залог используется таким образом, что подлежащее активного залога может оставаться невыраженным, тогда построение с большой мерой глубины можно передвинуть на место подлежащего, где оно приобретает начальную величину глубины, равную единице. Например: In a recent paper, measurements of the effect of alloying on the superconductive critical temperature of tin were presented «В недавней статье результаты измерения влияния примесей на критическую температуру сверхпроводимости олова были изложены». Такие структуры получили у грамматистов название «сверхгромоздких» («top heavy»). В качестве альтернативы подлежащее нередко расщепляется на прерывные составляющие: In a recent paper, measurements (were presented) of the effect of alloying on the superconductive critical temperature of tin «В недавней статье результаты измерений (были изложены) влияния примесей на критическую температуру сверхпроводимости олова». Здесь, в результате синтаксического усложнения, предложная группа, определяющая подлежащее, ставится после сказуемого, и таким образом мы получаем грамматически правильный, но «нелогичный» порядок слов: подлежащее, сказуемое, определения к подлежащему. Из-за недостатка времени я ограничусь этими примерами, хотя их существует гораздо больше.
На основании концепции, изложенной в настоящей статье, мы утверждаем, что английские предложения можно производить с помощью машины с конечным числом состояний. Синтаксис английского языка не представляет собой бесконечного списка замысловатых усложнений, хотя в нем и сохраняются некоторые следы прошлого. Но английский язык не оказывается и абстрактной формальной системой, выступающей наравне с определенными изящными системами обозначений в математике. Вместо этого он предстает как чрезвычайно хорошо построенное орудие общения, обладающее многими искусными инновациями, позволяющими приспособить его к возможностям его носителей и обойти, насколько возможно, ограничения человеческой памяти.
Остается выяснить, насколько удачно можно применить нашу гипотезу к другим языкам. Я надеюсь, что некоторые из вас заинтересуются проведением таких экспериментов. Несомненно, что другие языки отличаются от английского. У них может не оказаться именно тех черт, какие мы объяснили на основе гипотезы глубины. Они могут обладать особенностями, прямо противоположными тем, которые присущи английскому языку, например наличием послелогов вместо предлогов. Не смущаясь этим, следует подвергнуть анализу в свете нашей гипотезы общую структуру синтаксиса рассматриваемого языка, поскольку обычно как раз взаимодействие ряда особенностей языка и препятствует тому, чтобы то или другое предложение становилось слишком глубоким. Следует ожидать, что все языки располагают способами ограничения регрессии, способами сохранения глубины, а также способами, которые дают возможность обойти ограничения объема памяти, для того чтобы сберечь экспрессивную силу.
В последней части гипотезы предлагается причислить явления глубины к списку уже известных факторов, влияющих на развитие языка. Фактор глубины в языковых изменениях, если таковой существует, должно быть, нетрудно обнаружить, и он, вероятно, быстро проявится, если сравнить грамматические описания различных периодов в развитии языка.
Еще по теме М. Халле О РОЛИ ПРОСТОТЫ В ЛИНГВИСТИЧЕСКИХ описаниях* [81]:
- 5. Методы лингвистического картографирования и основные понятия лингвистической географии.
- Конвенционализм и понятие простоты
- Простота и сила
- Простота евклидовой геометрии
- Устранение эстетического и прагматического понятий простоты
- 7. Последнее слово на тему ясности – простота.
- (ЛИНГВИСТИКО-АКУСТИЧЕСКОЕ ИССЛЕДОВАНИЕ) М. Халле
- Простота и степень фальсифицируемости
- Р. Якобсон и М. Халле ФОНОЛОГИЯ И ЕЕ ОТНОШЕНИЕ К ФОНЕТИКЕ[183]
- Р. Якобсон, Г. Ж. Фант и Ж. Халле ВВЕДЕНИЕ В АНАЛИЗ РЕЧИ [180]
- Второй паралогизм, касающийся простоты
- От простоты к сложности: постнеклассическая революция в науке From simplicity to complexity:postnonclassical revolution in science
- Лингвистическое обеспечение
- Лингвистическое источниковедени
- Роли.
- 1.3. Роли и труд менеджера