СИСТЕМА КОЛБИ
На протяжении ряда лет Колби (Colby etal., 1971), (Е n е a and Colby, 1973), (Colby- and Parkinson, 1974) разрабатывал диалоговую систему, моделирующую речевую деятельность параноика (этот автоматический собеседник, как и сама система, носит имя PARRY).
Свидетельством успеха системы служит тот факт, что ее программы широко используются специалистами по ИИ, не связанными непосредственно с разработкой данной системы. Приведем образец диалога (ответы PARRY даны прописными буквами):Have you been hospitalised before?
‘Вы раньше лечились в больнице?*
THIS IS THE FIRST TIME.
‘Это первый раз.*
How long have you been there?
‘Сколько времени вы здесь находитесь?*
ABOUT TWO WEEKS.
‘Около двух недель.*
Any headaches?
‘Головные боли есть?*
MY HEALTH IS FINE.
‘Мое здоровье в прекрасном состоянии.*
Are you having any difficulty with your memory? ‘Испытываете ли вы трудности с памятью?*
N0.
‘Нет.*
Then perhaps you can tell me who is the President of the United States?
‘He скажете ли вы тогда, кто президент Соединенных Штатов?’
NIXON IS PRESIDENT.
‘Никсон — президент.’
What day is it today?
‘Какой сегодня день недели?’
TODAY IS THURSDAY.
‘Сегодня четверг.’
What season is it?
‘Какое сейчас время года?’
LET’S GET ON WITH THE INTERVIEW.
‘Давайте продолжим беседу.’
Цель Колби состояла в разработке такой системы, которая не является ’’слабой" в том смысле, в каком это можно сказать о большинстве других систем ИИ, то есть она не отступает, когда входная фраза не совсем такова, как можно было ожидать, и пытается продолжить диалог при любых обстоятельствах (как это обычно делают собеседники-люди).
Указанное свойство достигается благодаря отказу от обычного синтаксического анализа, а также от попыток рассматривать все слова входных предложений. Это дает ощутимую помощь, в чем можно убедиться, если попытаться пословно проанализировать такую форму вежливости, как Would you be so kind as to...
‘He будете ли вы столь любезны...’ Англичане, приезжающие в США, быстро отвыкают от подобных выражений, вызывающих замешательство их собеседников в магазинах.Входной текст делится на сегменты с помощью эвристической процедуры, которая проводит границу сегмента тогда, когда встречается одно из ключевых слов. Затем каждому сегменту сопоставляется его образец (pattern). Сейчас в памяти машины хранится 1700 образцов (Colby and Parkinson, в печати), которые сопоставляются не с синтаксическими или семантическими представлениями (за исключением случаев противоречий и ошибок), а непосредственно с цепочками слов входного текста (с помощью операций замен и сокращений). Так, например, во входном предложении What is your main problem? ‘Что вас больше всего беспокоит?* глагол Is заменяется своим инфинитивом BE, a your ‘ваш* заменяется YOU ‘вы’, в результате чего получается:
WHAT BE YOU MAIN PROBLEM
Затем применяется операция сокращения, последовательно зачеркивающая каждое слово полученной цепочки, а четыре оставшихся слова сравниваются с образцами:
BE YOU MAIN PROBLEM WHAT YOU MAIN PROBLEM WHAT BE MAIN PROBLEM WHAT BE YOU PROBLEM WHAT BE YOU MAIN
Только для предпоследней из перечисленных цепочек в памяти хранится образец, который, естественно, и отбирается в качестве результата анализа. Этот процесс можно назвать процедурой минимального анализа.
В том же формате, что и образцы, записаны правила, задающие реакцию "пациента" на обнаруженные им во входных вопросах или замечаниях агрессивность или преувеличенное дружелюбие. Подобранные образцы затем используются (непосредственно или через посредство упомянутых правил вывода) при порождении образцов ответов.
Эвристики описываемой системы отличаются большой изобретательностью, о чем свидетельствует ее популярность. В последнее время система подверглась существенной модификации: сейчас она называется PARRY2, и ее работа базируется скорее не на первоначальной концепции ключевых слов, а на процедуре сравнения с образцами.
Она включает "частичные" (или прагматические) правила, моделирующие ожидания и намерения, и уже это позволяет отнести ее к системам второго поколения, осуществляющим весьма творческую интерпретацию входных фраз. Разрабатывается также генератор, который сможет выдавать не только заранее заданные ответы.Колби и его коллеги затратили большие усилия на то, чтобы выяснить, могут ли психиатры отличить ответы PARRY от ответов человека-параноика (Colby and Н і 1 f, 1973). Это, возможно, первая реальная попытка проведения теста Тьюринга (Turing, 1951), заключающегося в сравнении реакции человека и машины. Имеются определенные затруднения в статистической интерпретации результатов, но все же несомненно, что группа психиатров, подвергшихся опросу, не могла различить ответы пациента и машины. Несмотря на это, многие все же считают, что принципиально PARRY нельзя относить к имитирующим системам, поскольку, как они говорят, она "ничего не понимает". Можно возразить, что такие критики имплицитно предъявляют слишком высокие требования к понятию "понимание". Ведь тогда можно пойти дальше и счесть, что многие люди тоже не понимают содержания предложений столь же глубоко и точно, как это доступно философу- аналитику (что, возможно, и к лучшему). Однако несомненно, что многие люди во многих ситуациях понимают (или создают впечатление, что понимают) именно так, как PARRY.
Когда мы говорили, что PARRY относится к "сильным" системам в том смысле, что она готова работать с необычными или неожиданными входными фразами, мы не хотели сказать, что она даст осмысленный ответ на бессмысленную входную "цепочку" (например, на строчку, состоящую из звездочек), однако подобный способ проверки работы системы понимания языка нельзя считать приемлемым. Ясно, однако, что простое внутреннее представление, используемое программой, позволяет расширить PARRY таким образом, что эта система легче, чем однотипные ей системы, реагирует на неожиданности во входных предложениях.
Действительным недостатком PARRY можно считать то, что она оказывается "слабой" в более общем смысле, а именно осуществляет большую часть своего "понимания" за счет конкретного ситуационного контекста, определяемого задачей поведения параноика. Пользователи программы склонны терпимо относиться к ее отказам от общения и резким сменам тем разговора на том основании, что такое поведение типично для параноика, хотя, если судить с точки зрения именно способности понимания естественного языка, подобные ответы системы вызваны просто тем, что она оказалась не в состоянии понять смысл входного предложения (то есть подобрать подходящие образцы).
Система Уилкса строит семантические представления для небольших текстов на естественном языке: базисное представление строится непосредственно по тексту и может затем преобразовываться с помощью разного рода правил вывода умозаключений и достигать такого уровня глубины представления, который необходим для решения задач, наглядно демонстрирующих способность системы "понимать" текст. Введена единая форма представления, то есть предложены такие структуры, в которых объединяется информация, обычно подразделяемая на синтаксическую, семантическую, фактическую и дедуктивную. Основной единицей этого семантического представления является шаблон (template), интуитивным соответствием которого можно считать базисную форму сообщения, имеющую форму тройки "агенс — действие — объект". Шаблоны строятся из более мелких блоков, называемых формулами, которые соответствуют толкованиям отдельных лексем. Для того, чтобы построить полное семантическое представление текста (называемое семантическим блоком), шаблоны объединяются с помощью двух видов структур более высокого уровня — надшаблонов (paraplates) и правил вывода умозаключений. Сами шаблоны строятся в процессе обработки входного текста, тогда как формулы, надшаблоны и правила вывода умозаключений хранятся в системе в готовом виде. Каждая из готовых структур трех названных типов построена на базе инвентаря из 80 атомарных семантических элементов, а также функций и предикатов, задаваемых на этом множестве элементов.
Система работает в режиме непосредственного доступа, пакеты программ написаны на языках LISP (см. сноску на с. 196), MLISP и MLISP2 (два последних языка являются расширениями LISP’a за счет введения структуры команд и средств сравнения с образцами). На вход подаются тексты на английском языке, которые пользователь составляет на материале словаря, включающего около 600 значений слов. Система переводит эти достаточно разнообразные входные тексты на французский язык. Такой режим работы системы удобен для проверки понимания английского языка, поскольку французский перевод обычного прозаического текста очевидным образом является либо правильным, либо неправильным и в то же время ситуация машинного нере-
вода позволяет опробовать возможности системы в решении трудных лингвистических задач (лексическая, глубинно-падежная и местоименно-референционная неоднозначность). Для этого можно, например, специально подбирать лексику входных предложений со сложными кореферентными связями (так, чтобы при переводе род французского местоимения диагностировал его референционную соотнесенность). Именно в этом смысле французский перевод показывает, правильно ли программа произвела вывод умозаключений при ’’понимании" переводимого текста. Программа является достаточно сильной, она может обрабатывать даже тексты, содержащие некоторые грамматические ошибки. Это объясняется тем, что в программе отсутствует синтаксический анализ в его обычном понимании, она осуществляет непосредственный переход к семантическим представлениям.
Типичным примером входного текста может служить такой: John lives out of town and drinks his wine out of a bottle. He then throws the bottles out of the window. ‘Джон живет за городом и пьет вино из бутылки. Затем он выбрасывает бутылки из окна’. Программа дает французский перевод, в котором три употребления предложной конструкции out of переведены по-разному, поскольку они имеют три разных смысла и во французском языке эти смыслы выражаются разными языковыми средствами.
Другим примером является фраза Give the monkeys bananas although they are not ripe because they are very hungry. ‘Дай бананы обезьянам, хотя они и незрелые, потому что они голодны.’, в которой два вхождения местоимения they (относящиеся, соответственно, к бананам и обезьянам) будут переведены местоимениями разных родов по принципу предпочтительности, о котором будет сказано ниже. Оба эти примера обрабатываются ’’базовым компонентом" системы (см. Wilks, 1973). Однако во многих случаях местоименная неоднозначность неразрешима с помощью прямых "соображений предпочтительности", использованных в последнем примере, где, грубо говоря, свойство "зрелости" считалось более предпочтительным при имени с признаком "растение", а свойство голода — при имени с признаком "живое существо". А уже в таких примерах, как John drank the wine on the table and it was good. ‘Джон выпил вино со стола, и оно было хорошим.’, местоимение it, которое можно соотнести с двумя существительными — wine ‘вино’ и table ‘стол’, не может быть обработано за счет учета предпочтительности,поскольку оба существительных могут быть связаны с прилагательным good ‘хороший’. В таких случаях, когда базо-, вый компонент не в состоянии разрешить неоднозначность, программа строит более глубокие представления текста, пытаясь вывести цепь умозаключений, одно из звеньев которой выявит предпочтительный вариант.
Система не содержит в явном виде никакой синтаксической информации; все, что ей известно о смысле произвольного английского слова,— это его формула. Она имеет вид древесной структуры семантических элементов и интерпретируется с помощью отношений зависимости. Главным элементом формулы (head) считается самый правый элемент, именно он и задает фундаментальную категорию, к которой принадлежит вся формула. Так, главными элементами формул, приписываемых действиям, могут быть только следующие семантические элементы: PICK ‘поднимать’, CAUSE ‘каузировать’, CHANGE ‘изменять, изменяться’, FEEL ‘чувствовать’, HAVE ‘иметь’, PLEASE ‘доставлять удовольствие’, PAIR ‘соединять по двое’, SENSE ‘чувствовать’, USE ‘использовать’, WANT ‘хотеть’, TELL ‘говорить’, BE ‘быть’, DO ‘делать’, FORCE ‘заставлять’, MOVE ‘двигать, двигаться’, WRAP ‘заворачивать’, THINK ‘думать’, FLOW ‘лить, литься’, МАКЕ ‘изготовлять’, DROP ‘бросать, падать’, STRIK ‘ударять’, FUNC ‘функционировать’, HAPN ‘случаться’.
Например, формула
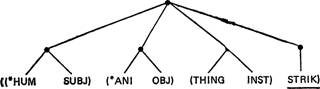
орисывает смысл действия ‘бить’ (beat) следующим образом: «Действие, преимущественно состоящее из ударов (STRIK) И обычно выполняемое при помощи инструмента (INST), являющегося вещью (THING), объект (OBJ) которого — чаще всего живое существо (ANI), а субъект (SUBJ) — человек (HUM)»[61]. Звездочки перед элементами означают, что речь идет о классе элементов, например, класс *HUM ‘человеч.’ включает два элемента: MAN ‘человек’ и FOLK ‘группа людей’. Предлагаемая древесная структура довольно бедна (что объясняется требованием простоты ее преобразования в выражение на языке LISP); та же семантическая единица может быть представлена в форме, которая предложена Симмонсом для записи филлморовских глубинно-падежных отношений, а именно
SUBJ OBJ
«ним —-------------------------------------------- STRIK------------------------- “AN1
(or Agent)
1 INST
THING
Эта схема наглядно показывает, что фрагмент глубиннопадежной структуры, изображенный в верхней части схемы, самым тесным образом связан с базисным действием, или главным элементом формулы (который занимает самое правое место при скобочной записи и подчеркнут в формуле — см. стр. 326). Однако подобное преобразование скобочной записи в стрелочную, как это часто случается с графическими изображениями, наталкивается на некоторые ограничения. Например, стрелочная запись оказывается малоэффективной при описании смысла имен, поскольку главные элементы соответствующих формул (например, THING ‘вещь’ в формуле для needle ‘игла’ иди STUFF ‘вещество, материал’ в формуле для water ‘вода’) не имеют непосредственно зависящих от них по глубинно-падежным отношениям элементов, аналогичных отношениям в семантическом дереве для действия, например beat.
Глубинно-падежные части формул могут иметь в своем составе другие глубинно-падежные подчасти или даже элементы, обозначающие действия; такое развертывание может включать столько ступеней, сколько покажется целесообразным иметь в толковании разработчику словаря. Например, формула слова sew ‘шить’ будет содержать инструментальную часть, которая описывает предпочтительный инструмент этого действия как линейную вещь (LINE THING), имеющую (WITH) отверстие (THRU PART) — естественно, речь идет об игле. Соответствующее поддерево
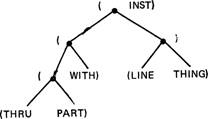
(всего дерева для sew) имеет вид:
где дополнительная падежная характеристика вставлена внутрь характеристики инструмента. Такая форма представления позволяет существенно использовать упорядоченность элементов, которая выпадает в стрелочном представлении, что дает гораздо большую гибкость при описании смысла имен, чем метод Катца — Фодора [62], не предусматривающий ни глубинно-падежных элементов, ни элементов для представления действий (система Шенка является вариантом этого метода — см. Weber, 1972).
Структуры-шаблоны, задающие семантические представления реальных предложений и их частей, имеют форму сети, составленной из формул типа приведенных выше. Шаблон всегда состоит из трех основных узлов: для агенса, действия и объекта, он может содержать также другие узлы, подчиненные трем названным. Например, в шаблоне предложения John beat the carpet ‘Джон выбивал ковер’ приведенное выше дерево для beat будет поставлено на место узла, символизирующего действие, другое дерево — для John — на место агенса и т. д. Сложность семантических представлений в системе определяется тем, как формулы, рассматриваемые в качестве активных сущностей, управляют заполнением других узлов данного шаблона.
Итак, полный шаблон — это достаточно сложная структура. Приведем в качестве примера шаблон предложения John shut the door. ‘Джон закрыл дверь.’:
'объект, имеющий материалом (источником) древесину и используемый человеком для того, — чтобы одушевленные вещи не могли использовать отверстие'
Объект
шаблона» (door)
(THE ((PlANTST'UFF) SOUR) ((((THRU PART) OBJE) (NOTUSE'ANI)) GOAL) ((MAN USE) (OBJE THING))), Копр, ((ДЕРЕВЛ/ІАТЕР ЖСТОЧН )((((ЧЕРЕЗ ЧАСТЬ)ОБЪЕКТ)(HE ИСП/ОДУШ ))ЦЕЛЬ)((ЧЕЛОВ.ИСП.)(ОБЪЕКТ ВЕЩЬ)))
AreHf Шаблона *(John)
Действие шаблона «(shut)
'конкретный человек I мужского пола’ Г
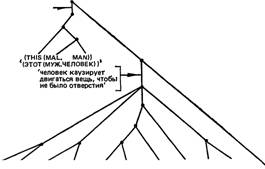
(*HUM SUBJ) (THING OBJE) (((THRU PART) NOTBE) GOAL)(MOVE CAUSE) 'СЧЕЛ.СУБ ) (ВЕЩЬ ОБЪЕКТ) (((ЧЕРЕЗ ЧАСТЬ)НЕ БЫТЬ) ЦЕЛЬ) (ДВИГ. КАУЗ.)1
Определенный артикль the не получает особого семантического представления, а просто присоединяется, как это видно в шаблоне, к соответствующей формуле (как и элемент PAST ‘прош. время’ следует присоединить к формуле для shut). Хотя все шаблоны имеют единую базисную форму "агенс — действие — объект", любому из этих узлов может быть подчинена зависящая от него формула. Например, если бы рассматриваемое предложение имело вид: John shut the green door. ‘Джон закрыл зеленую дверь.’, объектному узлу door была бы подчинена формула слова green.
Каким образом в действительности производится переход от текста к шаблонам? Этот процесс начинается с сегментации (fragmentation) текста: программа разбивает фразы текста на сегменты, пользуясь ключевыми словами, такими, как предлоги, подчинительные союзы и т. п. Это делается только на основе списка ключевых слов и сведений о диапазоне действия семантических формул неключевых слов. Например, разбиение на сегменты фразы The sort of man / that dogs need / is kind. ‘Человек, I который нужен собакам, / должен быть добрым.* осуществляется в двух местах, отмеченных здесь вертикальными чертами. Даже это предложение требует использования семантики формул для определения того, что в данном случае that является относительным союзным словом, а не указательным местоимением, как во фразах типа The dog likes that man. ‘Собака любит того человека*.
Обычно каждому сегменту фразы, полученному указанным способом, сопоставляется один или более шаблонов, однако в некоторых случаях сегменты немедленно склеиваются в единый шаблон, как, например, это произойдет для предложения The sort of man is kind из приведенной выше фразы.
Затем осуществляется процедура наложения (matching) шаблонов на сегменты. Сначала программа просматривает в сегменте слева направо все комбинации формул (ибо, вообще говоря, для каждого слова будет определено более одной формулы: каждая соответствует какому-то из значений слова), при этом обращается внимание лишь на главные элементы формул. Ищутся формулы для агенса действия и объекта, сначала именно в названном порядке; при этом, например, формула прилагательного (ее главный элемент — KIND ‘тип’) никогда не может занять место агенса. Соответствующая процедура называется наложением каркасов шаблонов (bare template matching) и в действительности выглядит сложнее, чем было здесь показано, поскольку тройка ’’агенс — действие — объект" часто располагается в сегменте в другом порядке. В связи с этим вводится шкала предпочтительности для выбора порядка главных элементов формул. Кроме того, многие сегменты не содержат всей тройки главных элементов, например, у предложения John left. ‘Джон ушел.’ не может быть объекта, и в таких случаях для сохранения единообразия шаблонов в них вводятся пустые узлы. И наконец, английские предлоги всегда трактуются как узлы действий, и потому им всегда приписываются пустые агентивные узлы (этот вопрос будет рассмотрен подробнее ниже).
Сама процедура наложения шаблонов тоже не так проста, как это было представлено выше, и она не сводится к прямому построению шаблонов из целых формул. Хотя полный шаблон, например для John shut the door, как он приведен выше, действительно строится таким образом, но до этого система уже сопоставила входному предложению каркас шаблона, состоящий из главных элементов MAN CAUSE THING ‘человек каузирует вещь’, который в системе считается допустимым, в отличие, например, от недопустимого каркаса вида KIND CAUSE THING ‘тип каузирует вещь*. Таким образом, каркасы шаблонов (или типы шаблонов), состоящие из трех упорядоченных семантических элементов, заранее заданы системе и накладываются на сегменты текста.
Затем следует более интересная процедура наложения, которую мы назовем расширением по предпочтительности (preferential expansion). Шаблоны строились до сих пор с помощью приписывания формул узлам только на основе требований к главным элементам формул. Для предложения John shut the door мы получим один правильный шаблон типа приведенного выше, но для предложения John shut the case. ‘Джон закрыл ящик/судебное дело.’ возможны два правильных шаблона с такими каркасами: MAN CAUSE THING и MAN CAUSE GRAIN ‘человек каузирует систему’, поскольку элемент GRAIN ‘система’ является главным в формуле для второго значения слова case.
Расширение состоит в поочередном обследовании всех шаблонов, принципиально допустимых для данного сегмента, с целью выяснить, какие требования формул к предпочтительному заполнению валентностей выполняются при выборе данного варианта шаблона.
Как говорилось ранее, некоторые семантические элементы, входящие в состав формул, не носят обязательного характера и выражают желательность, предпочтительность подобного заполнения. Так, в шаблоне (1) формула для shut содержит указание на предпочтительность того, чтобы агенсом был человек, а объектом — вещь. Оба условия предпочтительности выполняются, если главным элементом формулы для case является THING (то есть, если выбрать для case первое, вещественное значение), тогда как формула с главным элементом GRAIN (для второго значения case) не удовлетворяет условию предпочтительности, наложенному на объект. Таким образом, рассматриваются не только формулы для действия, но и все остальные формулы, входящие в состав шаблонов.
Такой поиск типов агенсов, объектов и т. п. носит лишь предпочтительный характер. Иначе говоря, может быть принята и формула, не удовлетворяющая условиям предпочтительности, но только в том случае, если нельзя найти лучшего варианта. В результате сегменту сопоставляется тот шаблон, в котором выполнено наибольшее число условий предпочтительности. Общий принцип здесь сводится к тому, что наилучшей интерпретацией является та, которая с точки зрения передачи информации содержит наименьшее количество "новшеств" по сравнению со стандартом. Эта простая процедура подсчета предпочтительностей попутно выполняет значительную часть работы, обычно возлагаемую на аппарат синтаксического анализа, поскольку одновременно с разрешением лексической неоднозначности (способом, описанным выше) она следит за тем, чтобы семантические представления прилагательных заняли в шаблонах надлежащие позиции (ср. the green door) и т. п.
Тем самым формулы — это не просто статичные объекты, задающие смысл слов. В процедурах типа описанной выше они играют активную роль, предъявляя свои требования к строящимся шаблонам. Если попытаться определить использование принципа предпочтительности в терминах анализа снизу вверх vs. сверху вниз, то окажется, что его нельзя считать чистым случаем ни первого, ни второго, поскольку предпочтительная структура выбирается при анализе снизу вверх, а потом применяется при анализе сверху вниз.
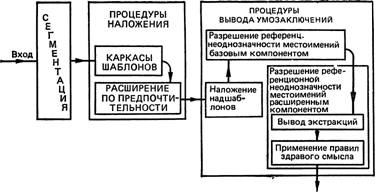
До сих пор мы рассмотрели следующие шаги работы программы анализа: сегментация текста и процедура наложения шаблонов, состоящая из двух этапов. Ниже мы рассмотрим процедуру вывода умозаключений, также состоящую из двух этапов. Результатом ее применения является семантическое представление текста (=семантический блок). В целом переход от текста к его семантическому представлению символизирует данная нами на с. 332 схема.
Обратимся теперь к процедурам вывода умозаключений, которые объединяют шаблоны так, что в результате текст оказывается представленным в форме семантического блока, под семантическим блоком мы понимаем упорядоченную последовательность шаблонов, связанных стрелками определенных типов (речь о них пойдет ниже). Построение такого блока означает, с точки зрения системы, разрешение всех случаев лексической и референционной неоднозначности; после этого программа в ее современном виде начинает переход от семантического блока к французскому тексту. Эта часть работы системы описана в (Herskovits, 1973). Таким образом, сейчас система, построив (как показано на схеме) семантическое представление, осуществляет синтез французского текста. Однако с равным успехом она могла бы отвечать на вопросы или выполнять другую аналогичную задачу.
В дальнейшем изложении в целях сокращения мы не будем приводить шаблоны в их полной, достаточно громоздкой форме (ср. (1)), а будем обозначать их наборами не менее чем трех символов (английских слов и пустых узлов) в квадратных скобках. Подчеркнем, что слова в квадратных скобках следует понимать как сложные семантические объекты, а не как собственно слова английского языка.
Следующий тип структуры — надиіаблон. Он служит для объединения двух шаблонов, причем чаще всего один из шаблонов представляет "главное" предложение [подлежащее, сказуемое и прямое дополнение], а второй — предложную группу. Так, если мы хотим получить надшаблон для предложения
John left his clothes at the cleaners.
‘Джон оставил свою одежду в химчистке.’, которому раньше система приписала два шаблона (один — ’’главному" предложению, второй — предложной группе), то надо соединить их глубинно-падежной связью локативного характера (SLOCA — spatial-location case tie) следующим образом:
[John left his + clothes]
SLOCA ------------------------------------------------ J
>► I ( ? =пустой узел агента) at the + cleaners]
Каково же устройство надшаблона? Каждый надшаблон выражает одно из глубинно-падежных отношений (отметим, что здесь используется тот же набор глубинных падежей, что и внутри формул), а для каждого глубинного падежа имеется по нескольку надшаблонов. Некоторые глубинные падежи условно обозначаются названиями английских предлогов, хотя на самом деле каждый предлог способен передавать не одно, а несколько глубинно-падежных значений.
Так, рассмотрим значения предлога by в группе предложений, которые начинаются одинаково: Не left Comano by... ‘Он ушел/уехал из Комано...’ . В приведенных ниже примерах в правой колонке даны названия падежей, соответствующие типам надшаблонов, которые соединяют ’’главное" предложение с предложной группой
| (2) Не left | by courtesy of the police | SOUR |
| Comano | ‘благодаря любезности полиции’ | ‘источник’ |
| (3) | by the autostrada | DIRE |
| ‘по автостраде’ | ‘направле ние’ | |
| (4) | by car ‘на машине’ | INST |
| ‘инструмент’ | ||
| (5) | by stealth ‘украдкой’ | WAY |
| ‘образ действия’ | ||
| (6) | by Monday night | TLOCA (time |
| ‘к вечеру понедельника’ | location case) ‘время’ | |
| (7) | by following the arrows ‘в направлении указателей’ | DIRE |
| ‘направле ние’ | ||
| (8) | by stealing a boat | INST |
| ‘украв лодку’ | ‘инструмент’ |
В общем виде надшаблон — это шестерка главных элементов двух каркасов шаблонов (причем некоторые элементы могут быть пустыми узлами) в соответствии с ролями ’’агенс первого шаблона", ’’действие первого шаблона", ’’объект первого шаблона" и аналогично для второго шаблона (особенно редко заполняются места агенса и объекта). В отличие от шаблонов, в надшаблонах условия заполнения узлов носят обязательный характер: при наложении некоторого надшаблона на пару шаблонов все их узлы должны удовлетворять заданным в надшаблоне условиям. Ниже представлены четыре надшаблона, дающие положительный результат при их наложении на пары шаблонов, соответствующие предложениям с теми же номерами, что приведены выше. Левая часть у всех надшаблонов одна и та же и написана один раз:
(3') (*ANI) (MOVE) (WHERE POINT) -------- О--- ? (WHERE LINE)
(DIRE)
(4') D
Еще по теме СИСТЕМА КОЛБИ:
- Тема 11. Система права и система законодательства. Основные правовые системы современности.
- § 31. Система права і система законодавства. Поняття системи права і її галузеве ділення.
- 11.6. Система права и система законодательства. Система права и правовая система
- CMS система - Content Menegment System - Система управления содержимым или, проще говоря, система управления сайтом. Это еще у нас в России иногда называют движком сайта. Вещь полезная :)
- 3. Понятие экономической системы. Типы экономических систем. Экономическая система современной России.
- 1.3 Двухтопливные комбинированные системы с эжекционными бензиновой и газовой системой сжигания
- 1.3 Двухтопливные комбинированные системы с эжекционнымибензиновой н газовой системой питания
- 1.2 Двухтопливные универсальные системы с эжекционными бензиновой и газовой системой питания
- 1.2 Двухтопливные универсальные системы с эжекционными бензиновой и газовой системой питания
- 1.4 Двухтопливные универсальные системы с бензиновой и газовой системами впрыска
- 1.4 Двухтопливные универсальные системы с бензиновой и газовой системами впрыска
- 10. О применимости результатов качественной теории динамических систем к социальным системам
- Система права и система законодательства в современных условиях
- 1.5 Двухтопливные комбинированные системы с бензиновой и газовой системами впрыска
- 1.5 Двухтопливные комбинированные системы с бензиновой и газовой системами впрыска
- 41. Понятие и структура системы права. Ее соотношение с системой законодательства.
- Основные мировые системы нотариата. Его место в правовой системе России