Принцип единства информационного пространства
Следующей особенностью ИБС является единая информационная база. В современных условиях для ведения единой информационной базы используются различного рода системы управления базами данных (СУБД).
СУБД имеют специальные механизмы контроля целостности данных (триггеры, внешние ключи и т. д.), отличающиеся простотой и высокой надежностью. В подавляющем большинстве это системы управления реляционными БД.Базу данных принято называть единой, если однотипные по смыслу данные хранятся единообразно в одном месте. Например, данные о физических лицах хранятся в одних и тех же таблицах и в кредитном модуле, и в модуле обслуживания физических лиц,
В отсутствие единой информационной базы усложняется поиск, обмен, следовательно, и получение любой информации встроенными средствами системы. При этом различные задачи в системе выполняются отдельно и являются информационно слабо связанными на уровне ИБС.
Современные банковские системы ориентированы на использование единой базы данных, являющейся совокупностью структурированных данных, предназначенных для многоцелевого и многократного их применения, и методов доступа к ним.
Отличительной особенностью баз данных ИБТ является совместное хранение данных с их описаниями. Эти описания называются метаданными (данные о данных). Они необходимы для контроля и управления данными как ресурсом.
Существует несколько уровней программного обеспечения: операционная система, СУБД, прикладные программы, каждый из которых решает свои специфические задачи. Например, СУБД обеспечивает интерфейс доступа к данным на чтение и запись, блокирование записей в режиме многопользовательской работы, предоставляет средства архивации, восстановления и резервного копирования данных. Наиболее распространенным интерфейсом доступа к данным являются SQL-запросы, которые анализируются на СУБД, и различные программные средства, которые исполняют эти запросы.
Имеется большое количество СУБД, которые используются при построении ИБТ. Все они поддерживают реляционную модель данных, но имеют различные эксплуатационные характеристики. Потенциал программного продукта зависит от применяемой в нем СУБД и от степени использования ключевых свойств СУБД. Важно, что на программный продукт нельзя переносить свойства СУБД, так как реализация продукта с аналогичным свойством требует специальных усилий со стороны разработчика прикладного программного обеспечения.
Следует различать единую базу данных и единое информационное пространство. Под единым информационным пространством понимается возможность вызывать функции других подсистем, а также общность данных и методов доступа к ним в системе. Сама по себе СУБД не обеспечивает ведение единого инфор
мационного пространства, но позволяет его реализовать и использовать с максимально возможной эффективностью.
Под единым информационным пространством банка можно понимать также организацию информации, циркулирующей в банке, включая методы ее обработки, хранения и представления. На уровне автоматизированной банковской системы единое информационное пространство можно интерпретировать, как возможность системы оперировать любыми данными, формирующимися в процессе функционирования системы. При этом должны соблюдаться принципы открытости, защищенности, однократного учета и ввода. Таким образом, реализация единого информационного пространства банковской технологией обеспечивает эффективную организацию работ с информацией с точки зрения быстродействия и удобства работы пользователя с данными.
Использование СУБД при построении системы банковского обслуживания позволяет не только организовать хранение данных в рамках единой базы данных, но и управлять потоками информации и данных в системе, основываясь на единых принципах и методах, обеспечивающих реализацию конкретных предметноориентированных алгоритмов обработки.
В последнее время все большую популярность получают постреляционные модели данных, которые являются развитием реляционной модели с тем отличием, что в ней снято ограничение на атомарность (неделимость) атрибутов.
Ограничение на атомарность атрибутов означает, что в реляционной базе данных атрибут (поле) каждой записи может содержать только одно значение. В постреляционной модели, напротив, поле может содержать несколько значений или даже целую таблицу. Таким образом, появляется возможность «вложить» одну таблицу в другую. Это позволяет более эффективно оперировать банковскими бизнес-объектами, каждый из которых становится логически целостным, будучи представлен всего одной записью.
Скорость выполнения запросов в постреляционных СУБД возрастает (иногда в несколько раз), но переход от реляционных баз данных, получивших повсеместное распространение, к постреляционным связан со значительными затратами и носит пока ограниченный характер.
Еще одним путем к обеспечению единого информационного пространства является использование хранилища данных.
Особенностью информационной системы банка является необходимость обработки двух типов данных, а именно оперативных и аналитических. Поэтому в процессе функционирования ИБС приходится решать два класса задач: обеспечение повседневной работы банка по вводу и обработке информации и организация информационного хранилища в целях анализа данных для выявления тенденций развития, прогнозирования состояний, оценки и управления рисками и т. д. Задачи первого класса полностью решаются OLTP-системами (OnLine Transactional Processing - оперативная обработка транзакции). Для работы с аналитическими данными предназначены OLAP-системы (OnLine Analytical Processing - оперативная аналитическая обработка), которые построены по технологии хранилища данных и служат для агрегированного анализа больших объемов данных. Эти системы являются составной частью систем принятия решений или управленческих систем класса middle и top management, т. е. систем, предназначенных для пользователей среднего и высшего уровня управления банка.
Таким образом, возможности ИБС могут быть расширены путем совместного использования транзакционных OLTP-систем и хранилищ данных (Data Warehouse).
Отличительными чертами хранилища данных являются:
• ориентация на предметную область - в хранилище данных помещается только та информация, которая может быть полезной для работы аналитических систем;
• защищенность - в хранилище можно добавлять информацию, но ее нельзя изменять, модифицировать и корректировать;
• поддержка хронологических данных - для анализа требуется информация, накопленная за длительный период времени;
• интеграция в едином хранилище ранее разъединенных данных, поступающих из различных источников, а также их проверка, согласование и приведение к единому формату;
• агрегация - одновременное хранение в базе агрегированных и первичных данных, чтобы запросы на определение суммарных величин выполнялись достаточно быстро.
Таким образом, хранилище данных представляет собой специализированную базу данных, в которой собирается и накаплива
ется информация, необходимая менеджерам банка для подготовки управленческих решений (о клиентах банка, кредитных делах, процентных ставках, курсах валют, котировках акций, состоянии инвестиционного портфеля, операционных днях филиалов и т. д.).
Хранилища данных принято изображать в виде многомерного куба. Величины, хранящиеся в ячейках этого куба и называемые фактами, являются количественными показателями, характеризующими деятельность кредитного учреждения. Это могут быть данные об оборотах и остатках по счетам, структуре расходов и доходов, состоянии и движении денежных средств и т. д. Измерения куба, образующие одну из его граней, - это множество однотипных данных, предназначенных для описания фактов (например, филиалы банка, операционные дни, клиенты и валюты). Агрегация данных выполняется по измерениям куба, поэтому элементы измерений принято объединять в иерархические структуры. Так, филиалы часто группируются по территориальному признаку, клиенты - по отраслевому признаку, даты группируются в недели, месяцы, кварталы и годы. Каждая ячейка данного куба «отвечает» за конкретный набор значений по его отдельным измерениям, например, оборотов балансовых счетов за день, квартал, год в разрезе филиалов.
Над числовыми фактами, хранящимися в ячейках, можно выполнять различные математические и логические операции, позволяющие рассматривать представленную информацию под разными углами зрения. Операции проводятся с использованием методов управления данными. Вся совокупность методов называется репозиторием методов хранилища данных.Данные загружаются в хранилище из оперативных систем обработки данных (OLTP-системы головной конторы и отдельных филиалов) и из внешних источников (официальные отчеты предприятий и банков, результаты биржевых торгов и т. д.). При загрузке данных в хранилище выполняется проверка целостности, сопоставимости, полноты загружаемых данных, а также проводятся их необходимое преобразование и трансформация.
Хранилище данных ориентировано на высшее и среднее руководство банка, ответственное за принятие решений и развитие бизнеса. Это руководители структурных, финансовых и клиентских подразделений, а также подразделений маркетинга, управления анализа и планирования.
Для работы с хранилищами данных используются специальные программные продукты, поскольку SQL-серверы не обеспечивают необходимого быстродействия по доступу к данным. Язык запросов при работе с хранилищем данных также отличается от SQL.
Одним из вариантов реализации на практике хранилища данных является построение витрин данных (Data Marts). Иногда их называют также киосками данных. Витриной данных является предметно-ориентированная совокупность данных, имеющая специфическую организацию. Содержание витрин данных, как правило, предназначено для решения некоего круга однородных задач одной области или нескольких смежных предметных областей. Например, для решения задач, связанных с анализом кредитных услуг банка, используется одна витрина, а для работ по анализу деятельности банка на фондовом рынке - другая.
Следовательно, витрина данных - это относительно небольшое специализированное хранилище данных, содержащее только тематически ориентированные данные и предназначенное для использования конкретным функциональным подразделением.
Итак, функционально ориентированные витрины данных представляют собой структуры данных, обеспечивающие решение аналитических задач в конкретной функциональной области или подразделении компании (управление прибыльностью, анализ рынков, анализ ресурсов, анализ денежных потоков, управление активами и пассивами и т. д.). Таким образом, витрины данных можно рассматривать как маленькие хранилища, которые создаются в целях информационного обеспечения аналитических задач конкретных управленческих подразделений компании.Создание витрины данных определяется необходимостью обеспечить возможности анализа данных той или иной предметной области оптимальными средствами.
Витрины данных и хранилище данных значительно отличаются друг от друга. Хранилище данных создается для решения корпоративных задач, присутствующих в корпоративной модели данных. Обычно хранилища данных создаются и приобретаются организациями с центральным подчинением - классические организации информационных технологий, например банк. Хранилище данных составляется усилиями всей корпорации.
Витрина данных разрабатывается для удовлетворения потребностей в решении конкретного однородного круга задач. Поэтому в одном банке может быть много различных витрин данных, каждая из которых имеет свой собственный внешний вид и свое содержание.
Следующее отличие состоит в степени детализации данных, так как витрина данных содержит уже агрегированные данные. В хранилище данных, наоборот, находятся максимально детализированные данные. Поскольку уровень интеграции в витринах данных более высок, чем в хранилищах, нельзя легко разложить степень детализации витрины данных в степень детализации хранилища. Но всегда можно последовать в обратном направлении и агрегировать отдельные данные в обобщенные показатели.
В отличие от хранилища витрина данных содержит лишь незначительный объем исторической информации, которая привязана только к небольшому отрезку времени и существенна только в момент, когда она отвечает требованиям решения задачи. Витрины данных можно представить в виде логически или физически разделенных подмножеств хранилища данных (рис. 5.2).
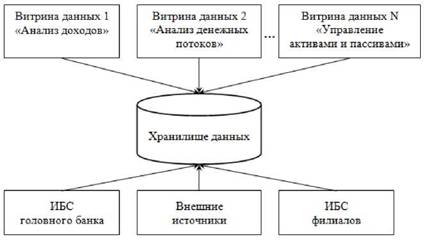
Рис. 5.2. Схема взаимосвязи витрин данных и хранилища данных
Витрины данных, как правило, создаются в многоуровневой технологии, которая оптимальна для гибкости анализа, но не оп
тимальна для больших объемов данных. Данные в такой витрине снабжены большим количеством индексов.
Структура витрин данных также ориентирована на многомерную организацию данных в виде куба. Однако их построение в силу ограниченности информационного диапазона, обеспечивающего потребности одной функциональной области, значительно проще и выгоднее, чем создание хранилища данных. Физическая структура базы данных в витрине данных создается по модели «звезда» (star schema), являющейся оптимальной при решении группы задач, для которой построена витрина, поскольку обеспечивает высокую скорость выполнения запросов посредством разделения данных. Звездообразная схема предполагает наличие одной центральной таблицы фактов (fact table), в которой содержатся суммирующие или фактические данные, и окружающих ее таблиц измерений (dimensional table), отражающих описательную информацию. Таблица фактов и таблицы измерений связаны между собой идентифицирующими связями, при этом ключевое поле таблицы фактов целиком состоит из всех первичных ключей таблиц измерений.
Существуют два типа витрин данных: зависимые и независимые. Зависимая витрина данных - это та, источником которой служит хранилище данных. Источником независимой витрины данных является среда первичных программных приложений. Зависимые витрины данных стабильны и имеют прочную архитектуру. Независимые витрины данных нестабильны и имеют неустойчивую архитектуру, по крайней мере, при пересылке данных.
Надо отметить, что витрины данных представляются идеальным решением наиболее существенного конфликта при проектировании хранилища данных - производительность или гибкость. В общем, чем более стандартизированной и гибкой является модель хранилища данных, тем менее продуктивно она отвечает на запросы. Это связано с тем, что запросы, поступающие в стандартно спроектированную систему, требуют значительно больше предварительных операций, чем в оптимально спроектированной системе. Направляя все запросы пользователя в витрины данных, поддерживая гибкую модель для хранилища данных, разработчики могут достичь гибкости и продолжительной стабильности структуры хранилища, а также оптимальной производительности для запросов пользователей.
Данные, попав в хранилище, могут быть распространены среди многих витрин данных для доступа пользовательских запросов. Эти витрины данных могут принимать различные формы - от баз данных «клиент-сервер» до баз данных на рабочем столе, OLAP- кубов или даже динамических электронных таблиц. Выбор инструментов для пользовательских запросов может быть широким и отображать предпочтения и опыт конкретных пользователей. Широкий выбор таких инструментов и простота их применения сделают их внедрение наиболее дешевой частью реализации проекта хранилища данных. Если данные в хранилище имеют хорошую структуру и проверенное качество, то их передача в другие витрины данных станет рутинной и дешевой операцией.
Использование технологий витрин данных, зависимых и независимых, позволяет решать задачу консолидации данных из различных источников в целях наиболее эффективного решения задач анализа данных. При этом источниками могут быть различающиеся по архитектуре и функциональности учетные и справочные системы, в том числе и территориально разрозненные.
5.3.
Еще по теме Принцип единства информационного пространства:
- Принцип иерархии источников трудового права в единстве с принципами запрета ухудшать положение работник
- 152. Глобальное информационное пространство
- Принцип единства сознания и деятельности.
- Принцип единства руководства.
- III.5.5. Принцип материального единства мира
- Глава 16(2). Распространение информационных волн в социальном пространстве
- 5 Пространство есть форма выражения и существования такого специфического образования как единство места, времени и действия. Только место в данном случае рассматривается как общая структурированная категория.
- 1. Линейные пространства. Нормированные пространства. Метрика, порожденная нормой. Ряды в нормированных пространствах. Абсолютная сходимость ряда и полнота нормированного пространства. Факторпространства
- Принцип командного единства.
- Статья 11. Принцип единства контрактной системы в сфере закупок
- Принцип единства специализации и унификации процессов управления.
- § 17. Основоположение о синтетическом единстве апперцепции есть высшей принцип всякого применения рассудка
- 17. Основоположение о синтетическом единстве апперцепции есть высший принцип всякого применения рассудка
- Принцип единства логического и исторического и историко-фило-софская концепция Гегеля
- Глава 7(2). Информационная война как целенаправленное информационное воздействие информационных систем
- § 14. Понятие нормативной науки. Основное мерило или принцип, придающий ей единство