ЯЗЫК ПРОГРАММИРОВАНИЯ PLANNER
Чем же можно заменить ИППП? Одна из возможностей состоит в использовании для вывода умозаключений естественных свойств LISP или другого языка программирования. Именно так и строились некоторые ранние диалоговые системы, например система Рафаэла SIR — Semantic Information Retrieval (Raphael, 1968).
СИСТЕМА SIR
Чтобы объяснить то, что сделал Рафаэл, надо сначала бегло охарактеризовать списки свойств, используемые в языке LISP. В LISP каждому базисному символу (или ”атому“) ставится в соответствие так называемый список свойств (property list). Так, утверждение о том, что нос (nose) — часть (subpart) человека (person), на языке LISP записывается следующим образом!
property list
PERSON--------------------------------------------------------- ► (SUBPART (NOSE))
NOSE ------------------------------------------------------------ ► (SUPERPART (PERSON))
Как видно из примера, список свойств — это просто набор пар, где первый член — имя свойства, а второй — имя значения свойства. Если мы хотим добавить утверждения о том, что сердце (heart) — часть человека, а девушки (girls) — подкласс (subclass) людей, то мы должны записать следующее:
HEART ----------------------------------------------- —(SUPERPART (PERSON))
GIRL ------------------------------------------------------------- (SUPERSET (PERSON))
И здесь мы должны были бы изменить список свойств для PERSON:
PERSON------------------------------------------------------------------- (SUBSET (GIRL) SUBPART
(HEART NOSE))
Именно этой чертой языка LISP и пользовался Рафаэл. Он написал программы перевода некоторых типов предложений в структуры языка LISP и программы поиска нужных структур при ответе на вопрос. Например, если мы спрашиваем Does a girl have a heart? ‘Есть ли у девушки сердце?’, то программа сначала ищет соответствующее значение свойства SUBPART по символу GIRL; не найдя его, она отмечает, что существует отношение GIRL -► (SUPERSET(PERSON)), и переходит к поиску по символу PERSON.
Этот поиск, естественно, будет успешным, и программа даст на наш вопрос утвердительный ответ.Но вывод умозаключений при использовании LISP наталкивается на определенные трудности. Как отмечает Рафаэл в конце названной статьи, добавление новой информации и новых операций над ней часто сопровождается необходимостью переписывания части старых программ поиска в списках, в результате чего SIR становится неуправляемым. Далее Рафаэл утверждает, что указанные трудности можно обойти, используя ИППП. Это, конечно, верно, но, как мы видели, ИППП создает много собственных трудностей.
Другой выход состоит в том, чтобы сделать язык программирования более пригодным для вывода умозаключений. Именно эту задачу ставил перед собой Хьюитт (Hewitt) при разработке языка PLANNER. Сейчас PLANNER очень напоминает единорога: мы многое о нем знаем, но его никогда не существовало. Другими словами, язык программирования, называемый PLANNER, еще нигде никогда не применялся. Тем не менее идеи, положенные в основу языка PLANNER, оказались весьма продуктивными, и было создано и опробовано несколько вариантов и фрагментов этого языка. Одним из наиболее известных из них является MICRO-PLANNER (S u s s m a n et al., 1971). Дальнейшее изложение посвящено языку, приближающемуся к MICRO-PLANNER. (Это описание, возможно, будет непонятно для тех, кто совсем не знаком с языком LISP [51].)
ИСПОЛЬЗОВАНИЕ ЯЗЫКА PLANNER
Чтобы объяснить сущность языка PLANNER, представим себе ситуацию, когда человек посредством- дисплея общается с ЭВМ на языке MICRO-PLANNER. Отметим, что для простоты изложения мы изменили многие особенности синтаксиса языка MICRO-PLANNER, поэтому на самом деле наше описание лишь условно соответствует этому языку. Человек вводит на дисплей:
(ASSERT (AT JOHN KITCHEN))
Это означает, что в базу данных поступает ”утверждение“ (assertion) AT JOHN KITCHEN ‘В ДЖОН КУХНЯ’. (”Базой данных“ называется часть памяти, где можно хранить факты и производить их поиск.) Отметим, что из всех введенных символов язык MICRO-PLANNER ”знает“ только функцию ASSERT.
Все же остальные символы, например АТ, для программы бессмысленны. Если бы введенное утверждение имело вид (AT JOHN SINCERITY) ‘В ДЖОН ИСКРЕННОСТЬ’, то для программы ничего бы не изменилось. По тем же причинам не обязательно ставить предикат на первое место. С таким же успехом можно было бы ввести и (JOHN AT KITCHEN). Мы ставим предикат на первое место для единообразия с ИППП.(GOAL (AT JOHN?))
* (AT JOHN KITCHEN)
Для того чтобы найти факт в базе данных, мы используем функцию GOAL ‘цель’. Знак ”?“ означает, что мы не знаем, какое значение подставить на это место, и принимаем любое. Таким образом, мы имеем возможность формировать полное утверждение по его части. Знаком отмечаются ответы ЭВМ. Укажем, что способность программы узнать в (AT JOHN KITCHEN) образец для (AT JOHN?) объясняется тем, что в ней есть зачатки умения "подбирать образцы“. Мы могли бы спросить:
(GOAL (? JOHN KITCHEN)) и получили бы тот же ответ:
* (AT JOHN KITCHEN)
Другими словами, мы можем задавать вопросы о характере связи между символами JOHN и KITCHEN.
Если мы введем:
(GOAL (AT JOHN HOUSE)), то получим ответ:
*( )
Ответ ( ) означает, что программа оказалась не в состоя
нии найти подходящее утверждение. Естественно, у программы нет знаний о соотношении между kitchen ‘кухня’ и house ‘дом’, пока мы эти знания не ввели. Для того, чтобы это сделать, нам нужны так называемые ’’теоремы", которые соответствуют ’’программам" в других языках пррграм- мирования.
(CONSE LOC-FINDER
:LOC-FINDER — название теоремы. CONSE на : языке системы
:MICRO-PLANNER — это сокращение для consequent theorem ‘консеквентная теорема'. К этому :термину мы вернемся позже.
(OBJ LOC-A LOC-B)
:Это просто список переменных местонахожде- :ния.
(AT ?OBJ ?LOC-A)
:Это ’’образец" теоремы, который сообщает программе, что соответствующая теорема может оказаться :полезной при определении местонахождения объектов.
:3нак ”?“ в ?OBJ показывает, что это переменная.
(GOAL (AT ?OBJ ?LOC-B)
(GOAL (PART-OF ?LOC-B ?LOC-A))
:Эти две строки означают следующее: чтобы доказать местонахождение объекта в LOGA, надо доказать, что он находится в LOC-В, которое :является частью LOC-A.
Строки, помеченные знаком содержат неформальные пояснения для читателя и с программой не связаны. Продолжим работу с ЭВМ.
(ASSERT (PART-OF KITCHEN HOUSE))
(GOAL (AT JOHN HOUSE) THEOREMS)
*(AT JOHN HOUSE)
Сначала мы вводим нужное нам утверждение о том, что кухня — часть дома. Затем мы снова набираем GOAL (АТ
JOHN HOUSE), но йа этот раз добавляй символ THEOREMS, который означает, что если в базе данных нет соответствующего утверждения, то следует использовать теоремы. Программа использует теорему LOC-FINDER, поскольку ее образец соответствует образцу, вводимому функцией GOAL. Сравнивая образец, вводимый функцией GOAL, с образцом теоремы, программа отождествляет JOHN с ?OBJ и HOUSE с ?LOC-A. Способность выбора теорем по их образцам называется ”вызовом процедур по образцу“ (pattern directed invocation). Затем программа выполняет две функции GOAL внутри теоремы LOC-FINDER, в результате чего, соответственно, получает (AT JOHN ?LOC -В) (?LOC-B отождествляется с KITCHEN) и (PART-OF KITCHEN HOUSE) (и в этом случае отождествление произведено успешно).
Продолжаем работу.
(ASSERT (AT JOHN USA))
(GOAL (AT JOHN HOUSE) THEOREMS)
* (AT JOHN HOUSE)
Неискушенному читателю может показаться естественным, что после ввода утверждения о том, что Джон находится в США, программа по-прежнему способна ответить, что Джон находится в доме, однако для получения такого ответа ЭВМ производит значительную внутреннюю работу. Рассмотрим подробно то, что происходит после поступления функции GOAL.
— Определить, что ни одно из имеющихся утверждений не подходит для (AT JOHN HOUSE).
— Просмотреть теоремы. Определить, что теорема LOC-FINDER имеет образец, подходящий к утверждению (AT JOHN HOUSE), вводимому функцией GOAL.
— Начать применение теоремы LOC-FINDER.
Прежде всего отождествить JOHN с ?OBJ и HOUSE с PLOC-A.— Выполнить GOAL (GOAL (AT? OBJ ?LOC-B)). ?OBJ отождествлен с JOHN, в связи с чем имеется не одно, а два утверждения, совпадающих с образцом: (AT JOHN USA) и (AT JOHN KITCHEN). По причинам, которые нас не интересуют, программа выберет первое утверждение, отождествив
PLOC-B с USA. Однако она запомнит и второй вариант.
Выполнить GOAL (GOAL (PART-OF PLOC-B PLOC-A)), в результате чего получится (PART-OF USA HOUSE). Естественно, последнее утверждение не проходит, поэтому GOAL сообщит об отказе.
Обработка второго варианта может быть представлена схематически следующей диаграммой:
Выполнить (GOAL (AT ?OBJ 7L0C-B))- при ?LOC-B = KITCHEN
|-~- Вход в теорему FIND-LOC у
ВОЗВРАТ --------
Выполнить
Попытаться выполнить (GOAL (PART- OF 7LOC-B 7LOC-A))
(GOAL (AT ?OBJ 7LOC-B)) при 7L0C-B = USA
т
УСПЕХ
Попытаться выполнить (GOAL (PART- OF 7LOC-B 7LOC-A))
(USA) (HOUSE)
ОТКАЗ
Пока мы проследили операции вплоть до пункта ”отказ“. Далее начинают происходить действительно интересные вещи. Когда функция GOAL заканчивается отказом, MICRO-PLANNER начинает осуществлять так называемый "возврат". В сущности задача возврата состоит в поисках легкого пути исправления. Для этого MICRO-PLAN- NER возвращается к предшествующим шагам и пытается выяснить, возможен ли другой выбор переменных. В данном случае такой выбор имеется. Функция (GOAL (AT POBJ PLOC-B)) использовала утверждение (AT JOHN USA), а не утверждение (AT JOHN KITCHEN). Поэтому MICROPLANNER возвращается к этому шагу и выбирает вторую альтернативу.
Произвести возврат к ’’пункту выбора**. Определить, что в (GOAL (AT POBJ PLOC-B) может быть подставлено также (AT JOHN KITCHEN). Начать процедуру с этого шага при ?LOC-B=KITCHEN. Выполнить (GOAL (PART-OF KITCHEN HOUSE)). Процедура осуществляется успешно, следовательно, теорема доказана.
Наше описание соответствует левой части приведенной выше диаграммы.
Отметим, что если бы утверждение (PART- OF KITCHEN HOUSE) было взято из базы данных, то и эта попытка закончилась бы неудачей, и мы опять не смогли бы доказать теорему.(ASSERT (AT JOHN STORE))
(GOAL (AT JOHN KITCHEN))
* (AT JOHN KITCHEN)
Это еще один пример, показывающий, что программе известно лишь то, что сообщено ей в явном виде. Обычно оказывается желательным уничтожение утверждения о том, что Джон в кухне, после поступления утверждения о том, что он в магазине (store), или по крайней мере введение пометы о том, что в настоящий момент первое утверждение неверно. MICRO-PLANNER обладает средствами для выполнения каждой из этих двух операций. Мы покажем, как производится первая из них, поскольку ее несколько легче проиллюстрировать.
(ANTE LOC-CHANGE
:ANTE показывает, что это "антецедентная" теорема. : Более подробно об этом см. ниже.
(OBJ NEWLOC OLDLOC)
(AT ?OBJ PNEWLOC)
:Это образец. Он сообщает системе MICRO-PLAN- :NER, что соответствующую теорему следует вызывать, когда вводится утверждение, отвечающее : образцу.
(GOAL (AT ?OBJ ?OLDLOC))
(THNOT (EQUAL POLDLOC PNEWLOC))
(ERASE (AT POBJ POLDLOC)) )
:Три последние строки означают, что в случае, :когда POBJ находится в месте, не совпадающем :с PNEWLOC, старое утверждение зачеркивается.
В определенном отношении теорема LOC-CHANGE отличается от всех тех, которые были рассмотрены выше. Отличие состоит в том, что она применяется не для доказательства некоторого утверждения, а для введения новой информации в базу данных. Именно поэтому она называется антецедентной теоремой (и помечается знаком ANTE). Название связано с традиционными названиями частей импликации
в ИППП, а именно — посылкой (antecedent) и следствием (consequent).
СМЕРТНЫЙ (X)
ЧЕЛОВЕК (X) ИМПЛИЦИРУЕТ
следствие
(консеквент)
посылка
(антецедент)
Антецедентная теорема — такая, в которой нам дана посылка и мы выводим соответствующее следствие, тогда как в консеквентной теореме мы должны доказать следствие, для чего мы пытаемся найти соответствующую посылку. Таким образом, LOC-FINDER — это консеквентная теорема, поскольку она используется для нахождения (AT ?OBJ ?LOC-A) и доказывается с помощью перебора утверждений в базе данных. Можно сказать, что консеквентные теоремы ’’управляются целями" (question driven). С другой стороны, LOC-CHANGE — это антецедентная теорема, поскольку она используется при введении нового местонахождения объекта. Она ’’управляется данными" (data driven). Для использования этой теоремы мы сначала уничтожаем (erase) (АТ JOHN STORE), а потом снова вводим это утверждение:
(ERASE (AT JOHN STORE))
(ASSERT (AT JOHN STORE) THEOREMS)
Как и в случае с GOAL, теоремы используются только тогда, когда их вызывают.
(GOAL (AT JOHN HOUSE) THEOREMS)
* (AT JOHN HOUSE)
Произошла какая-то ошибка. Мы по-прежнему получаем утверждение о том, что Джон находится в доме. Для того чтобы выяснить, в чем состоит наша ошибка, мы вызываем все имеющиеся утверждения о местонахождении Джона
(FIND ALL ?Х (X) (GOAL (AT JOHN ?X)))
* (STORE KITCHEN)
Первая строка записи означает требование найти все значения переменной X в утверждениях вида (AT JOHN ?Х).
Просматривая наши утверждения, мы замечаем, что (АТ JOHN USA) в базе данных сейчас отсутствует. Еще раз просмотрев LOC-CHANGE, мы догадываемся, что, по-видимо- му, случилось. Вероятно, теорема нашла утверждение (АТ
JOHN USA), уничтожила его и сочла свою работу законченной. Чтобы исправить ошибку, мы должны переписать LOC-CHANGE следующим образом.
(ANTE LOC-CHANGE
(OBJ NEWLOC OLDLOC)
(AT ?OBJ ?NEWLOC)
A (THCOND ((THAND (GOAL (AT ?OBJ ?4-OLD-
LOC))
(THNOT (EQAL ?OLDLOC ?NEW-
LOC))
(THNOT (GOAL (PART-OF ?OLD- LOC ?NEWLOC)))) (ERASE (AT ?OBJ ?OLDLOC))
(THGO A))
((THRETURN))))
THCOND, THNOT, THGO и THRETURN — это, грубо говоря, аналоги функций LISP: COND, NOT, GO и RETURN. (В реальном языке MICRO-PLANNER все названия функций начинаются с ТН, однако мы отбросили эти буквы, когда названия функций языков MICRO-PLANNER и LISP не совпадали.) Функции MICRO-PLANNER отличаются от функций LISP тем, что для первых возможен возврат. Переменная ? OLDLOC сигнализирует, что следует пренебречь старым значением OLDLOC и взять ее новое значение. Для того чтобы проверить себя, читатель может попытаться выяснить, что произойдет в следующем случае:
(ERASE (AT JOHN STORE))
(ASSERT (AT JOHN USA))
:Заметьте, что теорем мы не вызываем, поэтому :не будет вызвана и теорема LOC-CHANGE. (ASSERT (PART-OF STORE USA))
(ASSERT (AT JOHN STORE) THEOREMS)
Более сложным является вопрос о том, как должна работать функция THCOND, чтобы избежать отказа в случае, когда встречается требование уничтожить старое местонахождение объекта.
В каких же отношениях PLANNER превосходит LISP при выводе умозаключений?
Управление базой данных. Система SIR является типичной с точки зрения построения базы данных на LISP’e, однако функции ASSERT, GOAL и ERASE позволяют значительно облегчить управление базой данных.
Средства для работы с образцами. MICRO-PLANNER располагает простейшими средствами для работы с образцами; так, мы можем вызывать образец из базы данных по его части. В то же время мы можем связывать переменные. PLANNER, если этот язык когда-нибудь будет разработан, должен обладать значительно более мощными средствами для работы с образцами.
Вызов процедур по образцу. Теоремы могут быть вызваны по их образцам. Это позволяет записывать функцию, вызывающую другую функцию, даже когда неизвестно название второй функции, а известно только ее назначение (насколько мы можем его выразить в образце теоремы).
Автоматический режим возвратов. Это одна из спорных черт языка PLANNER, однако использование автоматического режима возвратов в разумных пределах представляется полезным. Так, SHRDLU (программа, которая подробно рассматривается в части I статьи Уилкса) использует автоматический режим возвратов при решении таких вопросов, как, например, нахождение "большого синего кубика". Общая идея состоит в выполнении трех целевых условий: первое требует, чтобы предмет был кубиком, второе — чтобы его цвет был синим, третье — чтобы он имел соответствующий размер. В этом случае разумно непосредственно использовать режим возвратов, поскольку нет никаких способов, позволяющих "догадаться", который из нескольких предметов, например Bl, В2 и ВЗ, обладает всеми требуемыми свойствами. Критика режима возвратов сводится к тому, что он благоприятствует созданию программ, в которых слишком большая роль отводится слепому поиску. А это, в свою очередь, приводит к опасности комбинаторного взрыва. Подобная критика совершенно справедлива.
Действительно, можно считать ошибкой разработчиков языка MICRO-PLANNER то, что при использовании этого языка практически невозможно обойти режим возвратов. Однако существуют случаи, когда поиск должен быть слепым, и тогда автоматический режим возвратов оказывается удобным.
PLANNER VS. ИППП
Язык PLANNER свободен от многих сложностей, неизбежно встающих при использовании ИППП. В особенности это касается следующих проблем.
Комбинаторный взрыв. И на языке PLANNER можно написать программу, в которой система выводов приведет к комбинаторному взрыву. Однако этот язык располагает средствами, позволяющими его избежать. Основная идея преодоления возможности комбинаторных взрывов является ведущей для рассматриваемого языка, хотя в приведенных выше примерах на MICRO-PLANNER она и не была достаточно четко проиллюстрирована. Как мы видели, поиск в базе данных можно осуществить с пбмощью функции GOAL, например (GOAL (AT CAT МАТ)), а если мы хотим использовать теоремы, то следует записать (GOAL (AT CAT МАТ) THEOREMS). Уже эти ограничения позволяют управлять количеством операций, которые будут произведены при поиске; но для этого существуют и другие возможности, например: "использовать сначала ниженазванные теоремы...", "использовать только теорему, имеющую следующее имя...", "использовать сначала любую теорему со следующим свойством...", "использовать только теоремы, обладающие следующим свойством...". Это дает возможность включать в программу информацию, которая позволит системе производить нужные выводы без опасности комбинаторных взрывов.
Проблема противоречий. Этой проблемы для языка PLANNER не существует. Поскольку каждый пользователь задает свои собственные теоремы, то он должен заранее задать и теорему, предотвращающую возможность возникновения противоречий в работе программы. Более того, язык PLANNER защищен от одного "частичного противоречия", которое то и дело встречается на практике. Нам хотелось бы иметь утверждение о том, что у всех людей две ноги, и при этом не заботиться о редких случаях, когда это утверждение неверно. С другой стороны, если у Билла одна нога, то нам хотелось бы располагать средствами для фиксации этого факта. PLANNER позволяет сделать это с помощью записи факта "Билл имеет одну ногу" в форме утверждения, а факта "Все люди имеют две ноги" — в форме теоремы. Поскольку при выполнении функции GOAL база данных просматривается первой, утверждение о Билле будет найдено до того, как программа попытается применить к нему общую теорему.
Вывод, управляемый данными, vs. вывод, управляемый целями (data vs. question driven inference). В ИППП трудно осуществлять вывод, управляемый данными, но для PLANNER такая проблема не встает. Именно такой вывод производят антецедентные теоремы.
ОТВЕТ НА ПЯТЬ ВОПРОСОВ
И наконец, посмотрим, как отвечает PLANNER на те пять вопросов, которые были сформулированы в начале настоящей работы.
1. СЕМАНТИЧЕСКОЕ ПРЕДСТАВЛЕНИЕ. В сущности, нет ответа. PLANNER не накладывает никаких ограничений на форму утверждений. Конечно, некоторые сведения следует задавать в форме теорем, и к теоремам предъявляется некоторое требование, а именно о том, что они должны быть записаны на языке PLANNER, но это вряд ли можно считать ограничением.
2. ПРИМЕНЕНИЕ УМОЗАКЛЮЧЕНИЙ. Опять очень мало. Как мы видели, одним из достоинств PLANNER является то, что этот язык не накладывает в этом отношении тех ограничений, что ИППП.
3. ОРГАНИЗАЦИЯ. В этом отношении PLANNER дает ответ, хотя и не вполне определенный. PLANNER предлагает несколько рекомендаций по организации информации. Первая — вызов процедур по образцу. Вторая — наличие средств для выбора нужной теоремы при решении конкретной задачи или при поступлении новой информации.
Однако следует помнить, что PLANNER является языком программирования, поэтому его можно использовать и для работы с другой организацией памяти. Тем не менее было бы справедливо подвергнуть PLANNER критике в том случае, если бы задаваемая им организация информации не соответствовала наилучшим способом решению рассматриваемых нами задач. Как я покажу во второй своей статье, есть основания полагать, что именно так и обстоит дело с языком PLANNER.
4. МЕХАНИЗМ ВЫВОДА УМОЗАКЛЮЧЕНИЙ. Как и ИППП, PLANNER является прежде всего теорией механизма вывода умозаключений. Если имеется теорема на языке PLANNER, то об ее использовании и работе в качестве программы можно не беспокоиться.
5. СОДЕРЖАНИЕ. Снова нет ответа.
ЛИТЕРАТУРА
Green, С. С. Application of Theorem Proving to Problem Solving.— In: Walker and Norton (eds.). Proceedings of the International Joint Conference on Artificial Intelligence, 1969, pp. 219—240.
Raphael, B. SIR: A Computer Program for Semantic Information Retrieval.—In:’’Semantic Information Processing" (ed. by Minsky). Cambridge, Mass., MIT Press, 1968, pp. 33—145.
Sussman G., Winograd, T. and С h a r n 1 a k, E. Micro- Planner Reference Manual.— In: ’’Memoranda from the Artificial Intelligence Laboratory44, 203A. Cambridge, Mass., MIT, 1971.
АНАЛИЗ ПРЕДЛОЖЕНИЙ АНГЛИЙСКОГО ЯЗЫКА (ЧАСТЬ I)[52]
Ряд современных лингвистических работ предлагает разные формальные структуры для представления отдельных предложений или совокупностей предложений естественного языка: трансформационные выводы, исчисление предикатов, деревья порождающей семантики и т. п. [ср. статьи Чарняка и Скрэгга в настоящем сборнике].
Если мы располагаем структурой для представления фрагмента текста (будь то синтаксическая, семантическая или какая-либо иная структура), то можно различать собственно структуру и ее соотношение с фрагментами текста. Среди таких соотношений можно разграничивать анализ (parsing) и приписывание (assignment). Под анализом [53] мы понимаем вполне определенный комплекс прикладных процедур перехода от фрагмента текста к его структуре, а под приписыванием — выработку списка соответствий между фрагментами текста и формальными структурами. Логики часто делают утверждения такого рода: структура предложения John loves his wife’s sister, ‘Джон любит сестру своей жены’, имеет следующий вид:.
EXISTS (X) EXISTS (Y) EXISTS (Z) (X = JOHN AND Y - WIFE (X) AND Z - SISTER (Y) AND LOVES (X, Z))
‘СУЩЕСТВУЕТ (X) СУЩЕСТВУЕТ (Y) СУЩЕСТВУЕТ (Z) (X = ДЖОН И Y = ЖЕНА (X) И Z = СЕСТРА (Y) И ЛЮБИТ (X, Z))’, но они обычно не описывают процесса перехода от исходного предложения к его структуре, считая эту процедуру либо очевидной, либо выходящей за рамки их компетенции. Именно выработку списка соответствий между предложениями естественного языка и формальными структурами я и называю приписыванием.
Теперь остановимся на вопросе о том, каковы отличительные черты анализа. Рассмотрим структуру, задаваемую одной из простейших грамматик — контекстно свободной грамматикой непосредственных составляющих [54]. Такая грамматика может включать, например, следующие правила:
S - NP VP NP -* Determiner Noun VP - Verb NP Determiner -► The, the Noun dog, cat Verb likes
Предложение: The dog likes the cat ‘Собака любит кошку’.
Считается, что предложение The dog likes the cat порождено перечисленными выше правилами подстановки данной грамматики. Грамматика мыслится как устройство, неявным образом определяющее следующую процедуру: в качестве исходного берется символ S (левая часть первого правила), затем он заменяется правой частью этого правила, что дает новые символы, в свою очередь заменяемые по другим правилам (при этом одно и то же правило может быть применено более одного раза — с соблюдением условия, что при применении каждого правила заменяется только один символ). Порождение предложения обычно представляется в виде дерева непосредственных составляющих, изображенного ниже (называемого также НС-структурой предложения), в котором каждое ветвление из произвольного узла соответствует применению одного из указанных правил подстановки (в соответствии с только что описанной процедурой). В конечном счете получаются символы, совпадающие с реальными английскими словами, и процесс останавливается в тот момент, когда каждый конечный символ является английским словом.
NP
VP
Determiner Noun Verb
NP
/ \
Determiner Noun
dog
the
cat
The
likes
Можно считать, что это дерево отражает определенные синтаксические отношения между словами предложения. Так, в данной структуре артикль "The" присоединяется к слову "dog" в результате применения правила "NP -► Determiner Noun", и отношение артикля "The" к ”dog" есть зависимость детерминатива от существительного, которое он определяет. Однако описанный выше процесс порождения можно будет квалифицировать как процесс анализа только в том случае, если, в силу стечения обстоятельств, порожденное нами предложение совпадет с тем предложением, которое мы хотим подвергнуть анализу.
Те исследователи, которые выступают за использование грамматик непосредственных составляющих в качестве инструмента анализа, хотели бы иметь на входе анализа предложение, а на выходе — древесную структуру указанного выше типа. Посмотрим, каким образом это можно было бы осуществить.
Для целей анализа по непосредственным составляющим мы относим каждое слово анализируемого предложения к одной или нескольким грамматическим категориям; в рассмотренном выше предложении, как видно из правил, слово "dog" отнесено к одной категории — Noun.
Существует два способа осуществления анализа: сверху вниз и снизу вверх. Анализ снизу вверх — это более прямой способ; он иллюстрируется ниже. Слова в предложении рассматриваются слева направо, и, начиная с самого левого слова предложения, мы пытаемся заменить каждое слово его категорией, а затем заменять последовательно пары категориальных символов посредством обращенных правил по$- становки данной грамматики — до тех пор, пока мы не дойдем до символа предложения S. Совокупность строк полученного таким образом вывода (фактически перевернутого дерева, изображенного выше) может рассматриваться как синтаксический анализ предложения:
The dog likes the cat Determiner dog likes the cat Determiner Noun likes the cat NP likes the cat NP Verb the cat NP Verb Determiner cat NP Verb Determiner Noun NP Verb NP NP VP S
| ставляют анализ | і предложения. | |
| Looking | for: | S : |
| Looking | for: | NP|VP : |
| Looking | for: | Determiner! : |
| Noun VP | ||
| Looking | for: | Noun|VP : |
| Looking | for: | VP : |
| Looking | for: | Verb|NP : |
| Looking | for: | NP : |
| Looking | for: | Determiner! : |
| Noun | ||
| Looking | for: | Noun : |
| Looking | for: | |
Анализ сверху вниз начинает работу не со слов и их категорий, а просто с символа S, который преобразуется по описанным выше правилам. Осуществляя поиск (looking for) категорий в левой части правил, процедура порождает последовательные цепочки категорий, пока не доходит до категории, непосредственно соответствующей самому левому слову предложения — артиклю ”The“. Далее процедура продолжается так, как показано на нижеследующей схеме, до тех пор, пока она не доходит до самого правого слова предложения; в этом случае строки данной схемы также со-
the dog likes the cat the dog likes the cat the dog likes the cat
the|dog likes the cat the dog likes the cat the dog likes the cat the dog likes the cat the dog likes the cat
the dog likes the|cat the dog likes the cat|
Два указанные выше вывода (снизу вверх и сверху вниз) формально эквивалентны. Знак | (вертикальная черта) в изображенной выше схеме отмечает границу между проанализированной и непроанализированной частями предложения на соответствующем шаге анализа.
Здесь следует сделать ряд замечаний. Анализ вовсе не обязан идти в направлении слева направо: он вполне может идти и в противоположном направлении. Структура предложения редко бывает столь тривиальной, как рассмотренная выше, и обычно слову в словаре приписано несколько допустимых категорий; тогда одна из задач процесса анализа состоит в установлении того, какая из этих ролей слова реализуется в конкретном предложении. Так, слово "run" имеет категорию "Verb" в предложении I run for a bus. ‘Я бегу на автобус.’ и категорию "Noun" в предложении I built a new chicken run. ‘Я построил новую клетку для цыплят.’ (run в данном значении — ‘загон, клетка’). Таким образом, если бы мы обратились к любой из описанных выше процедур для анализа предложения I run for а bus, мы получили бы в результате правильную структуру:
S
/\
NP VP
^ / \
N VP рр
I / \
V р NP
/ \
Det IM
I I
1 run for the bus
и не получили бы структуры, в которой слову run приписана категория ”N“ (Noun), поскольку не существует такой правильной последовательности применений правил грамматики, которая порождала бы дерево данного предложения с узлом N, подчиняющим слово run. Иначе говоря, существует правило:
VP -+ V (и далее V -* run),
но нет правила:
VP N (и далее N -> run).
Тем самым, одно из значений слова run исключается в процессе анализа данного предложения.
Здесь уместно ввести следующие важные специальные термины: анализ ”в ширину“ (breadth-first) и анализ "в глубину1' (depth-first). Анализ ”в ширину"— это параллельная обработка всех возможных альтернативных структур в одно и то же время, причем никакой из них не отдается предпочтения. Все эти структуры обрабатываются одновременно до тех пор, пока одна из них (или несколько) не преобразуется в символ S (если анализ идет в направлении снизу вверх). При анализе "в глубину" альтернативные структуры обрабатываются последовательно, и если некоторая цепочка символов не допускает дальнейшего свертывания (поскольку в данной грамматике к данной цепочке неприменимо никакое правило подстановки, даже если анализ еще не завершен), тогда система должна вернуться назад к одной из альтернативных структур, еще не подвергшихся обработке. Так, например, если бы слову run была приписана категория N в приведенном выше предложении, то, при анализе снизу вверх, сочетание I run было бы заменено цепочкой N N, но в той грамматике, которой мы располагаем, нет правила преобразования цепочки NN во что-либо другое. Именно обнаружение этого факта обусловливает возврат и приписывание слову run категории V (вместо N).
В случае трансформационных структур особенно наглядно видно, что исходное предложение часто анализируется таким образом, что в результате порождается структура, сильно отличающаяся от исходного вида предложения. Обратимся к классическому примеру: пассивное предложение типа I was given the money last week. букв. ‘Я был дан деньги на прошлой неделе.* может получить синтаксическую структуру, которая имеет приблизительно следующий вид (отражающий порядок следования ее основных составляющих): Someone gave me the money last week. ‘Кто-то дал мне деньги на прошлой неделе.* Это позволяет утверждать, что анализ может порождать структуру, совершенно не похожую по своей внешней форме на входное предложение. Программы грамматического анализа трансформационного типа получили широкое распространение в 60-х годах, но здесь они подробно не рассматриваются; мы ограничились лишь введением основных понятий. Это связано с одной из предпосылок настоящей работы, согласно которой грамматический (или синтаксический) анализ описанного типа не является фундаментальным, и он не обязателен даже как предварительный этап при построении семантической структуры предложения. Мы вернемся к рассмотрению этого вопроса ниже, в связи с другими проблемами.
Таким образом, анализ представлен здесь в весьма общем виде, и мы не обсуждаем вопроса о том, являются ли те или иные структуры интересными, то есть заслуживают ли они того, чтобы быть приписанными фразам естественного языка. Более того, структуры определенных типов, например логические структуры, имеют самостоятельный статус независимо от того, получены ли они в результате анализа каких-либо предложений естественного языка. Здесь уместно ввести еще одно противопоставление, важное для последующего изложения. Это противопоставление касается систем ИИ, оперирующих с естественным языком; оно выделяет среди них структурно мотивированные и содержательно мотивированные системы. В нашем изложении мы не будем относить те или иные системы к одному из двух типов, поскольку между этими типами существует множество неопределенных промежуточных случаев, но читателю все же следует помнить об указанном противопоставлении при рассмотрении систем ИИ.
Структурно мотивированными мы будем называть такие системы, которые, независимо от их потенций по обработке естественного языка, направлены на решение преимущественно нелингвистических задач и сосредоточены на соотношении между применяемой в данной системе репрезентацией структур и структурами другого рода (в том числе языковыми). Иначе говоря, структурно мотивированные системы — это такие системы, которые ориентированы на решение достаточно узких нелингвистических задач и которые извлекают из входных текстов на естественном языке лишь ограниченную информацию, релевантную для данной задачи.
К системам такого типа принадлежит система Боброва STUDENT, предназначенная для решения элементарных алгебраических задач (см. Bobrow, 1968; сама система была разработана в 1964 г.). Действительно, STUDENT обрабатывает входные тексты на ограниченном естественном языке, но в этих текстах система реагирует только на наименование некоторых алгебраических отношений, таких, как the sum of ‘сумма’, и т. д. Данная система обладает и другим свойством структурно мотивированных систем, состоящим в том, что получаемые в результате анализа структуры отражают скорее соотношение объектов внутри предметной области, чем то содержание, которое может выражать текст на естественном языке. Так, STUDENT использует в качестве "семантического представления" линейные уравнения, поскольку они наиболее удобны при решении алгебраических задач. Аналогичным образом можно утверждать, что использование во многих ранних системах представлений на языке исчисления предикатов объясняется прежде всего пригодностью этого языка для решения простых логических задач, на которые были ориентированы соответствующие системы, а не его способностью передавать содержание языковых высказываний.
В строгом смысле проблема понимания естественного языка сводится к представлению содержания. Именно эта проблема является центральной в работах по автоматизации анализа текстов на естественном языке со времени начала этих работ (50-е годы), и ядро этой проблемы составляет вопрос о системной неоднозначности. Короткий критический экскурс в историю, возможно, прояснит существо дела. В "эру машинного перевода" 50-х и начала 60-х годов предпринимались смелые попытки осуществить труднейшую задачу — автоматизировать извлечение содержания высказываний на естественном языке. Эти попытки закончились неудачей по трем основным причинам: неоднозначность слов (омонимия и полисемия), структурная неоднозначность предложений (мы рассмотрим только неоднозначность глубинных падежей на примере неоднозначности предлогов) и референционная неоднозначность (неоднозначность местоимений). Средства разрешения неоднозначности указанных типов не удалось разработать и реализовать даже для текстов, лишенных метафоричности. Возникновение генеративной лингвистики отчасти обусловлено именно неудачей этих попыток: она предложила сложные структуры для лингвистического анализа, однако утратила ориентацию на решение какой-либо определенной задачи; одним из недавних свидетельств этой утраты направляющей нити исследования явился окончательный отход от ориентации на анализ и переход к учению о том, что истинной структурой языка является его логическая структура.
Итак, мы подошли к области ИИ, характеризующейся возвращением к ориентации на решение определенных задач и разработку определенных процедур, а также медленным, но верным отступлением от структурно мотивированного подхода. Самые ранние работы в рамках ИИ характеризовались высокой структурной мотивированностью: многие ведущие исследователи в ИИ считали очевидной аксиомой, что базисной формой представления текстов на естественном языке является исчисление предикатов. Их интересовало в основном доказательство теорем посредством вывода одной формулы исчисления предикатов из другой; при таком подходе ”проблема естественного языка" даже не вставала, поскольку три упомянутых выше случая языковой неоднозначности ими просто игнорировались. По-видимо- му, они действительно считали естественный язык проекцией некоторой исходной логической схемы. Постепенно реальное положение дел стало давать о себе знать. Недавно Терри Виноград (W і п о g г a d, 1973) в обзоре систем ИИ, работающих с естественным языком, провел разграничение между системами "первого" и "второго" поколения, а свою собственную систему (см. о ней ниже) скромно отнес к концу первого поколения. Мы не будем рассматривать это разграничение; отметим только, что системы, отнесенные Виноградом к первому поколению, практически совпадают с системами, которые характеризовались выше как структурно мотивированные.
СИСТЕМА ПОНИМАНИЯ ЕСТЕСТВЕННОГО ЯЗЫКА ВИНОГРАДА
Чтобы лучше понять некоторые из затронутых выше проблем, вероятно, удобнее всего начать с рассмотрения системы самого Винограда. Его система работает в режиме письменного диалога на дисплее между человеком-операто- ром и самой системой, называемой SHRDLU, в реальном масштабе времени. На дисплей система выводит и картину своего ограниченного мира, состоящего из цветных параллелепипедов и пирамид, ящика, в котором они могут быть размещены, и "руки" (рычага), которая может передвигать объекты данного мира.
Ниже предлагается образец диалога, приводимый в книге Винограда. Ответы системы SHRDLU даются прописными буквами:
pick up the big red block ‘подними большой красный параллелепипед’
OK ‘Хорошо’.
find a block which is taller than the one you are. holding and put it into the box
‘найди параллелепипед, который выше того, который
ты держишь, и положи его в ящик’.
BY ”IT“, I ASSUME YOU MEAN THE BLOCK WHICH IS TALLER THAN THE ONE I AM HOLDING OK
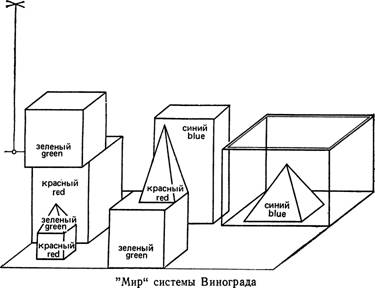
‘Под словом IT, как я полагаю, вы понимаете параллелепипед, который выше того, который я держу’ ‘Хорошо’ What does the box contain?
‘Что содержит ящик?’
THE BLUE PYRAMID AND THE BLUE BLOCK ‘Синюю пирамиду и синий параллелепипед’
Had you touched any pyramid before you put the green one on the little cube?
‘Касался ли ты какой-либо пирамиды до того, как ты поставил зеленую пирамиду на маленький кубик?’
YES, THE GREEN ONE ‘Да, зеленой пирамиды’
When did you pick it up?
‘Когда ты ее поднял?’
WHILE I WAS STACKING UP THE RED CUBE, A LARGE RED BLOCK AND A LARGE GREEN CUBE ‘Когда я ставил один на другой красный кубик, большой красный параллелепипед и большой зеленый кубик’
why?
‘зачем?’
TO GET RID OF IT
‘чтобы убрать ее’
Эта оригинальная программа способна также (в ограниченном объеме) воспринимать новые определения слов, например слова steeple ‘башня’; использовать свои знания о свойствах описываемых объектов, например, то, что на верхней поверхности параллелепипеда может находиться некий объект и его можно оттуда снять, а на пирамиде — не может; а также запоминать свои действия, как было видно в приведенном выше примере диалога.
Программа синтаксического анализа была написана на языке PROGRAMMAR — языке процедур, близком к языку PLANNER. Это означает, что знакомое нам НС-правило типа
S *NP + VP
(интерпретируемое следующим образом: предложение состоит из именной группы и следующей за ней глагольной группы) будет выражено так:
(PDEFINE SENTENCE
(((PARSE NP) NIL FAIL)
((PARSE VP) FAIL FAIL RETURN)))
Мы не будем останавливаться на деталях данной системы записи; отметим только одно важное свойство грамматики Винограда, состоящее в том, что она представляет собой не условный список правил, а набор небольших подпрограмм (типа указанной выше), которые действительно задают процедуры для выработки нужной грамматической структуры.
В лингвистических процедурах синтаксического уровня рассматриваемой системы используется ’’системная грамматика" М. А. К. Холлидея (Н а 1 1 і d а у, 1970), с помощью которой входной фразе ставится в соответствие структура, задающая иерархию вхождений в эту фразу составляющих простых предложений (clauses). Входные фразы составляются на материале словаря, насчитывающего приблизительно 175 слов.
Если обратиться к введенным выше понятиям, то синтаксический анализ Винограда можно охарактеризовать как направленный сверху вниз, ориентированный ”в глубину“, без автоматических возвратов. Любой стандартной программе, соответствующей грамматической категории, отвечает функциональное определение на языке PROGRAMMAR, которое может быть сформулировано либо так, как это сделано выше для SENTENCE, либо в виде блок-схемы, как это показано ниже для категории VP:
ОПРЕДЕЛЕНИЕ программы VP
Приведем комментарий Винограда к началу работы процедуры анализа сверху вниз для предложения Pick up a red block. ‘Подними красный параллелепипед.’ (в квадратные скобки заключены мои пояснения):
«Программа CLAUSE берет первое слово предложения, чтобы определить, с какой единицы начинается предложение. Если это наречие, то программа предполагает, что предложение начинается с однословного модификатора [например: Slowly, Jack lifted the book. ‘Медленно Джек поднял книгу.’]; если это предлог, она ищет начальную предложную группу PREPG [например: On the top of the hill stood a tree. ‘На вершине холма росло дерево.’]. Если это подчинительный союз (BINDER), программа вызывает программу для поиска придаточного предложения (BOUND CLAUSE) [например: Before you got there, we left. ‘До того, как вы пришли туда, мы ушли.’]. В английском языке (невероятно, во всех языках) первое слово конструкции хорошо прогнозирует ее тип. В данном случае первое слово предложения pick — это глагол, оно указывает, что здесь возможно повелительное предложение (IMPERATIVE CLAUSE). Программа вызывает программу обработки глагольных групп (VG) и подает на ее вход исходный набор признаков: VG IMPER. Программа обработки VG ищет группу с данными признаками. Такая группа может начинаться либо с формы вспомогательного глагола do [Do not call me! ‘He зови меня!’], либо со смыслового глагола [Call mel ‘Позови меня!’]. Если предложение начинается не с формы глагола do, программа проверяет, не является ли следующее (а в нашем примере — первое слово) формой инфинитива. Если это так, то слово вводится в синтаксическое дерево и получает дополнительный признак MVB (main verb — смысловой глагол). Полученная к этому моменту структура может быть схематически изображена так:
(CLAUSE MAJOR)
(VG IMPER)
(VB MVB INF TRANS VPRT)........................................... pick
Символы TRANS и VPRT были получены из словарного определения глагола pick по функции PARSE».
После завершения синтаксического анализа ряд программ, называемых ’’семантическими специалистами", приписывает полученным синтаксическим структурам семантические структуры. Так, для словосочетания a red cube ‘красный кубик’ семантический специалист по именным группам (NP) строит следующую структуру:
(GOAL (IS ?Х BLOCK))
(GOAL (COLOR ?X RED))
(BLOCK MANIP PHYSOB THING) признаки
‘(ПАРАЛЛЕЛЕПИПЕД ПОДВИЖНЫЙ ФИЗ. ОБЪЕКТ ВЕЩЬ)’.
Первые три строки — это основа программы на языке MICRO-PLANNER; эта часть программы после надлежащей проверки будет искать объект X, который является параллелепипедом (BLOCK) с равными гранями (EQDIM) и имеет красный цвет (RED) (само прилагательное red ‘красный’ определено в системе таким образом, что оно может соединяться только с существительными, которым приписан признак PHYSOB ‘физ. объект’). Последние две строки представляют набор семантических признаков, получаемых из приведенного ниже "дерева признаков" при движении по строке справа налево [55] (см. с. 222).
Дедуктивный компонент системы до того, как осуществить определенное действие (например, поднятие объекта), проверяет семантическую структуру некоторых словосочетаний (в частности, именной группы the red cube ‘красный кубик’) с целью выяснения возможности существования объекта, описываемого этим словосочетанием. Если такого объекта не существует (например, не существует объекта, соответствующего словосочетанию equidimensional pyramid ‘пирамида с равными гранями’), система может вернуться назад и попытаться проанализировать предложение иначе.
Смысл глаголов в SHRDLU задается более сложным образом. Семантический компонент обращается к определению (или толкованию) глагола (например, глагола pick up), как и в случае семантического анализа прилагательных (red)m существительных (cube), и строит с помощью этого определения соответствующую подпрограмму на языке MICROPLANNER, аналогично тому, как это делается для именных групп.
Однако здесь встречаются два затруднения. Во-первых, pick up, в отличие от red, определяется посредством других понятий системы, а именно — GRASP ‘брать’ и RAISE- HAND ‘поднимать руку’, являющихся двумя основными
JNAME і ‘имя’
PLACE
‘место’
COLOR ‘цвет’
ANIMATE ‘одушевленное’
PROPERTY-- ‘свойство’
SHAPE
‘форма’
SIZE
‘размер’
LOCATION
‘пространственные
ROBOT
‘робот’
HUMAN
‘человек’
координаты’
BLUE ‘синий’ RED ‘красный’ BLACK ‘черный’ WHITE ‘белый’
THING- ‘вещь’
| ( ! GREEN’ | (STACK | |
| PHYSOB........... | ( ! ‘зеленый’ | і ‘башня’ |
| ‘физический объект’ | ( CONSTRUCT - - | -- -(PILE |
| ( ‘конструкция’ | і‘куча’ | |
| ( HAND | (ROW | |
| ( ‘рука’ | і ‘ряд’ | |
| (- - TABLE | {PYRAMID І‘пирамида’ j BLOCK | |
| ‘стол’ | ||
| І 1 | MANIP............... | |
| ‘подвижный’ | І 'паралле- 1лепипед’ {BALL і ‘шар’ | |
| RELATION - - • | ................ (EVENT | |
| j ‘отношение’ | ! ‘событие’ |
I TIMELESS I ‘вневременное’
действиями в системе (из трех возможных). Во-вторых, существуют два типа определений глаголов — семантические и логико-функциональные (inferential). Виноград не дает семантического определения для pick up, но для близкого
по смыслу глагола — grasp — такое определение имеется.
Определение глагола grasp (CMEANS ((((ANIMATE)) ((MANIP)))
(EVAL (COND ((PROGRESSIVE)
(QUOTE (GRASPING 2 *TIME)))
(T (QUOTE (GRASP 2 *TIME)))))
NIL))
Основная информация этого определения сводится к тому, что действие grasp осуществляется неким одушевленным существом (ANIMATE) над каким-либо подвижным объектом (MANIP) — ср. первую строку. В логико-функциональных определениях действий такого рода их реальное содержание передается более четко. Ниже приводится логико-функциональное определение действия pick up:
(CONSE ТС — PICKUP (X)
(PICKUP ?X)
(GOAL (GRASP ?X) THEOREMS)
(GOAL (RAISEHAND) THEOREMS))
Приведенное определение позволяет программе реально выполнить команду ’’pick up“, если это в данном случае вообще возможно в моделируемом мире (так, нельзя было бы поднять красный параллелепипед, если бы на нем был уже расположен другой параллелепипед). PICKUP определяется в терминах других, более простых поддействий, таких, как GRASP и RAISEHAND, каждое из которых должно быть выполнено для того, чтобы некоторая вещь могла быть действительно поднята. Сами эти поддействия также имеют логико-функциональные определения: например, логико-функциональное определение для GRASP несколько отлично от его семантического определения (CMEANS), приведенного выше, хотя в некотором отношении можно считать, что логико-функциональные определения, как и программы, реально выполняющие соответствующие команды, тоже задают смысл глаголов.
Одной из причин огромной популярности системы Винограда является то, что до этого работы в области ИИ не представляли лингвистического интереса, а в построениях лингвистов не рассматривались вопросы представления зна- ний и вывода умозаключений. Поэтому даже ограниченное объединение двух указанных методов позволило достичь значительных результатов. До работ Винограда лишь несколько программ в области ИИ могли обрабатывать достаточно сложные английские предложения и приписывать им синтаксические структуры. В ранних "классических" системах ИИ, направленных на "понимание естественного языка", таких, как система Боброва STUDENT (1968 г.), которая решала простые алгебраические задачи, входные предложения резко ограничивались в длине и имели стереотипный вид, например: What is the sum of...? ‘Какова сумма...?’.
Что же касается лингвистики, то в ней до недавнего времени очень мало внимания уделялось тому, как мы устанавливаем кореферентные связи в таких простых фразах, как The soldiers fired at the women and I saw several fall. ‘Солдаты открыли огонь по женщинам, и я видел, как некоторые упали.’ В этом примере антецедент several (women, но не soldiers) устанавливается с полной определенностью, но для этого необходим ряд умозаключений, относящихся к положению дел в реальном мире. Читатель может спросить себя, каким образом он сам установил референт several в этой фразе.
Еще по теме ЯЗЫК ПРОГРАММИРОВАНИЯ PLANNER:
- 1.Соотношение понятий: праславянский язык, старославянский язык, древнерусский язык, церковнославянский язык. Источники сведений об этих языках.
- Язык. понятие, ф-ции, формы сущ, нац. Язык, совр литерат русский язык
- АБСТРАКТНЫЙ ЯЗЫК И КОНКРЕТНЫЙ ЯЗЫК. ЯЗЫК КАК ИСТОРИЧЕСКИ ОБУСЛОВЛЕННОЕ «УМЕНИЕ ГОВОРИТЬ». ТРИ ПРОБЛЕМЫ ЯЗЫКОВОГО ИЗМЕНЕНИЯ
- современный русский язык. Национальный язык и формы его бытования. Литературный язык как высшая форма национального языка.
- Многофункциональность русского языка: русский язык как средство, обслуживающее все сферы и типы общения русского народа. Литературный язык и язык художественной литературы.
- Русский язык – язык русской нации. Русский язык как средство межнационального общения народов СНГ.
- § 1. Содержание понятия «русский язык». Понятие «русский язык» охватывает несколько разновидностей, в которых существует и развивается язык русской нации.
- Дробно–линейное программирование
- РУССКИЕ ЯЗЫК — ЯЗЫК МЕЖНАЦИОНАЛЬНОГО ОБЩЕНИЯ НАРОДОВ СССР
- § 3. Русский язык — язык межнационального общения народов СССР.
- Линейное программирование
- Исходный (родной) язык и целевой (иностранный) язык
- 7.1. Задачи линейного программирования
- Политический язык выдает себя за неполитический язык
- Приложение 3В. Линейное программирование
- 4.6. Логическое программирование
- § 40. РУССКИЙ язык - НАЦИОНАЛЬНЫЙ язык РУССКОГО НАРОДА