Система идентификации референта и модель ослабления дескрипции
В этом разделе дается описание компонента ослабления дескрипции в контексте системы идентификации референта. Рассматривается, каким образом компонент ослабления использует разные виды знаний о дескрипциях и о реальном мире в процессе ослабления неудачной дескрипции и замены ее на такую, референт которой может быть найден.
3.1.1 Обнаружение референта с помощью стандартного механизма референции
Идентификация референта означает обнаружение в реальном мире такого объекта, который соответствует дескрипции, данной говорящим (при этом объект должен обладать всеми признаками, содержащимися в дескрипции, но дескрипция не обязательно должна содержать все признаки объекта). Такой процесс традиционно моделировался в прежних работах. Наш механизм референции прежде всего определяет, необходимо ли начинать поиск в базе знаний, отражающей внешний мир и обычно имеющей таксономическую организацию. Например, в системе, связанной со сборкой водяного насоса, компонент референции не будет осуществлять поиск референта (если на это не будет специальной команды) в том случае, когда в систему поступила группа существительного с неопределенным артиклем (что обычно указывает на новый или предполагаемый объект) или в том случае, когда дескрипция сформулирована очень туманно (а значит, неоднозначно). В ходе принятия такого рода решений могут быть использованы некоторые прагматические аспекты дискурса. Например, использование дейктического элемента в определенных группах существительного, как этот X или тот последний X указывает на то, что объект либо упоминался ранее, либо уже был найден как референт какой-то другой дескрипции, а значит, его легче найти. В эти вопросы мы углубляться не будем.
База знаний содержит лингвистические описания и описание самого обозреваемого поля зрения слушающего. Для представления знаний используется язык KL-One (см. Brachman, 1977), удобный для описания таксономической информации.
KL-One состоит из понятий (CONCEPTS), их ролей (ROLEs) и связей между ними. CONCEPT представляет в системе множество элементов, которые может описывать это понятие. Связь SuperC („= = >“) между ними указывает на отношение включения одного множества в другое. Рассмотрим пример, представленный на рис. 4. Связь SuperC, направленная от понятия В к понятию А, означает включение множества В во множество А (В^А). „Индивидуальное понятие" (INDIVIDUAL CONCEPT) означает, что это множество представлено единичным элементом. Индивидуальное понятие D на рис. 4. характеризуется как уникальный элемент множества, задаваемого понятием С. Роли обозначают то же, что в других языках обозначено атрибутами или слотами, а именно: функциональные отношения между данным понятием и другими понятиями, причем эти отношения задают ограничения на заполнение конкретного слота его значениями.После того как принято решение начать поиск в базе знаний, включается программа поиска референта. Она использует для этого классификатор системы KL-One (Lipkis, 1982). Условия поиска определяются механизмом фокусирования, основанным на методе Б. Грош (Grosz, 1977). Классификатор должен обнаружить все отношения подчинения между новой, только что полученной дескрипцией и всеми другими понятиями, входящими в состав заданной таксономии.
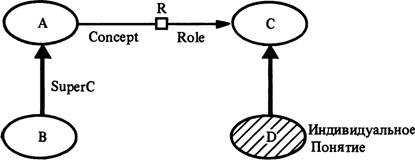
Рис. 4. Пример отражения таксономии в языке представления знаний KL-One.
Иначе говоря, в результате такого поиска входная дескрипция подчиняет себе дескрипции всех возможных референтов. Если при этом входной дескрипции будет соответствовать более одного референта, то она считается неоднозначной. Если входная дескрипция подчиняет себе только одно понятие из базы знаний, то оно и будет считаться искомым референтом. И, наконец, если в классификации объектов не найдется ни одного подходящего понятия, то программа включает в работу механизм ослабления. До того, как предпринять ослабление дескрипции, наша система FWIM проверяет, является ли данный сбой результатом прагматической ошибки неудачного формулирования самой дескрипции.
Далее в статье мы рассмотрим только тот случай, когда система не может найти референта.3.1.2 Подсчет «голосов» за и против ослабления описания
Если программе не удается найти референта, то приходится определять, почему это произошло: из-за дескрипции (т. е. собственно неудачи референции) или в силу внешних обстоятельств. Путаница, вызванная внешними обстоятельствами, могла произойти, например, при различиях в восприятии разговора говорящим и слушающим, из-за неправильного употребления определения, из-за ошибочно выполненного действия и пр. Правила прагматики определяют, следует ли в каждом конкретном случае производить ослабление дескрипции. Так, например, система проверяет, не была ли вызвана неудача в поиске референта явлениями фокуса, метонимии и синекдохи13. Эти правила не рассматриваются в данной статье, в связи с чем мы перейдем к тому случаю, когда трудности вызваны неудачной дескрипцией.
3.1.3 Ослабление дескрипции
В том случае, когда необходимо ослабить дескрипцию, система должна выполнить следующие действия:
— найти потенциальных кандидатов в референты;
— определить, какие признаки во входной дескрипции следует ослабить и в каком порядке это делать; затем, в соответствии с избранным порядком ослабления признаков упорядочить и предполагаемые референты;
— выбрать подходящий способ ослабления и применить его к входной дескрипции.
Поиск потенциальных референтов
Прежде чем производить ослабление дескрипции, алгоритм выбирает потенциальных кандидатов в референты из числа элементов, находящихся в поле зрения говорящего. Делается это так: алгоритм „пробегает" по той части структурированной базы знаний, которая выделилась с помощью механизма фокусирования и оказалась наиболее близкой к дескрипции, данной говорящим. При этом просмотре базы знаний происходит движение вверх и вниз по связям SUPERC, обозначающим иерархию понятий, и проверка каждого кандидата. Механизм выявления частичного совпадения, представленный в системе KL-One, определяет степень близости дескрипции кандидата к входной дескрипции и приписывает ей числовое значение (перед этим вычисляются показатели близости на уровне признаков, что помогает расположить признаки в определенной последовательности и определить степень их совпадения с признаками входной дескрипции).
Информация о соотношении кандидатов основывается только на знаниях, отраженных в языке KL-One; при этом учитываются отношения включения между значениями признаков или их равенство. Никакая информация о предметной области не принимается во внимание. Наиболее подходящие дескрипции из базы знаний (найденные в процессе упорядочения с применением некоторого критерия отсечения) считаются потенциальными кандидатами в референты. Последующее упорядочение признаков и кандидатов в референты для целей ослабления дескрипции производится уже с учетом предметной области.Упорядочение признаков и потенциальных референтов для применения механизма
ослабления
На этом этапе система референции исследует входную дескрипцию и кандидатов в референты, определяет, какие признаки ослаблять и в каком порядке, и устанавливает общую последовательность ослабления признаков 14. Эта последовательность очень важна, поскольку если производить ослабление одновременно по разным критериям, но без единого порядка, то можно в результате получить несколько разных референтов.
Последовательность признаков используется системой для того, чтобы определить, в каком порядке к отобранным на предыдущем этапе кандидатам будут применяться правила ослабления.
Процесс преодоления неудачи референции опирается на знания о языке, о прагматике, о дискурсе, о предметной области, о перцептивных признаках, об иерархической структуре понятий, о предыдущих пробах и ошибках. Подробнее об этом рассказывалось в разделе 3. Эти виды знаний помогают установить порядок признаков для применения механизма ослабления. Информация каждого типа записана в программе в виде некоторого множества правил ослабления. Большинство правил подсказаны подмеченными в протоколах трудностями в диалоге. Написаны они на языке, близком к Прологу. На рис. 5. дано одно из правил, использующих знания о языке.
Рис. 5. Пример правила ослабления дескрипции на основе знаний о языке.
Содержания правил, использующих знания о языке: ослаблять признаки во входной дескрипции в следующем порядке: 1) прилагательные, 2) предложные сочетания, 3) относительные придаточные предложения и именную часть составного сказуемого.
Пример правила:
Ослабить-Признак-Перед (v 1, v2)
-«-Дескрипция Объекта (d)
Дескриптор Признака (v 1)
Дескриптор Признака (v 2)
Признак В Дескрипции (i/l, d)
Признак В Дескрипции (v 2, d),
Равно (синтаксич-форма (v 1, d) „ПРИЛАГ")
Равно (синтаксич-форма (v2, d) „ОТНОСИТ-ПРИДАТ")
Это правило появилось вследствие того, что, как было замечено, говорящий почти всегда располагает особо важную часть информации в конце дескрипции (там, где она отделена от основной части и поэтому выделяется в произношении). Правило на рис. 5 просто отражает тот факт, что относительное придаточное предложение располагается в конце группы существительного, а прилагательные — всегда стоят до него, поэтому те признаки, которые выражены прилагательными, должны быть ослаблены в первую очередь, а признаки, представленные придаточными предложениями,— во вторую. Но в более общей и более удобной форме это правило звучит следующим образом: информация, помещенная в конце дескрипции, обычно более значима (иначе говоря, она больше в фокусе говорящего) .
Рис. 6. Два правила ослабления дескрипции на основе знаний о дискурсе.
Правила ослабления дескрипции, связанные с перемещением фокуса внимания:
Пометить-Возможное-Смешение (и)
Высказывание (и). Фальстарт (и)
Пометить-Возможное-Смешение (d)
Объект-Дескр. (d), Самокоррекция (d),
где
Фальстарт (и): Этот предикат устанавливает, имел ли место в некотором высказывании „ы“ фальстарт. Наличие фальстартов должно улавливаться анализатором.
Самокоррекция (d): Этот предикат ищет в дескрипции ,,d“ самокоррекцию. Как и в случае фальстарта, задача ее обнаружения во входном сообщении возлагается на анализатор.
На рис 6. приводятся два правила ослабления дескрипции на основе знаний о дискурсе. Правила отмечают возможную неожиданную смену фокуса. Они имитируют деятельность слушающего по обнаружению возможного смешения фокусов внимания со стороны говорящего в ходе идентификации референта в том случае, если говорящий сам прерывает свое высказывание 15.
Прерывание может быть двух типов — „фальстарт" и „самокоррекция". При фальстарте говорящий начинает описывать объект, затем вдруг резко останавливается, давая эмоциональную оценку своей речи, и начинает описание заново (см. также работу Р о 1 а п у і, 1978, о „фальстартах") . Такие восклицания, как, например,,,Фу-ты!", „Нет-нет, не то!", „А, не так" и тому подобные сигналы фальстарта, дают понять слушающему, что возникло какое-то затруднение, хотя и не указывают, где именно. Источник затруднения может корениться в текущем высказывании или в каком-то из предыдущих. Говорящий очень часто (ошибочно) думает, что слушающему ясно, что он имеет в виду.Слушающий, в свою очередь, обычно считает, что затруднение вызвано текущим высказыванием. Тем не менее, слушающему следует запомнить, в каком месте диалога произошел фальстарт, чтобы вернуться к нему и осмыслить услышанное по-новому, если потребуется. Самокоррекция не так резко перебивает дискурс, как фальстарт, и яснее указывает на источник неудачи. Она представляет собой изменение части высказывания, которое вносится сразу же, по ходу произнесения самого высказывания. Весьма типичны, скажем, такие описания с самокоррекцией: она — трубка то есть или большая синяя — э — фиолетовая трубка. Так же, как и фальстарты, эти места в описании чреваты ошибками, поэтому слушающий должен уметь их выделять.
Каждый вид знаний диктует свою частичную упорядоченность признаков при их ослаблении . В каждом частично упорядоченном множестве элементы сортируются топологически, что позволяет сравнивать такие множества между собой в едином формате. Затем все частично упорядоченные множества рассматриваются вместе. Предположим, например, что из перцептивных знаний следует, что мы должны ослабить признак цвета. Однако если цветовой признак содержится в относительном придаточном предложении, то знания о языке снизят ранг цветового признака, то есть поставят его ближе к концу в списке характеристик, предназначенных для ослабления.
Поскольку разные виды знаний дают, как правило, разное частичное упорядочение признаков, то эти различия могут привести к конфликту. Для разрешения этого и подобных конфликтов предназначен алгоритм выбора наилучшего кандидата. Его целью является такое упорядочение кандидатов в референты Сі, С2, ... , Сп, чтобы ослабление прежде всего применялось к наилучшему кандидату, затем к наилучшему из оставшихся и т. д. Наилучшим являются те кандидаты, которые лучше всего соответствуют предложенным упорядочениям признаков. Сначала алгоритмом исследуются все кандидаты в референты и упорядоченные множества признаков по каждому виду знаний. Для каждого кандидата С / (на основе упорядочения признаков по одному из видов знаний) алгоритм вычисляет степень изменения первоначальной дескрипции D в том случае, если она будет ослаблена до такого варианта, который будет явно иметь своим референтом С/. Механизм вычисления (этой степени изменения дескрипции) ориентирован на минимизацию количества ослабляемых признаков при попытке ослаблять признаки в строго заданном порядке и в то же время на ослабление прежде всего тех признаков, которые ближе к началу в списке характеристик, рекомендуемых для ослабления 17.
Такой эвристический метод позволяет очень просто отражать в получаемом числовом показателе, насколько конкретный кандидат соответствует данному упорядочению признаков. Отметим, что такой способ вычисления может выбрать кандидата Сі, при том, что для него требуется ослабить больше признаков в D, чем для кандидата Сг, но зато его признаки следуют в списке характеристик, рекомендуе-
Дескрипция, / ’’Закругленная бордовая деталь,
данная говорящим \ большая такая”
Цвет: Бордовый Форма: Круглая Функция: Деталь Размер: Большой
D
Входное представление дескрипции
Цвет: Красный Форма: Цилиндр Состав: Пластик
Цвет: Оранжевый Форма: Круглая Функция: Труба
Цвет: Красный Форма: Брусок Функция: Подставка
С„
С2
Cl
Объекты-кандидаты
(Языковые знания)
Цвет < Форма < Функция < Размер (Перцептивные знания)
Цвет или Форма < Функция < Размер
Частичное упорядочение признаков для их ослабления с использованием правил, основанных на различных источниках знаний
Цвет < Форма или Функция или Размер [ерархические знания)
Переупорядочение
объектов-кандидатов
Цвет: Красный Форма: Цилиндр Состав: Пластик
Цвет: Оранжевый Форма: Круглая Функция: Труба
Цвет: Красный Форма: Брусок Функция: Подставка
С2 С, Сп
Рис.. 7. Переупорядочение кандидатов в референты.
мых для ослабления, раньше, чем признаки С2. Алгоритм проводит вычисление показателя для С/ по каждому виду знаний и суммирует их, получая общий показатель. Затем все С/ упорядочиваются в соответствии с полученными общими показателями (начиная с наименьших значений).
На рис. 7 показана работа алгоритма выбора наилучшего кандидата. В верхней части рисунка помещена дескрипция, данная говорящим. Далее представлено множество указанных в ней признаков и приписанных им значений (то есть пары типа „Цвет: бордовый") . В качестве потенциальных кандидатов в референты выступают объекты реального мира, выделенные механизмом выбора объектов на основе частичного совпадения. Они обозначены в следующем ряду (Сі, С2, ... , СЛ). В прямоугольниках даны множества признаков и их значений, описывающих объект.
Далее алгоритмом генерируются частично упорядоченные множества признаков, предлагающие порядок их ослабления в исходной дескрипции, по одному множеству для каждого вида знаний (перцептивных, лингвистических, иерархических). Знания о языке, например, предлагают такой порядок ослабления: сначала цвет или форма, затем функции, затем размер. Наконец, кандидаты в референты переупорядочиваются в соответствии с информацией, выраженной в исходной дескрипции и с частично упорядоченными множествами признаков.
Выбор методов ослабления дескрипции
После того как было сформировано упорядоченное множество кандидатов в референты, механизм ослабления переходит к третьему шагу: он пробует найти подходящие методы ослабления признаков, для которых только что было получено несколько вариантов упорядочения (успешное обнаружение таких методов оправдывает ослабление исходной дескрипции до требований какого-то конкретного кандидата в референты). Алгоритм ищет методы ослабления до тех пор, пока один из кандидатов в списке потенциальных референтов не совпадет с ослабленным описанием. На этом этапе снова используются знания разных видов.
Ослаблению могут быть подвергнуты многие аспекты дескрипции, предложенной говорящим, среди них — сложные отношения, указанные в дескрипции индивидуальные особенности референта, направленность фокуса внимания, который очерчивает область поиска референта в реальном мире. Под сложными отношениями мы имеем в виду пространственные отношения (например, отверстие возле верхнего края трубки), сравнения (трубка побольше), отношения превосходства (самая большая трубка). Все они могут подвергаться ослаблению так же, как и более простые признаки объекта (размер, цвет), упомянутые в дескрипции.
Существуют три стратегии ослабления дескрипции, каждая из них применима к любой части дескрипции. Эти стратегии таковы:
(1) Отбросить ошибочное значение признака.
(2) Расширить или сузить значение признака, выбирая новое значение как можно ближе к старому (то есть осуществляется просмотр иерархии подчиненности признаков).
(3) Попытаться применить значение какого-то другого признака, исходя из каких-то внешних соображений (например, знания о том, что люди часто оговариваются, путая слова, связанные отношением противоположности, типа отверстие и штырь, как это было в отрывке 7).
Выбирая стратегию ослабления, сначала пробуют применить наименее крутые меры. Стратегия (1) является самой радикальной,
(2) — наименее радикальной, а (3) занимает промежуточное положение.
Очень часто объекты, находящиеся в фокусе, неявно вносят в него другие, связанные с ними объекты (Grosz, 1977; Webber, 1978). Поэтому части объекта, находящиеся в фокусе, вполне могут быть кандидатами в референты, и их стоит проверить. Иногда говорящий может отнести признак отдельной части ко всему объекту (так, например, плунжер, который состоит из красной ручки, металлического стержня, синей головки и зеленой манжеты, может быть назван зеленым плунжером). В этих случаях механизм ослабления строит новую дескрипцию, опираясь на отношение „часть — целое".
Три вышеприведенных стратегии ослабления реализованы в программе набором иерархически организованных процедур, которые мы называем методами ослабления. Каждая процедура рассчитана на ослабление определенного типа признаков и сама выбирает необходимые виды знаний для своей работы. Так, например, процедура генерации сходных значений признаков разделяется на несколько процедур: генерации сходных значений формы, генерации сходных значений цвета и генерации сходных значений размера.
Каждая такая специализированная процедура делает, по существу, одно и то же: сначала пытается ослабить значение признака до такого, которое было бы наиболее близко к исходному или как-то связано с ним (например, при ослаблении признака цвета красный мы предпочтем сначала попробовать свести его к розовому, а уже затем — к синему). Если это не удается, то ослабляемый признак заменяется на другие, более далекие 18. Такая замена, по существу, ничем не лучше простого отбрасывания признака. (...) [28]
Цель компьютерной реализации разработанного нами механизма референции и преодоления коммуникативных неудач состояла в том, чтобы продемонстрировать имитацию работы такого модуля в составе системы общения с ЭВМ на естественном языке. Мы, правда, не использовали какой-либо конкретный семантико-синтак- сический анализатор, а просто считали, что на вход нашего компонента подается такое представление реплик, которое мог бы давать упомянутый анализатор. А именно, в качестве входного материала у нас служило представление на языке KL-One той семантической интерпретации, которая строилась для некоторой дескрипции какого- то объекта из предметной области, связанной со сборкой водяного насоса.
Мы построили также на языке KL-One сеть из 250 понятий, в которой отражены многие детали водяного насоса и их физические и функциональные признаки. Работа механизма фокусирования имитировалась программой (под управлением меню), которая выделяла различные фрагменты в сетевом представлении реального мира, имитируя тем самым перемещение фокусных областей для поиска потенциальных референтов. Мы построили также программу оценки частичного совпадения дескрипций и программу с целью поиска возможных кандидатов в референты. Наконец, нами запрограммирован ряд правил ослабления дескрипции и проверена принципиальная пригодность предложенного механизма.
4.
Еще по теме Система идентификации референта и модель ослабления дескрипции:
- Исследование алгоритмов идентификации с применением FSpice- моделей R-C-NR ЯЭФП
- 4.2. Статистическая обработка экспериментальных данных, идентификация моделей
- Идентификация действующей системы управленческого учета
- 11.4.1 Идентифицирующие дескрипции
- Когнитивная трехкластерная система идентификации параметров порядка The three cluster cognitive system of order parameter_identification
- Программа идентификации R-C-NR ЯЭФП и исследование алгоритмов идентификации на основе опытных образцов ЯЭФП
- «Дескрипция»
- Блок-схема математической модели двухтопливной комбинированной системы питания двигателя автомобиля для расчета расхода топлив представлена на рисунке 2.3. Она была разработана на основе моделей /50, 66, 86,90/.
- Блок-схсма математической модели двухтопливной комбинированной системы питания двигателя автомобиля для расчета расхода топлив представлена на рисунке 2.3. Она была разработана на основе моделей /50, 66, 86,90/.
- Характер и система XII таблиц: две наиболее близкие модели этой системы
- Знания, необходимые для исправления дескрипций
- Модель системы
- 2.2.6 Примитивные значения и теория дескрипций
- Ослабление синтаксической связи
- Ослабление синтаксической связи