Краткие гласные в турецком языке образуют законченные, стройные систем
Краткие гласные в турецком языке образуют законченные, стройные системы, этим и объясняется тот факт, что они довольно часто становятся центром внимания работ по общему языкознанию, в которых они ставятся в один ряд с такими системами гласных, как северозападно-кавказская, в которой имеется всего одна или вообще ни одной гласной (а или 0), или же широко распространенная фонологическая система, представленная, например, в эскимосском и арабском языках, где противопоставлены гласные, образованные тремя крайними вокалическими артикуляциями (а, — і, — и).
Некоторые из предлагаемых в данной работе мыслей уже высказывались в печати (см. L о t z 1962)1. Мы надеемся, что наша статья будет способствовать пробуждению интереса алтаистов к теоретическим проблемам турецкого вокализма, представляющего собой интересный, но малоразработанный материал.1. Как известно, в турецком языке восемь кратких гласных. Долгие гласные (встречающиеся не во всех пластах лексики языка) нас здесь интересовать не будут. В современной турецкой орфографии они обозначаются следующими восемью буквами: і, е, й, о, і, а, и, о.
Количество возможных и в то же время максимальных различий между этими восемью элементами может быть определено путем постановки каждой гласной в оппозицию каждой другой гласной. Так, если следовать порядку, принятому
J. L о t z. The Turkish vowel system and phonological theory. — In: «Researches in Altaic linguistics», Budapest, 1975, pp. 137—145.
© Akademiai Kiado, Hungary, 1975
выше, і нуждается в семи противопоставлениях с остальными гласными (самому себе оно, конечно, противопоставлено быть не может); в этом случае е требует шести дополнительных противопоставлений, так как его различительные признаки по отношению к предшествующему і уже установлены; й — пяти, о—четырех, і—-трех, а —двух и, наконец, и —одного.
Последняя гласная противопоставлена остальным гласным в ходе предшествовавших операций. Подведем итог:D = 7 + 6 + 5 + 4 + 3 + 2 + l = 28,
где D обозначает число противопоставлений. В общем виде формула числа противопоставлений в множестве из п элементов выглядит так:
Dn = (n —1) + (п —2) + ...+ 2 + 1.
Менее громоздким способом можно получить D путем следующего рассуждения. Каждый элемент отличается от всех остальных элементов, то есть для каждого элемента имеется п — 1 противопоставление. Но эта процедура учитывает каждое противопоставление дважды, для каждой пары элементов. Следовательно, общий вид формулы:
Г, = п(п-1)
2
а в приложении к турецкому языку
D = 28.
Такое большое число различительных единиц было бы огромной нагрузкой на механизм артикуляции и восприятия носителя языка, как говорящего, так и слушающего, следовательно, нужно искать более эффективную модель, сократившую бы это число.
2. Способ сокращения этого числа был предложен Радло- вым в 1882 г. в его фонетическом описании северно-тюркских языков. Правда, разработка этого способа была осуществлена не на материале самого османско-турецкого, а на материале телеутского языка, однако телеутская система гласных изоморфна турецкой, поэтому метод Радлова можно использовать и для анализа турецкой системы (Radloff
1882). Указанные восемь гласных были расклассифицированы по трем артикуляторным параметрам следующим образом (в скобках указываются более общепринятые термины):
(1) По палатальности (горизонтальному положению языка) : 4 гуттуральных (гласных непереднего ряда) а о і и 4 палатальных (гласных переднего ряда) е о і й
(2) По лабиализации (огубленности):
4 дентальных (неогубленных гласных) а і е і 4 лабиальных (огубленных гласных) о и о й
(3) По степени открытости (вертикальному положению языка) :
4 широких гласных (открытых, гласных неверхнего подъема) а е о о
4 узких гласных (закрытых, гласных верхнего подъема) і і и и
В этой системе каждая гласная единообразно описывается с точки зрения ее соотнесенности с каждым из этих классов по трем артикуляторным параметрам.
Два взаимоисключающих значения каждого параметра можно обозначить как 1 и 0 соответственно.| А | в | с | ||
| горизонтальное | огубленность | вертикальное | ||
| положение | положение | |||
| языка | языка | |||
| а | 1 | 1 | 1 | |
| і | 1 | 1 | 0 | |
| о | 1 | 0 | 1 | |
| гласные | U | 1 | 0 | 0 |
| е | 0 | 1 | 1 | |
| і | 0 | 1 | 0 | |
| о | 0 | 0 | 1 | |
| ii | 0 | 0 | 0 | |
Схема 1
Алгебраически каждая гласная определяется на основе всех трех измерений (неупорядоченно), то есть Гласная = А и В и
С (где каждый элемент имеет значение 1 или 0). Отметим, что 1 и 0 — обозначения для позитивно определенных сущностей, и, следовательно, они не включают понятия маркированности, о котором речь пойдет ниже.
Подобная параметризация используется во всех современных структурных описаниях, в случае если два подкласса в каждом артикуляторном измерении интерпретируются как члены бинарной оппозиции. Способом репрезентации в этих случаях также является матрица, в которой два противопоставленных подкласса обычно обозначаются знаками «+» и «—».
| а | 1 | о | U | е | о | і | U | |
| задний | + | + | + | + | — | — | — | — |
| огубленный | — | — | + | + | — | + | — | + |
| открытый | + | — | + | — | + | + | — | — |
Схема 2
Такая система представления впервые была приведена в «Языке» Блумфилда (Bloomfield 1964). У Якобсона она впервые появляется в явном виде в его «Классификации», а позже и в других работах2.
При бинарном распределении по трем измерениям, показанным на схеме 2, выбор противопоставлений сводится к трем, максимально различающим восемь единиц по формуле:
D = 23=8.
Отметим, что в этой модели отсутствуют направленность и упорядоченность.
Чтобы не быть связанным двумерностью листа бумаги, которая вынуждает устанавливать иерархию даже там, где для такого решения нет ни малейших оснований, я в 1942 г. представил эти оппозиции в виде трехмерного структурного графа3.
Обычное распределение таково:
Схема З
Конечно, кубическая интерпретация не содержит никакой новой информации, и опять же, как и в случае матрицы, куб не ориентирован.
3. Имеется и другая теоретическая возможность — ввести в эти оппозиции понятие маркированности, поставив в соответствие более общему элементу более специфический и, таким образом, придав кубу ориентацию. В случае с турецкими краткими гласными из рассмотрения фактов становится ясно, что і является более простым, чем й,а и более простым, чем і, так как фильтр и воздушная масса усиливают друг друга в первом случае и противодействуют друг другу во втором. Но для і и и трудно понять, как они противопоставлены или как они различаются по маркированности. Поэтому мы отвергаем маркированность в качестве общего принципа, хотя принимаем ее значимость для некоторых, возможно многих, явлений в языковых системах.
Иерархия оппозиций представляет еще более сложную проблему.
4. Мы не будем рассматривать речь в артикуляционных терминах, такой подход вносит элемент импрессионизма; ярлыки типа «огубленность», использованные в начале статьи, не опираются на физические измерения и статистику, поэтому можно заключить, что такие этикетки не вносят никакого вклада в описание звуковой системы.
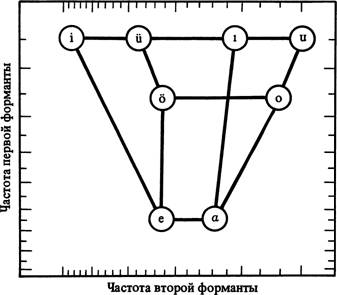
5. Если рассмотреть лежащие в основе речи физические процессы, получается картина, отличная от приведенных выше моделей; ее можно более четко сформулировать в физических терминах. Представление физико-акустической картины явления во многих отношениях отличается от фонематически различительного. Если попытаться охарактеризовать исходную физическую звуковую модель турецких кратких гласных, картина получится примерно такая (см. схему4)4.
В подобном акустическом анализе различия между гласными уже не представляются в виде абсолютной величины, как это описано выше, а определяются частотными зонами формант (числом колебаний в секунду), в основном их центром, который характеризуется числом формант или их пропорций.
Гун нар Фант показал, что эта величина для речевого аппарата человека определяет состояние голосового источника, то есть амплитуду и частоту колебаний голосовых связок (Fant 1960). Таким образом, это число содержит полную физическую характеристику звука.Используя физико-акустические измерения как отправной пункт, мы устанавливаем базовые единицы в языковой системе турецких кратких гласных, которые характеризуются числами и измерениями, а не абстрактными соотношениями. Там, где в фонологическом пространстве у нас имеется разрыв, в акустическом анализе мы получаем определенную измеримую разницу, например, фонологически і и й отличаются абсолютно, а в нашей гипотетической модели они различаются акустически на октавы во второй форманте. И в то время как фонологическое пространство трехмерно, акустическое пространство, по-видимому, двумерно^.
На схеме 4 показано, что о и о находятся в отношении первой форманты на том же уровне, что а и е, в то время как все высокие гласные находятся относительно первой форманты на одном уровне. Данный физический факт соответствует морфологической особенности турецкого — в этом языке имеются чередования а ~ е и і ~ й ~ і ~ и, но не о ~ о. (Это относится не ко всем турецким диалектам.) Итак, акустический анализ не подтверждает предположения, что систему турецких гласных отражает кубическая структура.
о
о
О О О
о о о
о т о
СО (N
о
о
о
о
о
г-
300 ~
Схема 4. Акустическое представление турецких гласных по двум формантам (гипотетическое)
400~
500 ~ 600-
700-
800~ 900— 1000-
6. Немногое может дать рассмотрение психологического пространства турецкого вокализма. Современные исследования природы психологического восприятия не предоставляют возможности для подходящей интерпретации. Психологическое пространство явно связано с физическим, но переинтер- претируется с помощью психологического механизма, в котором могут играть роль некоторые другие соображения. Сюда входят:
(1) Дистрибутивные данные; например, такие, как турецкий сингармонизм, который устанавливает ассоциативные связи между подгруппами системы гласных.
(2) Психологическое сходство, основанное на фонетичес-
ких особенностях; например, і и и психологически крайние по ряду высокие гласные, в то время как й и і находятся между этими двумя крайностями.
Частота встречаемости; например, і и и статистически более частотны, чем звуки, находящиеся между ними. Рифмовка; так, Трубецкой приводит интересный пример того, как в некоторых тюркских языках высокие гласные і, іі, і и и все рифмуются друг с другом в непервых слогах, где их встречаемость определяется и предписывается гласной первого слога (Trubetzkoy 1937). Сюда входят только предсказуемые различительные единицы, а в первом слоге, где их употребление свободно и непредсказуемо, они не рифмуются. Другой пример психологического сходства определенных единиц имеется в венгерском, где три апикальных глухих: t, s, с; из них s и с могут в некоторых условиях рифмоваться, но t — плохая рифма для обоих. Это показывает, что психологически s ближе к с, чем каждое из них к t, хотя фонологическая разница между всеми тремя абсолютна. Ср. также английские [s] и [Й] или [f] и [0].
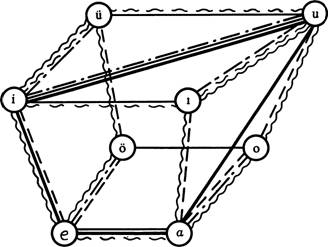
Неволнистые линии = фонетические связи ■■ крайняя артикуляция
передний — задний
— — высокий — низкий
------------------ огубленный — неогубленный
Волнистые линии = морфофонемные связи
— — -—• дистрибутивно связанные гласные
----------- гласные, связанные по суффиксальным чередованиям
Если можно построить психологическую модель гласных, связи между единицами в ней будут градуальными (скалярными) , а не отношениями абсолютного различия, как в пространстве фонологической структуры, или континуально измеримого различия, как в фонетико-акустическом пространстве. Сложность психологического пространства иллюстрируется схемой 5, где представлены только первые две группы факторов, обсуждавшихся выше.
7. В наших рассуждениях предполагалось, что единицы, то есть 8 турецких гласных, установлены лингвистически (исходя из социальных или культурных критериев) и что их количество одно и то же во всех структурах, которые варьируют не по числу единиц, а по природе и составу связей. Имеется взаимно-однозначное соответствие единиц во всех структурах, хотя при передаче речи отклонение в предшествующем речевом образе может не дать никаких различий в следующем звене, и хотя сами структуры могут отличаться.
В качестве последнего штриха можно добавить, что в случае с турецкими гласными физико-психологическое пространство получает эпистемологическое преобладание и характеризуется физическими и психологическими измерениями (то есть метрическими и скалярными). Предполагаемые фонологические языковые системы являются абстракциями, основанными на физико-психологической реальности и сделанными ради особых целей, которые часто ставятся и понимаются смутно, как в случае с маркированностью. Фонологические системы выводимы из физико-психолого-фонологического пространства, но не наоборот. Таким образом, следует помнить, что лингвистическая фонетика более первична, чем структурная фонология, и что между ними нет дихотомии, которую постулируют некоторые структуралисты.
Истинная задача фонологического исследования — установить лингвистически релевантные единицы, определить артикуляторное, акустическое и психологическое содержание этих единиц, рассчитать структурные связи между этими единицами в каждом звене передачи и, наконец, доказать, что одно из этих звеньев, то есть моторное или слуховое, в определенном смысле первично, а остальные производны; или верифицировать и интерпретировать абстрактную фонологическую модель. Таким образом, предпочтение фонологии должно быть в первую очередь отдано физико-психологическому анализу языковых звуков данной звуковой системы, а затем четкому и ясному пониманию того, для какой цели используется данная структура.
ПРИМЕЧАНИЯ
1 Я хотел бы поблагодарить лиц, принимавших участие в обсуждении данной статьи: профессора Садеттина Булука, доктора Дьердя Хазаи и доктора Эдена Шутца за сделанные ими замечания.
2 См. Jakobson 1939 (краткое изложение в «Slovo a slovesnost», IV, 1939, с. 192) nJakobson,Fant, Halle 1952.
3 Впервые предложено в Lotz 1942, с. 119—146. То же представление предлагалось на VI международном конгрессе лингвистов в Париже (1948 г.), где подобным образом анализировались и другие языковые области (см. Actes 1949, с. 467). Позже куб турецких гласных появлялся и в других работах, например Deny 1955 и Gleason 1955. Обширное обсуждение см. в Deny 1959, особенно раздел 22, с. 187— 191.
4 Данные для этой схемы основаны на экспериментах по синтезу речи, проводимых в лабораториях Хаскина (см. Delattre, Liberman, Cooper, Gerstman 1952, с. 200). Для получения более подробного и содержательного ответа следует провести всесторонний статистический и акустический анализ турецких гласных.
5 Интересно отметить, что Трубецкой в Trubetzkoy 1929 и Trubetzkoy 1938 предложил двумерное расположение, согласно анализу гласных по Штумпфу (Stumpf 1926), и различал Eigenton (собственный тон) и Schalfulle (насыщенность) :
Eigenton
о а о е
Schalfulle
и і и і
В настоящей работе общие проблемы фонологической структуры слова в турецком языке рассматриваются с привлечением критерия, позволяющего учесть ряд конкретных признаков. Поставленную нами задачу можно сформулировать так. Предположим, что существует язык, в фонологической системе которого различаются три фонемы, А, В и С, и что верятность (Р) их встречаемости Р (А) > Р(В) > Р (С). Встает вопрос, какие именно слова с этими фонемами встретятся в словаре данного языка. Словарь явно должен содержать следующие слова: 1. ABA 1. АСА
2. ABC 2. АСВ Вероятность того, что в слове могут встретиться рядом две одинаковые фонемы, практически исключается. Интуитивно можно предположить, что, исключив слова типа AAA, ААВ, АВВ и т.п. из словаря воображаемого языка, мы получим более адекватное приближение к модели естественного языка. Таким образом, если фонема F занимает і-ю позицию в слове, вероятность ее встречаемости в позиции і+1 практически равна нулю. Вероятность встречаемости F в позиции i+k, где к= 1,2..., является переменной, зависящей от статистических закономерностей.
На основании имеющихся данных о вероятности встречаемости фонем в нашем гипотетическом языке можно полагать, что слова, приведенные выше в левой колонке, скорее встретятся в словаре, чем слова, записанные в правой колонке, и что первое слово каждой колонки встречается с большей
Ludek Hrebicek. The phonological structure of the Turkish words. — «Asian and African studies», v. III. Bratislava, 1967, pp. 50—59.
вероятностью, чем второе. Однако эмпирические данные, полученные на материале многих естественных языков, позволяют заключить, что в естественном языке действует одновременно множество факторов, образующих набор значимых условий, которые нельзя игнорировать. Поэтому встречаемость фонем описывается в терминах условной вероятности. Так, в нашем случае Р (С/В) > Р (А/В), то есть вероятность С при предшествовании В больше, чем вероятность А при том же условии. Значит, вероятность появления в словаре слова типа ABC больше, чем вероятность для первого слова левой колонки. В естественном языке условия более сложны, и встречаемость фонемы определяется как частотностью одной фонемы, так и совместным появлением двух, трех и т.д. фонем, в свою очередь связанных отношениями взаимной зависимости. Образуется сложный комплекс отношений, который лишь в небольшой степени удается постичь при помощи существующего лингвистического аппарата. Аналогичная ситуация имеет место при наложении фонологической структуры на слоговую и морфологическую структуру слова.
Сложный характер отношений между единицами обусловливает и выбор метода исследования их структуры: допускается, что она поддается количественному анализу. Наш метод носит эмпирический характер. Принимается только одно теоретическое допущение: слово рассматривается как последовательность позиций. В каждой позиции встречаемость фонем описывается в терминах абсолютной частоты. На эту частоту влияют описанные нами взаимозависимости фонем, выраженные в их условных вероятностях и в вероятностях появления в і-й и (i+k) -й позициях (частный случай условия). Распределение фонемных частот в определенной позиции характеризует относительную позицию. Сравнение двух таких распределений по двум позициям, позволяет судить о противопоставлении данных позиций, которое мы будем называть позиционным контрастом. Итак, позиционный контраст —это соотношение двух позиций, каждая из которых характеризуется дистрибуцией частот встречающихся в ней фонем.
Отношение между двумя подобными дистрибуциями определяется при помощи коэффициента корреляции. Мера позиционного контраста и коэффициент корреляции находятся в отношении дополнительной дистрибуции: с ростом коэффициента корреляции падает мера контраста и наоборот.
Словарь турецкого языка содержит три пласта лексических единиц: исконные турецкие слова, неологизмы и заимствования. Эти три группы слов изучаются отдельно друг от друга. Слово рассматривается как единица, способная присоединять словоизменительные и словообразовательные показатели. Это значит, что в словаре как независимая лексическая единица представлена основа слова, а также ее производные. Из всего комплекса единиц, составляемого основой и производными, отбиралось для анализа одно слово. Для глаголов отбиралась форма повелительного наклонения (а не .форма с суффиксом -mak/-mek). В работе был использован турецкорусский словарь Д. А. Магазаника (Магазаник 1945). На каждой из 694 страниц словаря отбиралось по три слова так, чтобы каждое слово принадлежало к разным пластам лексики, названным выше. Если на данной странице словаря не встречалось слова из какого-то лексического пласта, отбиралось менее трех слов. Опытный словарь составили: 581 исконное турецкое слово с общим числом фонем 3587, 357 неологизмов с числом фонем 2405 и 659 заимствований с числом фонем 4123.
Результаты статистического анализа приведены в табл. 2, 3, 4, где показаны абсолютные частоты фонем по единичным позициям. Набор фонем за небольшими исключениями совпадает с тем набором, который приведен в работе Lees 1961, с. 5—6, за вычетом фонем, присутствующих в нормативном языке, но не в разговорной речи.
Для каждой фонемы определялось соотношение частот ее встречаемости в двух позициях. Для этого применялся непараметрический коэффициент ранговой корреляции Спирмана, основанный на ранжировании взаимозависимых значений. Абсолютные значения частоты фонем переводились в ранговые значения, и определялось квадратичное отклонение; ср., например, данные для первой и второй позиций в исконных турецких словах (см. ниже таблицу 2).
| Фонема | Позиция 1 | Ранг 1 | Позиция 2 | Ранг 2 | d = r(l)-r(2) | d2 |
| і | 31 | 7 | 39 | 3 | 4 | 16 |
| і | 2 | 28 | 35 | 6 | 22 | 484 |
| U | 6 | 22,5 | 21 | 7 | 15,5 | 240,25 |
| U | 9 | 18 | 36 | 5 | 13 | 169 |
| е | 21 | 12 | 104 | 2 | 10 | 100 |
| а | 47 | 4 | 149 | 1 | 3 | 9 |
| 6 | 8 | 20 | 17 | 8 | 12 | 144 |
| о | 11 | 15,5 | 38 | 4 | 11,5 | 132,25 |
| і: | 0 | 31,5 | 0 | 32 | 0,5 | 0,25 |
| и: | 0 | 31,5 | 0 | 32 | 0,5 | 0,25 |
| е: | 0 | 31,5 | 0 | 32 | 0,5 | 0,25 |
| m | 17 | 14 | 5 | 21 | 7 | 49 |
И Т.Д.
Коэффициент ранговой корреляции Спирмана рассчитывается по формуле:
-J(n3 -n)-Z,dj-T-U
9 У[-|(л3 - п) - 2Т] [-|(л32U] ’
где п = 34 — число фонем, а Т и U определяются как
Распределение частот встречаемости фонем по единичным позициям в исконных турецких словах
Т = ^-2(f3 - t) 17 = +2(«3 - и),
Таблица 2
| \^Позиция Фонемк^^. | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| і | 31 | 39 | 9 | 51 | 27 | 7 | 10 | 2 | 4 | 1 | 1 |
| 1 | 2 | 35 | 14 | 42 | 26 | 16 | 18 | 8 | 4 | 1 | 1 |
| и | 6 | 21 | 3 | 16 | 11 | 4 | 5 | 1 | — | 1 | — |
| и | 9 | 36 | 10 | 31 | 21 | 3 | 4 | 4 | — | — | — |
| е | 21 | 104 | 9 | 55 | 27 | 5 | 10 | 3 | 1 | — | — |
| а | 47 | 149 | 20 | 84 | 54 | 12 | 20 | 5 | — | — | — |
| 6 | 8 | 17 | — | — | 2 | — | — | 1 | — | — | — |
| о і: | 11 | 38 | 1 | 1 | 1 | " |

Таблица З
Распределение частот встречаемости фонем по единичным позициям в неологизмах
| ^^ДІОЗИЦИЯ ФонемЗґ^. | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| і | 21 | 27 | 3 | 29 | 15 | 11 | 12 | 5 | 2 | — | — |
| 1 | 2 | 18 | 10 | 34 | 12 | 17 | 9 | 2 | 2 | 1 | — |
| u | 4 | 19 | 4 | 15 | 1 | 3 | 1 | 1 | — | — | — |
| u | 6 | 20 | 7 | 19 | 10 | 2 | 5 | — | — | — | — |
| e | 15 | 50 | 11 | 59 | 22 | 18 | 10 | 2 | 1 | 1 | — |
| a | 37 | 75 | 17 | 54 | 35 | 10 | 16 | 2 | 4 | — | — |
| o | 8 | 19 | — | 1 | 1 | 1 | — | — | — | — | — |
| 0 0 • | 10 | 24 | — | 1 | 1 | ||||||
| 1* u: | |||||||||||
| e: | |||||||||||
| a: | — | 2 | — | — | — | — | — | — | — | — | — |
| m | 2 | 2 | 8 | 12 | 22 | 11 | 8 | 3 | 2 | — | — |
| P | 2 | — | 9 | 2 | 1 | — | — | — | — | — | — |

Таблица 4
Распределение частот встречаемости фонем по единичным позициям в заимствованиях
| \^Позиция Фонемк^. | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| і | 38 | 44 | 11 | 69 | 51 | 17 | 11 | 10 | 3 | — | 1 | — | — |
| 1 | 3 | 26 | 5 | 14 | 6 | 5 | 1 | — | 1 | — | — | — | — |
| ti | 4 | 40 | 1 | 6 | 5 | 9 | 2 | ||||||
| u | 8 | 42 | 6 | 24 | 8 | 3 | 2 | — | — | — | — | — | — |
| е | 20 | 116 | 13 | 65 | 78 | 45 | 23 | 9 | 6 | 2 | — | 1 | — |
| а | 60 | 164 | 43 | 103 | 48 | 39 | 26 | 3 | 4 | — | — | — | — |
| о | 3 | 5 | — | 1 | — | — | 1 | 2 | 1 | — | — | — | — |
| о | 10 | 34 | 12 | 17 | 12 | 11 | 5 | 2 | 1 | 2 | 1 | — | — |
| і: | — | 1 | — | 5 | 5 | 4 | 3 | 1 | |||||
| и: | — | — | — | 5 | 3 | ||||||||
| е: | |||||||||||||
| а: | 8 | 18 | 5 | 15 | 8 | 6 | 5 | ||||||
| m | 56 | 6 | 32 | 24 | 27 | 8 | 7 | 2 | 1 | — | — | — | — |
| Р | 19 | 3 | 12 | 15 | 14 | 7 | 2 | — | — | 1 | 1 | — | — |
| b | 37 | 7 | 19 | 16 | 10 | 4 | 2 | 1 | |||||
| f | 15 | 13 | 19 | 11 | 13 | 6 | 1 | 4 | 1 | — | — | — | — |
| V | 10 | 3 | 18 | 7 | 5 | 2 |
| \^Позиция ФоНЄМ£Ґ\. | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| п | 11 | 14 | 49 | 11 | 28 | 27 | 17 | 10 | 3 | 1 | — | 1 | — |
| t | 60 | 10 | 62 | 42 | 23 | 35 | 35 | 7 | 2 | 1 | 2 | — | 1 |
| d | 35 | 19 | 23 | 21 | 10 | 4 | — | 1 | — | — | — | — | — |
| s | 50 | 16 | 40 | 16 | 32 | 16 | 4 | 5 | 1 | 2 | — | — | — |
| z | 12 | 6 | 20 | 5 | 4 | 3 | 1 | — | — | 1 | — | — | — |
| k | 77 | 10 | 40 | 28 | 14 | 15 | 10 | 4 | 2 | — | — | — | — |
| g | 17 | 2 | 7 | 5 | 3 | — | 1 | 1 | |||||
| Я | 10 | 1 | 1 | 2 | 2 | 3 | 2 | 1 | — | — | — | 1 | — |
| с | 13 | 4 | 8 | 4 | 5 | 2 | 1 | 1 | |||||
| § | 14 | 4 | 12 | 5 | 6 | 2 | 1 | — | 1 | — | — | — | — |
| j | 1 | — | 1 | 2 | 4 | 1 | 1 | 1 | |||||
| r | 11 | 20 | 80 | 28 | 37 | 26 | 9 | 13 | 3 | — | 1 , | — | — |
| 1 | 8 | 19 | 48 | 29 | 25 | 24 | 7 | 1 | 1 | 1 | — | — | — |
| h | 34 | 6 | 28 | 6 | 14 | 5 | 2 | 1 | |||||
| й | — | 1 | 3 | — | 1 | ||||||||
| У | 15 | 5 | 34 | 11 | 13 | 10 | 4 | 5 | 1 | 1 | — | — | — |
| > | — | — | 3 | — | 1 | — | — | — | — | — | — | — | — |
где t и u — число значений одного ранга. Коэффициент корреляции распределения фонем по первой и второй позициям исконных турецких слов составляет 0,327.
Для проверки на достоверность было использовано приближение с распределением Стьюдента, где величина
t = P\+=+
подчиняется распределению Стьюдента с 32 степенями свободы (f = п — 2 = 32) в случае справедливости исходной гипотезы. Согласно исходной гипотезе, исследуемые позиционные распределения фонем независимы друг от друга. В нашем примере t = 1,957, чем можно пренебречь при Р = 0,05. Оснований отвергать исходную гипотезу нет (ср. Brichacek, Hampejsova 1961, с. 234—237).
Подобным образом попарно сопоставлялись все позиции. Поскольку статистические данные, приведенные в таблицах 2 — 4, достаточны не для всех позиций, к дальнейшему анализу привлекались только первые семь позиций каждой из трех групп лексических единиц. Результаты анализа приводятся в таблицах 5 — 7.
Коэффициенты корреляции Спирмана, полученные для распределения частот фонем по позициям в исконных турецких словах.
В скобках даются результаты проверки на достоверность
| 1 | 1 | 2 | 3 | 4 | 5 | 6 |
| 2 | 0,327 | |||||
| (1,957) | ||||||
| 3 | 0,485 | 0,384 | ||||
| (2,749) | (2,354) | |||||
| 4 | 0,537 | 0,645 | 0,561 | |||
| (3,602) | (4,774) | (3,834) | ||||
| 5 | 0,372 | 0,778 | 0,641 | 0,797 | ||
| (2,266) | (7,011) | (4,725) | (7,462) | |||
| 6 | 0,496 | 0,581 | 0,767 | 0,830 | 0,842 | |
| (3,231) | (4,040) | (6,759) | (8,419) | (8,829) | ||
| 7 | 0,383 | 0,674 | 0,473 | 0,865 | 0,768 | 0,785 |
| (2,346) | (5,159) | (3,038) | (9,747) | (6,852) | (7,166) |
За исключением коэффициентов, полученных для первой и второй позиций исконно турецких слов, все коэффициенты корреляции значимы при Р = 0,05. Это видно из приведенных в скобках после каждого коэффициента показателей проверки на достоверность.
Таблица 6
Коэффициенты корреляции Спирмана, полученные для распределения частот фонем по позициям в неологизмах.
В скобках даются результаты проверки на достоверность
| 1 | 1 | 2 | 3 | 4 | 5 | 6 |
| 2 | 0,498 | |||||
| (3,251) | ||||||
| 3 | 0,356 | 0,407 | ||||
| (2,155) | (2,521) | |||||
| 4 | 0,549 | 0,705 | 0,628 | |||
| (3,715) | (5,623) | (4,564) | ||||
| 5 | 0,444 | 0,611 | 0,668 | 0,717 | ||
| (2,803) | (4,372) | (5,077) | (5,818) |
| 1 | 1 | 2 | 3 | 4 | 5 | 6 |
| 6 | 0,425 | 0,636 | 0,609 | 0,816 | 0,803 | |
| (2,657) | (4,660) | (4,344) | (7,987) | (7,624) | ||
| 7 | 0,394 | 0,628 | 0,527 | 0,797 | 0,873 | 0,809 |
| (2,425) | (4,564) | (3,508) | (7,462) | (10,122) | (7,780) |
Таблица 7
Коэффициенты корреляции Спирмана, полученные для распределения частот фонем по позициям в заимствованиях.
В скобках даются результаты проверки на достоверность
| ІГ | 1 | 2 | 3 | 4 | 5 | 6 |
| 2 | 0,429 (2,687) | |||||
| 3 | 0,732 (6,079) | 0,480 (3,094) | ||||
| 4 | 0,667 (5,065) | 0,810 (7,812) | 0,684 (5,305) | |||
| 5 | 0,715 | 0,709 | 0,790 | 0,882 | ||
| (5,784) | (5,689) | (7,288) | (10,589) | |||
| 6 | 0,589 | 0,756 | 0,732 | 0,844 | 0,914 | |
| (4,123) | (6,537) | (6,079) | (8,896) | (12,728) | ||
| 7 | 0,550 | 0,625 | 0,585 | 0,768 | 0,816 | 0,896 |
| (3,724) | (4,530) | (4,079) | (6,785) | (7,987) | (11,419) |
Данные таблицы 5 показывают, что в каждом столбце самым низким оказывается первый коэффициент, три последующие коэффициента идут по нарастающей, а затем показатели начинают уменьшаться. В заимствованиях (табл. 7) рост коэффициентов наблюдается только для двух соседних позиций в слове. В неологизмах (табл. 6) подобных закономерностей роста и уменьшения показателей установить не удается. Контраст между первой и второй позициями здесь существенно меньше, чем в исконных турецких словах и в заимствованиях.
Следовательно, мера позиционного контраста — это переменная, зависящая от позиции фонемы в слове. Для получения общей картины позиционного контраста были подсчитаны средние величины коэффициентов корреляции, выбранных из каждой строки таблиц 5 — 7. Эти средние величины приведены в таблице 8,
Таблица 8
Средние величины коэффициентов корреляции Спирмана, подсчитанные построчно по таблицам 5, 6 и 7
| ^^^^Позиция Группа | 2 | 3 | 4 | 5 | 6 | 7 |
| Исконные слова Неологизмы Заимствования | 0,363 0,498 0,429 | 0,435 0,382 0,601 | 0,581 0,627 0,720 | 0,647 0,610 0,799 | 0,703 0,658 0,767 | 0,658 0,671 0,707 |
Возникает вопрос, существенны ли различия между тремя группами лексических единиц с точки зрения частот встречаемости фонем по позициям и коэффициентов корреляции, полученных для разных позиций. Иначе говоря, можно ли считать, что позиционный контраст во всех трех группах слов турецкого словаря одинаков? Величины, представленные в таблице 8, сравнивались на однородность методом х*квадрата (ср., например, Weber 1961, с. 390—393). Отличие группы неологизмов от исконно турецких слов, с одной стороны, и от заимствований — с другой, совершенно очевидно. Следовательно, неологизмы выделяются как особая группа, отличная от двух других. При Р = 0,05 различие показателей, полученных для исконно турецких слов и для неологизмов, также оказывается значимым. Следовательно, проверка на однородность позволяет заключить, что позиционный контраст будет различным во всех трех группах слов.
Лингвистическая интерпретация результатов очевидна. Прежде всего отметим, что подобный анализ можно проводить для отдельных групп фонем, например отдельно для гласных и для согласных и т.п. Мы попытались показать, что, хотя нередко лингвистические соображения, относящиеся к некоторому уровню языковой структуры, проецируются на следующий и предшествующий уровни, единицы каждого уровня образуют свою, особую структуру, реализующуюся затем на разных уровнях. Так, для фонетического уровня можно говорить метафорически о синтаксисе фонем.
Наше исследование подтверждает известную специфику фонологической структуры начала турецкого слова. Количественное распределение фонем по позициям в слове реализуется не скачкообразно, а равномерно. В этом смысле турецкий язык существенно отличается от других, что подтверждается особым поведением заимствований в нашем анализе. В начале заимствованных слов позиционный контраст не столь велик, хотя, конечно, фонетический облик заимствований претерпевает изменения в процессе языковой ассимиляции.
Еще по теме Краткие гласные в турецком языке образуют законченные, стройные систем:
- § 19. Ударные гласные в русском языке.
- Падение редуцированных и беглые гласные в современном русском литературном языке
- § 50. Как образуются слова в русском языке.
- §17.Семантические основы категории кратких имен прилагательных в современном языке
- § 17. Семантические основы категории кратких имен прилагательных в современном языке
- §17.Семантические основы категории кратких имен прилагательных в современном языке
- § 2. Краткие сведения из истории науки о русском языке.
- §31. Система ударных гласных фонем.
- Система частей речи в русском языке: самостоятельные, служебные. Особые части речи в русском языке.
- § 11. Грамматическая роль фонем л и о. Полная система первичных гласных
- ВТОРАЯ ЧАСТЬ ПРИЛОЖЕНИЯ, содержащая МЕТАФИЗИЧЕСКИЕ МЫСЛИ, где кратко объясняется главным образом то, что излагается в специальной части метафизики о боге, его атрибутах и человеческой душе
- § 49. Система ударных и безударных оттенков русских гласных.
- Таким образом, базовая система R/3
- 61. Классификация и краткая характеристика основных избирательных систем
- §2. канун, танзимат и модернизм (турецкий опыт)
- Автоматизированные информационные системы распознавания образов и речи
- 14. Принципы разграничения частей речи в русском языке. Система частей речи в современном русском языке
- Урок турецкой и испанской империй
- Аспектологи о состоянии системы видовых корреляций в современном русском языке.