СЕМАНТИЧЕСКИЕ СЕТИ
Разработка понятия семантической сети обычно приписывается Куиллиану (Q и і 1 1 і а п, 1968) (хотя структура,
использованная в системе SIR Рафаэла (1964), как показано в первой части статьи Ю.
Чарняка, имеет во многом такой же вид, и мы будем говорить о ней как о семантической сети). В своей наипростейшей форме семантическая сеть есть совокупность точек, называемых узлами; каждая из них может мыслиться как представление некоторого понятия (точное определение понятия здесь для нас несущественно; достаточно представлять его себе как некоторую сущность, о которой хранится информация). Каждый узел может иметь имя, например: boy ‘мальчик’ или gift ‘подарок’. Узлы без имен в общем случае соотносятся с понятиями, которые не представимы с помощью простого имени в английском языке, например: the cute little girl with the long blond curls who lives around the corner ‘миловидная маленькая девочка с длинными белокурыми вьющимися волосами, которая живет за углом’. Точка может связываться посредством направленной дуги (или, если угодно, стрелки), которая называется отношением, с любой другой точкой сети. Это отношение получает некоторое обозначение (помету). Графически это может выглядеть так:R

Схема читается следующим образом: R связывает А с В.
Принятая интерпретация этой структуры сводится к тому, что отношение R имеет место между А и В, или А находится в отношении R к В. Заметим, что В не обязательно находится в отношении R к А. Именно поэтому дуга должна быть направленной и представляться в виде стрелки. Например, если А — это Anna, В — это Bill, a R — это LIKES ‘любит’, мы имеем*
LIKES
anna S' "ч bill
Вполне возможно, что Анна ни в малейшей степени не интересует Билла, поэтому мы не можем заключить следующее:
LIKES
ANNA ЧЧ\ BILL
Любой узел может быть связан с произвольным числом
других узлов, каждый из них — с любым числом других узлов и т.
д. Если добавлять все большее и большее число узлов и дуг, графическое представление становится похожим на сеть из линий, поэтому оно получило название семантической сети (семантической, поскольку исторически такие сети были использованы прежде всего для представления значений выражений на естественном языке).Сеть может строиться для представления очень сложных взаимоотношений, например, в:
ISA

Charles представляет некоторого конкретного члена множества всех мальчиков (ISA означает is а ‘есть некоторый’, boy — ‘мальчик’).
Charles hit the blond haired girl.
‘Чарльз ударил девочку с белокурыми волосами.’ может быть представлено как:
BOY
'мальчик'
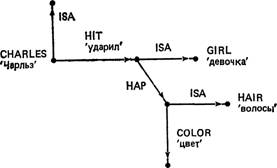
BLOND
'белокурый'
где НАР означает has-as-part ‘имеет в качестве части’. Заметим, что здесь имеются непоименованные узлы, представляющие конкретную девочку и ее волосы. (Таким непоименованным узлам иногда приписываются произвольные символы типа Cl, С2 и т. д. для внутренних ссылок.) Если добавить дополнительную информацию о том, что девочка
Минимальной единицей информации в семантической сети является тройка ARB. Но базисная единица — это узел, или понятие. Понятие обладает информационным содержанием лишь в силу того, что оно связано с другими узлами. Можно считать, что информация существует в отношениях. Понятие, не участвующее ни в каких отношениях, лишено содержания, и мы считаем, что доступ к нему закрыт. Это понятие, о котором ничего не известно (действительно, это весьма странное понятие).
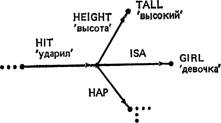
была высокая, узел, репрезентирующий девочку, будет расширен:
Слово ’’понятие" (concept) обычно используется для обозначения как общих, так и конкретных понятий. Конкретное понятие, подобное этому листу бумаги или конкретному мальчику, который ударил белокурую девочку, в нашем последнем примере, мы будем называть ”элементом“ ("token").
Неконкретные понятия будут называться ”типами“ ("types"). Часто неконкретные понятия являются типами- классами, например GIRL и HAIR. В других случаях они могли бы, вероятно, тоже интерпретироваться как классы (TALL = класс высоких вещей?), но мы находим такие интерпретации натянутыми и не будем настаивать на том, что все ’’типы" являются классами. (Читатель, знакомый со статьей Куиллиана, может заметить, что принятое нами употребление терминов ’’тип" и ’’элемент" несколько отличается от того, которое мы находим у Куиллиана.) Мы видели в нашей последней схеме, как элемент (the blond girl) был связан с соответствующим типом (girl) посредством отношения ISA (для выражения этого отношения используются также обозначения IS-A и ELEMENT). В этих случаях мы можем сказать, что узел-элемент (blond girl) ’’является элементом" соответствующего узла-типа (girl). Типы (girl), которые являются подтипами других типов (human ‘человеческий’), могут связываться со своим более крупным типом посредством отношения SUPERSET ‘надмножество’ (S. S. или другие эквивалентные обозначения).Важно подчеркнуть разграничение между типом и элементом. Системы, в которых оно игнорируется, обычно сталкиваются с трудностями, связанными с тем, что в них невозможно провести различие между сущностью (элементом) и множеством (типом), которое не имеет членов. Чтобы пояснить это, предположим, что у нас имеется (неправильная) структура (1) следующего вида:
(1) ANIMAL
'животное'
/К
ISA ISA ISA
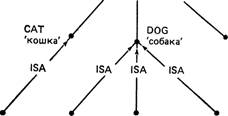
PIG
'свинья'
FIDO
ROVER
REX
CLEO
Это подструктура некоторой базы данных. Если бы системе, использующей эту базу данных, был задан вопрос:
How many animals do you know about?
‘О скольких животных Вы знаете?’ она могла бы ответить ‘о трех’, подсчитав непосредственные подмножества узла ANIMAL. Или она могла бы ответить ‘о пяти’, пройдя по всем цепочкам с отношениями ISA до их концов (CLEO, FIDO, ROVER, REX и PIG).
Но распознать, что в действительности имеется четыре конкретных животных (их клички Cleo, Fido, Rover, Rex), невозможно, если только не пометить каким-нибудь способом типы и элементы, например используя два различных отношения — ISA и SUPERSET. Альтернативный путь может состоять в том, чтобы пометить каждый узел особым обозначением, указывающим, является ли он классом или элементом.Обсуждая последние примеры, мы впервые конкретно коснулись активного аспекта памяти. В этом примере, для того чтобы обосновать форму, которую должна иметь сеть (необходимость разграничения ’’тип — элемент"), мы должны были обратиться к проблеме поиска информации (выяснения того, о скольких животных имеются сведения в системе). Действительно, популярность сетей вначале была во многом обязана их способности существенно облегчать определенные виды поиска и вывода. В частности, они могут Великолепно справляться с выводами типа "Сократ — чело
s.s,
as.
BIRD
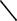
ANIMAL
НАР
\
НАР
\
ч
WING
SKIN
YELLOW
\
CANARY-
COLOR
век, все люди смертны". Здесь мы рассмотрим пример "канарейка — птица, все птицы имеют крылья".
Если эту схему рассматривать как часть сети, то цвет канарейки можно найти простым прохождением стрелки COLOR от CANARY ‘канарейка’ к YELLOW ‘желтый’. Чтобы определить, имеет ли канарейка крылья (заметим, что НАР не связывает здесь CANARY и WING ‘крыло’), необходимо только заметить, что BIRD НАР WING и CANARY
S. S. BIRD, следовательно, канарейки должны тоже иметь крылья. Аналогично, повторив еще раз силлогическое рассуждение, можно установить, что канарейки имеют кожу (skin). Таким образом, для некоторых ситуаций семантические сети обеспечивают естественный метод вывода.
Можно назвать еще два свойства семантических сетей, которые способствовали росту их популярности. Во-первых, семантические сети подсказывают некоторые способы сокращения объема информации, подлежащей хранению. Нет необходимости специально отмечать, что канарейки имеют крылья, и вороны имеют крылья, и малиновки имеют крылья, и утки имеют крылья. Нужно только, чтобы каждое такое свойство было связано с самым общим типовым узлом, который обладает этим типичным свойством (в нашем случае этот узел — BIRD ‘птица’). Привлекательность такого представления заключается еще в том, что оно эксплицитно показывает, каковы общие черты большинства птиц. Вторым фактом, который послужил толчком для распространения идеи семантической сети, был ряд результатов психологических экспериментов, из которых следовало, что хранение информации в мозгу человека осуществляется, вероятно, тоже в виде сетей (Collins and Q и і 1 1 i- a n, 1968); правда, позднее были получены и иные выводы (В і s с h о f, 1978). Было замечено, что время ответной реакции человека устойчиво возрастает по мере того, как вопросы затрагивают свойства все более и более общего характера (например, канарейки желтые, имеют крылья, имеют кожу и т. д.). Именно это и предсказывают семантические сети, так как более общие свойства находятся дальше от конкретных элементов и, чтобы найти их, нужно просмотреть больше узлов.
ОБОБЩЕНИЯ СЕТЕЙ
Первоначально казалось, что семантические сети дают нечто ценное для всех и являются настоящей панацеей для психологов и специалистов по вычислительной технике. Однако более поздние психологические результаты показали, что сами по себе сети не являются хорошими психологическими моделями, а специалисты по вычислительной технике скоро столкнулись с формальными трудностями, вытекающими из того, что по мере рассмотрения более сложных данных сети, применявшиеся в ранних системах, скоро оказались в ряде отношений недостаточными: чтобы они и дальше могли быть жизнеспособными моделями, требовались ограничения или дополнения в базисной структуре.
Некоторые из этих формальных проблем решаются в модели памяти, развиваемой Норманом, Линсеем и Румель- хартом (см. Norman & Rumelhart, 1975) и составляющей ядро предполагаемой комплексной психологической модели. Память в их понимании предусматривает некоторые усовершенствования и расширения по сравнению с исходным понятием семантической сети.
Одна из проблем, связанных с описанным выше представлением сети, возникает при моделировании фактов типа John hit Магу ‘Джон ударил Мэри’, которые мы представляем следующим образом:
HIT

Возникающая здесь трудность заключается в том, что у нас нет возможности добавить дополнительную информацию об этом событии, информацию о том, когда он ударил ее, где (как в смысле локализации удара на теле, так и в смысле места, где произошло действие в целом), была ли использована палка и т. д. Эта трудность может быть устранена посредством введения концептуальных узлов не только для объектов, но и для событий. Тогда мы получим:
FIST
'кулак'
/
INSTRUMENT
AGENT / OBJECT
JOHN -ч .............................. — HIT---------------------------------------------- MARY
LOCATION TIME
'местоположение' 'время'
/ \
THE PARK WEDNESDAY
'ларк' ' среда'
MORNING
'утро'
3 a.m.
'3 часа дня'
Заметим, что если раньше мы различали, кто ударил кого, помещая одно понятие в конце стрелки, обозначающей отношение, а другое — в начале, то теперь так сделать нельзя, поскольку теперь John и Магу каждый имеют свою
собственную стрелку. Вместо этого мы проводим данное
разграничение посредством эксплицитного называния одного элемента агенсом, а другого — объектом, придавая представлению вид, напоминающий падежную структуру.
Но и это представление не разрешает всех проблем. Рассмотрим представление для следующего предложения:
John hit Mary and Bill hit Sue.
‘Джон ударил Мэри, а Билл ударил Сью.’
JOHN MARY
AGENT OBJECT
X /
HIT
X X
AGENT OBJECT
X X
BILL SUE
Теперь уже неясно, кто ударил кого и сколько таких действий произошло в действительности. (Не годится здесь и такое решение, чтобы было два узла, помеченных HIT, поскольку, при наличии одинаковых помет, не будет возможности различить их при поиске.) Чтобы обойти эту трудность, мы должны разграничивать конкретные действия типа "ударить" и понятие "ударять вообще". Тогда получаем:
BILL
/
АО ENT
ACT-QF HIT ---
OBJECT
\
SUE
^ JOHN
\
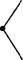
AGENT
ACT-OF
OBJECT
/
MARY
Узел HIT в центре представляет понятие ‘ударять’. Два конкретных происшествия, когда кого-то ударили, связаны с общим понятием HIT посредством отношения ACT-OF ‘действие типа’. Отношение ACT-OF между понятиями, отражающими действие, аналогично отношению ISA между понятиями, отражающими предметы.
Узел HIT в (2) мог бы быть расширен:
/ \
AGENT OBJECT
/ \
X Y
Эта информация, как показывает ее местоположение в схеме, относится к общему понятию ‘ударять’. Она означает, что без указания отношений AGENT и OBJECT данное понятие является неполным (или даже невообразимым). Следовательно, каждое отдельное действие типа HIT (связанное отношением ACT-OF) должно иметь и стрелку AGENT, и стрелку OBJECT. Такие обязательные атрибуты могут мыслиться как аналоги глубинных падежных отношений [57], за исключением того, что здесь они выступают как требования к памяти, а не к самой языковой структуре. Заметим, что представление в виде семантической сети вполне определенно предполагает использование именно падежной структуры, а не позиционной структуры, как в представлении типа исчисления предикатов. Таким образом, в то время как раньше предикаты типа hit выступали как связи между узлами (или, более формально, как отношения между узлами), теперь они сами выступают в роли узлов. Так как первоначально в нашем представлении все предикаты были отношениями, мы могли употреблять эти термины во многом как синонимы. А теперь этого делать нельзя. Поэтому мы будем и дальше употреблять термин отношение для обозначения связей между узлами, тогда как термин предикат будет теперь обозначать общие понятийные узлы типа HIT. Более того, мы будем называть структуры типа (2) ”предикатными структурами", чтобы подчеркнуть тот факт, что здесь HIT является узлом (предикатом), а не связью.
Этот переход в статусе от связи к узлу будет иметь целый ряд важных последствий для использования семантических сетей, что станет ясно в процессе изложения. Сейчас же заметим, что отношения типа AGENT будут фигурировать в сети очень часто. Каждый отдельный случай осуществления практически каждого действия будет иметь отношение AGENT (или ACTANT, или какое-то другое в том же роде — употребляемые здесь термины не означают, что мы пользуемся какой-либо конкретной системой глубинных падежей).
Один из результатов введения предикатных структур состоит в том, что в семантической сети теперь может быть представлен эквивалент любого N-арного предиката, задаваемого посредством ИППП (см. часть 1-ю статьи Чарняка). До этого дополнения в семантической сети имелись эквиваленты (в виде дуги отношения) только для двухместных предикатов. Эти новые преимущества приводят, правда, к увеличению объема базы данных и, вероятно, к увеличению времени поиска. Впрочем, мы должны предупредить читателя, что, несмотря на тот факт, что все современные семантические сети используют средства, аналогичные описанным предикатным структурам, авторы таких систем продолжают проводить свои рассуждения так, как будто бы этого не было, и продолжают использовать старую нотацию в качестве сокращения для новой. Мы будем поступать так же. Однако, когда будет проводиться дуга, в действительности представляющая некоторый узел, мы будем помечать ее символом узла в виде кружка в центре дуги. Так:
HIT
/
ACT-OF
AGENT / OBJECT JOHN -ч-------------------- *------------------- —*• MARY
становится:
HIT
JOHN
MARY
Иногда возникает необходимость представлять в базе данных суждения, про которые неизвестно, истинны ли они, или даже известно, что они ложны. Например, чтобы представить:
Peter said that he went to the store ‘Питер сказал, что он пошел в магазин’
требуется, чтобы
Не went to the store ‘Он пошел в магазин’
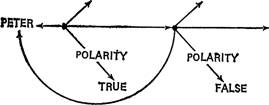
было представлено каким-либо образом в нашей сети, даже если известно, что оно ложно. Один из способов сделать это — пометить каждый предикатный узел значением истинности TRUE ‘истинно’, FALSE ‘ложно’ или UNKNOWN ‘неизвестно’. Так, Peter said that he went to the store могло бы быть представлено е следующем виде:
PETER
'Питер'
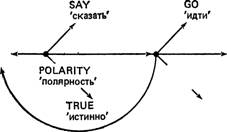
POLARITY
'полярность'
STORE
'магазин'
UNKNOWN
'неизвестно'
Здесь мы знаем, что Питер сказал это, но не знаем, действительно ли он пошел. Однако это обозначение не является достаточным для адекватного представления всех случаев. Рассмотрим схему:
SAY GO
Эта запись может пониматься двояко:
Peter said that he went to the store, but he really didn’t ‘Питер сказал, что он пошел в магазин, но в самом деле он не пошел’ и:
Peter said that he didn’t go to the store ‘Питер сказал, что он не идет в магазин’
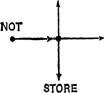
Один из способов записи, позволяющий преодолеть эту трудность, был разработан Шубертом (Schubert, 1975). Он использует логический оператор NOT ‘не’ в качестве предиката. Так:
Peter didn’t go to the store ‘Питер не пошел в магазин’
Он вводит дополнительное соглашение о том, что некоторый узел в базе данных соотносится с действительным утверждением (которое объявляется истинным) тогда и только тогда, когда на схеме не существует входящей в него стрелки. Так, на последней схеме отрицание утверждается (is asserted), а утвердительное высказывание — нет. Опираясь на это соглашение, можно по разному представить два значения, которые "скрыты" в схеме (3):
SAY GO
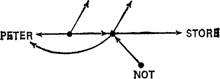
SAY NOT GO
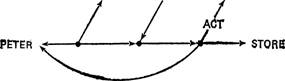
РЕАЛИЗАЦИЯ
GO
PETER
представляется в виде:
Следует остановиться на преобразовании семантических сетей в машинные представления. До сих пор мы пытались обсуждать проблематику семантических сетей, не рассматривая проблем их реального представления в вычислительной машине. Но существует по крайней мере один важный вопрос, который не встает при рассмотрении семантических сетей как графов, но который мы будем вынуждены решать, если действительно попытаемся реализовать систему, основанную на семантической сети. Поскольку в цифровой вычислительной машине нельзя хранить линии и узлы как таковые, то мы должны выбрать некоторую альтернативную схему представления. Имеется две основных возможности:
Перечислить для каждого узла все отношения, в которые он вступает (вместе с именами узлов, на которые указывают отношения), то есть:
JOHN
HIT BILL LOVES MARY
‘Джон*
‘ударил Билла* ‘любит Мэри*
Перечислить для каждого понятия-отношения все пары узлов, которые связаны этим отношением.
LOVE
JOHN, MARY JOAN, FRANK
‘Любить’
‘Джон*, ‘Мэри’ ‘Джоан’, ‘Фрэнк’
(Можно было бы, конечно, идя на значительную избыточность, использовать оба эти способа, или, может быть, некоторую их комбинацию.) Второй вариант, если применить его отдельно, работать, по существу, не будет, поскольку в результате мы получим массив, где все случаи применения каждого данного отношения сгруппированы вместе. Это было бы не так уж плохо, если бы наши отношения были того типа, который описан ранее (и использован выше), то есть типа LOVE и HIT. Для того чтобы выяснить, любит ли Джон кого-нибудь, мы могли бы просто просмотреть записи, хранящиеся под рубрикой отношения LOVE, где был бы список всех пар (А, В), таких, что A LOVES В истинно. Если JOHN появляется в левой части какой-либо пары в этом списке, то мы считаем, что он любит кого-то (а именно лицо, приписанное ему в данном списке). Однако вспомним, что LOVE представляется сейчас посредством предикатной структуры, а отношения теперь носят характер понятий типа AGENT и OBJECT. Поскольку большинство (или все) предикаты имеют AGENT, поиск в списке пар для отношения AGENT был бы эквивалентен просматриванию каждого предиката в базе данных, чтобы определить, встречается ли Джон в статусе агенса с последующей проверкой того, является ли 'найденный предикат ACT-OF LOVE. Даже после этого исчерпывающего поиска мы не знали бы, кто был ОБЪЕКТОМ его ЛЮБВИ.
LOVE 7 ACT-OF LOVE HAS-AGENT JOHN HAS-OBJECT JILL
С другой стороны, если бы все индексировались по узлам и мы хотели бы получить ответ на поставленный выше вопрос, мы просмотрели бы записи под рубрикой, соответствующей узлу JOHN, и увидели бы, является ли он агенсом какого-либо предиката:
JOHN AGENT LOVE 7
JILL OBJECT LOVE 7
Если такой предикат есть и если это ACT-OF LOVE, то мы заключаем, что Джон любит кого-то. Заметим, что LOVE 7 (отдельный случай реализации LOVE) тоже является узлом, поэтому в базе данных должен быть указатель отношений, в которые он вступает. Чтобы выяснить, кого именно Джон любит, надо просто просмотреть отношение HAS-OBJECT в списке для LOVE 7. Итак, важно, чтобы данные хранились (по крайней мере) в узловом формате.
Заметим, что в приведенном примере индексирования у нас фактически хранилась избыточная информация. Чтобы выразить тот факт, что Джон любит Джилл, мы использовали пять записей, хотя теоретически могли бы обойтись и тремя, скажем, теми, которые перечислены под LOVE 7. Однако на практике этот путь малопригоден, поскольку при такой схеме каждый раз, когда мы хотели бы узнать, любит ли кого-либо Джон, система должна была бы просматривать каждый узел и определять, обладает ли он свойствами, приписанными выше узлу LOVE 7. Очевидно, в такой ситуации экономия на сокращении избыточных записей в указателях отношений только ради того, чтобы быть втянутыми в подобный поиск, была бы ложной экономией. Но в других случаях ситуация не столь ясна. Рассмотрим отношение SUBSET ‘подмножество’. При полном индексировании хранилась бы не только информация при А о том,
что оно есть SUBSET относительно В, но также и при В — информация о том, что В есть SUPERSET относительно А. И снова мы имеем дело с избыточной информацией, но, как мы уже видели, поиск конкретного факта значительно ускоряется, если обратное отношение хранится в эксплицитном виде. Если же мы только укажем при А, что А SUBSET В, то будет очень трудно найти все подмножества узла, и наоборот. С другой стороны, представляется маловероятным, что человек всегда хранит в памяти как SUBSET, так и SUPERSET. Заметим, что на вопрос:
Dachshunds are _________ ?
‘Таксы являются_________ ?’
легко ответить ”dogs“ ‘собаками’, поэтому можно считать, что при DACHSHUND в памяти хранится соотношение (DACHSHUND SUBSET DOG) или какой-то его эквивалент. Но:
Name ten kinds of dogs
‘Назовите десять пород собак’
— гораздо более трудный случай. (Вы, может быть, и знаете десять пород, но если только Вы не являетесь знатоком собак, задание потребует от Вас определенного времени.) Это может служить свидетельством в пользу того, что при понятии DOG в памяти не хранится список всех его подмножеств. Но в целом вопрос о том, в каких же именно случаях должны храниться и прямые отношения, и обратные, остается нерешенным.
БЕГЛОЕ СРАВНЕНИЕ СЕТЕЙ И ИСЧИСЛЕНИЙ
Очевидное преимущество представления в форме исчисления предикатов заключается в том, что мы получаем в свое распоряжение всю мощь ИППП и можем осуществлять логический вывод на основе базы данных без дополнительных усилий. ИППП дает средства для представления кванторов и других понятий, выразить которые в семантических сетях совсем не просто. Попытайтесь представить в форме сети хотя бы такое выражение:
СУЩЕСТВУЕТ (Х)(Р(Х) И Q (X) ИМПЛИЦИРУЕТ R (X)) Один из недостатков ИППП как способа представления данных состоит в отсутствии хорошей организации фактов
(см. часть I статьи Чарняка). Любой, кто пытался проводить доказательства в ИППП, знает, что не всегда легко выбрать формулы и правила вывода для вычисления некоторого конкретного факта. Методики, используемые в настоящее время в программах по доказательству теорем, являются даже менее эффективными, чем действия людей (в том, что касается выбора наиболее подходящего материала). В принципе, конечно, не существует причин, которые препятствовали бы привнесению в ИППП многих структурных свойств семантической сети (многие из них действительно использовались в ИППП), но тем не менее, мы должны признать, что ИППП не оказалось такой же удобной основой для развития методов организации фактов, как семантические сети.
Хотя мы описывали семантические сети так, как будто это существенно отличный от ИППП метод представления памяти (и в самом деле, мы полагаем, что они действительно различны по цели), тем не менее можно показать, что они, в принципе, эквивалентны по выразительной силе, хотя из этого не следует эквивалентность по удобству пользования.
Чтобы убедиться в этом на интуитивном уровне, достаточно обратить внимание на сходство между списком двухаргументных предикатов ИППП и машинным представлением семантической сети, описанным в предыдущем разделе (то есть списком троек типа понятие — отношение — понятие). Однако не так легко показать, что они эквивалентны в точном смысле. Главные трудности концентрируются при этом вокруг проблемы квантификации. Каким образом выражаются в семантической сети кванторные свойства отношений? Многие сторонники семантических сетей, описывая смысл вводимых отношений в терминах квантификации, делают это весьма неопределенно, а иногда даже и непоследовательно. Например, если представление
НАР
HUMAN

HEART
является подструктурой базы данных, то обычная его интерпретация состоит в том, что все люди (HUMAN) имеют сердце (HEART). Но если в базе данных имеется представление
MAN

* FOOTBALL
то нам говорят, что это означает, что мужчины иногда играют в футбол. (Или, более точно, мы считаем, что в то время как каждый человек имеет сердце, если специально не утверждается обратное, то в футбол играют лишь некоторые мужчины.) При ближайшем рассмотрении оказывается невозможным приписать отношениям некую простую интерпретацию, которая покрывала бы все возможные квантификации этого отношения. Чтобы убедиться в этсм, заметим, что у двухместного пргедиката в исчислении предикатов может быть шесть разных квантификаций:
(4) а) ДЛЯ ЛЮБОГО (X) (ДЛЯ ЛЮБОГО (Y) (RX, Y))
б) ДЛЯ ЛЮБОГО (X) (СУЩЕСТВУЕТ (Y) (RX, Y))
в) ДЛЯ ЛЮБОГО (Y) (СУЩЕСТВУЕТ (X) (RX, Y))
г) СУЩЕСТВУЕТ (Х)(ДЛЯ ЛЮБОГО (Y) (RX, Y))
д) СУЩЕСТВУЕТ (Y) (ДЛЯ ЛЮБОГО (X) (RX, Y))
е) СУЩЕСТВУЕТ (X) (СУЩЕСТВУЕТ (Y) (RX, Y))
Однако в семантической сети можно отразить только четыре разных квантификации, получаемых посредством присоединения кванторов к каждому концу дуги отношения:

(FOR-ALL) (для любої
X

R
(FOR-ALL) ія любого)
Y
Everyone loves everybody 'Каждый любит каждого '


(EXISTS)
(существует)
Ч Y
R
(FOR-ALL) (для любо
X
ALL humans have hearts 'У всех людей есть сердца'
R
(EXISTS)
{существу!
X
(FOR-ALL)
‘ цля любого)
ч Y

There Is a man who loves all women
'Существует мужчина, который любит всех женщин'
R
(EXISTS)
(существует)
(EXISTS)
(существует)
Some men have watches 'У некоторых мужчин есть часы'
Если семантическая сеть должна иметь в плане квантификации ту же выразительную силу, что и ИППП, тогда должны быть найдены некоторые дополнительные (более сложные) структурные правила.
Шуберт (Schubert, 1975) указал один способ перевода большинства структур, имеющихся в ИППП, в семантическую сеть. Для этого высказывание, представленное в форме исчисления предикатов, он прежде всего переписывает в форме Сколема (см. первую статью Чарняка),— в форме, которая не имеет кванторов существования, а все кванторы общности находятся за пределами основной части выражения. В его графе узлы, которым приписан квантор общности, специально помечены (он использовал пунктирный кружок). Любой узел, обозначающий некоторую функцию Сколема и зависящий от узла, соотносящегося с квантором общности, соединяется (посредством пунктирной дуги) с этим узлом-хозяином, например:
(5) Every man loves a woman.
‘Каждый мужчина любит женщину.’ имеет две интерпретации, представляемые в ИППП как:
FOR-ALL (X) (EXISTS (Y) (MAN (X) IMPLIES (WOMAN (Y) AND LOVE (X, Y))))
‘ДЛЯ ЛЮБОГО (X) (СУЩЕСТВУЕТ (Y) (МУЖЧИНА (X) ИМПЛИЦИРУЕТ (ЖЕНЩИНА (Y) И ЛЮБИТ (X, Y))))’ и
EXISTS (Y) (FOR-ALL (X) (WOMAN (Y) AND (MAN (X) IMPLIES LOVE (X, Y))))
‘СУЩЕСТВУЕТ (Y) (ДЛЯ ЛЮБОГО (X) (ЖЕНЩИНА (Y) И МУЖЧИНА (X) ИМПЛИЦИРУЕТ ЛЮБИТ (X, Y))))’
В результате сколемизации мы получаем:
FOR-ALL(X) (MAN X IMPLIES WOMAN(MANS-WO- MAN(X)) AND LOVE (X, MANS-WOMAN (X)))
‘ДЛЯ ЛЮБОГО (X) (МУЖЧИНА (X) ИМПЛИЦИРУЕТ
ЖЕНЩИНА (ЖЕНЩИНА-МУЖЧИНЫ (X)) И ЛЮБИТ (X, ЖЕНЩИНА-МУЖЧИНЫ (X)))’
FOR-ALL(X) (WOMAN(A) AND (MAN(X)IMPLIES LOVE(X.A)))
‘ДЛЯ ЛЮБОГО (X) (ЖЕНЩИНА (А) И (МУЖЧИНА (X) ИМПЛИЦИРУЕТ ЛЮБИТ (X, А)))’
(А является константой).
В семантической сети два этих утверждения могут быть представлены следующим образом:
о
Еще по теме СЕМАНТИЧЕСКИЕ СЕТИ:
- Общее понятие семантического синтаксиса, семантического членения предложения. Семантическая структура предложения. Семантика схемы. Типовое значение предложения
- Частные сети и сети по интересам
- Лекция 4. Компоновка сети.Топология сети
- Интернет: правда и вымысел о заработках в Сети. Варианты заработка в Сети для владельца сайта.
- От семантического треугольника к семантическому тетраэдру From Semanic triangle to Semantic tetrahedron
- Сложное синтаксическое целое как структурно-семантическая единица текста. Структурные и семантические признаки сложного синтаксического целого.
- 2. Локальные вычислительные сети
- Минимизация сети
- Глава 6. Сети Хопфилда
- Одноранговые компьютерные сети.
- МНОГОСЛОЙНЫЕ ИСКУССТВЕННЫЕ НЕЙРОННЫЕ СЕТИ
- Внутрикоммутикативные сети
- Свёрточные нейронные сети
- Основное назначение сети