Заключение
В этой главе были описаны междисциплинарные подходы, а также основные положения нашей модели. Она очерчивает макроструктуру всей книги, а именно различные компоненты стратегического подхода к переработке дискурса.
Однако в ней подчеркивается, что в настоящее время модель не в состоянии обеспечивать анализ поверхностной структуры и давать полное представление знаний. Кроме того, в ней указаны различные способы, с помощью которых модель может и должна быть расширена в будущем: это и роль мнений, оценок и отношений; характер и роль стилистических, риторических, конверсационных и коммуникативных стратегий; в целом же предусматривается включение данной модели в более общую модель стратегической вербальной коммуникации в социальном контексте. С другой стороны, мы указывали на то, что у такой социальной модели должна быть в то же время когнитивная основа, которая обеспечивается репрезентацией социальных контекстов, ситуаций, участников коммуникации и интерактивных процессов. И действительно, стратегии семантической интерпретации дискурса могут быть включены в дальнейшие теоретические разработки понимания, планирования и участия в процессе коммуникации. Если в настоящее время существует некоторый разрыв между лингвистической теорией языка и дискурса и теорией социальной коммуникации, то наша когнитивная модель обеспечивает между этими двумя теориями потенциальную связь. Поскольку мы переводим абстрактные текстуальные структуры в более конкретные, интерактивные и когнитивные процессы стратегического характера и одновременно проделываем то же самое с абстрактными структурами коммуникации и социальных ситуаций, то тем самым мы получаем возможность комплексного объединения этих элементов в модели дискурсивной коммуникации. Разумеется, выполнение этой программы является нетривиальной задачей, важнейшей целью будущих исследований в области междисциплинарной когнитивной науки.Глава 10. КОГНИТИВНАЯ МОДЕЛЬ
В предыдущих главах мы довольно подробно рассмотрели различные процессы, связанные с пониманием связного текста. Теперь посмотрим, как это все происходит в реальном времени. Напомним, каким в самом деле сложным является „это все". Невероятным представляется то, как много задач люди могут решать одновременно, за сколькими вещами им приходится следить, сколько ограничений соблюдать в процессе понимания связного текста—и, как правило, без особых усилий, автоматически:
— Воспринимаемый поток звуков должен быть интерпретирован в терминах фонем, последовательности фонем—в терминах морфем, а структурированные последовательности морфем— в терминах предложений. Максимум в течение нескольких секунд этим структурам должно быть приписано значение, и при максимальном темпе произношения приписывание значения лексическим единицам должно осуществляться в интервале от 0,1 до 0,2 сек.
— Одновременно с этим части предложений должны быть объединены в предложения, должны быть выявлены отношения, обеспечивающие связность данных предложений, в целях определения топика, или темы, данного фрагмента должны быть установлены его глобальные макроструктуры.
— Интерпретация текста зависит от общих или эпизодических знаний о мире, которые должны быть найдены, выборочно активированы и приведены в действие. Для установления локальной и глобальной связности необходимы умозаключения, основанные на знаниях.
— И в то же время слушатель должен учитывать многообразные данные коммуникативного контекста, в том числе относящиеся к типичной социальной ситуации, говорящему, типам взаимодействия, условиям речевого акта. Интерпретация этих данных опять-таки основывается на памяти (например, на эпизодической памяти о говорящем).
— Эти различные уровни интерпретации не являются независимыми, они должны быть связаны друг с другом. Поверхностные сигналы могут быть релевантными не только для стандартной лексической или синтаксической интерпретации, но и для выражения макроструктур, типов речевых актов и различных свойств коммуникативного взаимодействия.
Это характерно и для других отношений между синтаксисом, семантикой и прагматикой.— Помимо этого, слушающий должен учитывать различные типы информации, необходимой для управления процессом интерпретации, включая фрейм коммуникативного взаимодействия (например: „это урок", „это суд"), речевой макроакт, семантическую макроструктуру, схематические суперструктуры и некоторые другие параметры, относящиеся, например, к стилистике и риторике.
— При осуществлении этих процессов должно быть активировано не только знание, но и мнения, установки, ценностные ориентации и эмоции, необходимые, например, для оценки содержания или коммуникативного намерения связного текста.
— Наконец, одновременно со всем этим слушатель должен учитывать свои собственные желания, интересы, цели и планы, которые оказывают воздействие на все другие компоненты процесса понимания.
Так или иначе, описывая этот процесс с научной точки зрения, мы достигли того, что процесс понимания, казавшийся интуитивно простым и элегантным, теперь представляется весьма сложным. Однако, как мы показали в предыдущих главах, все эти факторы действительно влияют на понимание и связаны с ним определенным образом. За кажущейся простотой понимания связного текста скрывается очень многое. Вместе с тем, как показывает анализ, понимание дискурса по своей сложности необязательно превосходит другие виды человеческой деятельности, не связанные с употреблением языка. Так, например, если столь же детально проанализировать такое действие, как передвижение человека в толпе (например, студента, идущего на лекцию), то уровень сложности описания будет ненамного меньше. Таким образом, простые, на первый взгляд, типы поведения требуют сложных описаний и теорий.
Задачей когнитивной теории является конструирование системы, в рамках которой могут быть представлены и скоординированы (без нарушения известных ограничений на информационные способности человека) все процессы, происходящие при понимании связного текста.
К наиболее важным ограничениям, которые здесь нас интересуют, относятся ограничения на запоминание и обработку информации (processing constraints). Перцептивные ограничения известны лучше и здесь не рассматриваются. Ограничения на обработку информации, проявляющиеся при понимании дискурса, исследуются с недавнего времени и пока еще плохо изучены (см. одну из первых работ на эту тему: Britton, Meyer, Hodge & Glinn, 1980, а также Эксперимент 3, разд. 6.6). В принципе когнитивные процессы, как нам представляется, могут осуществляться параллельно и при определенных обстоятельствах, не препятствуя друг другу (обзор соответствующей литературы см в: Kintsch, 1977а, Ch. 3). Однако возможности параллельной обработки ограничены пределами ресурсов и данных возможностей. Пределы данных возможностей очевидны, когда индивидуум не в состоянии чего-то сделать даже в благоприятных обстоятельствах (например, человек не способен прыгнуть на 100 м или решить сложную физическую проблему без соответствующей базы знаний). Пределы ресурсов имеют место, когда что-то можно сделать в принципе, но не в реальной ситуации (например, испытуемые в одном из проведенных нами экспериментов могли строить макроструктуры, но для некоторых трудных текстов они оказались не в состоянии это сделать после первого прочтения, поскольку были слишком перегружены выполнением других задач, необходимых для понимания текста. Ограничения на ресурсы могут быть обойдены с помощью автоматизации поведения. Так, стратегия понимания, которую нужно использовать сознательно и которая требует особых усилий, имеет ограниченное применение, поскольку во многих реальных ситуациях для применения такой стратегии в наличии имеются лишь ограниченные ресурсы. С другой стороны, хорошо отработанные, полностью автоматизированные стратегии могут работать параллельно, не перегружая систему.
Ограничения на обработку информации, несомненно, окажутся в ближайшие годы в центре внимания исследований по дискурсу. Хотя и нельзя сказать, что в своем весьма поверхностном обсуждении данной проблемы мы уделили ей должное внимание, однако больше мы к ней возвращаться не будем.
Вместо этого обратимся к проблеме ограничения на запоминание.Ограничения на запоминание бывают двух типов. Во-первых, хорошо известны ограничения кратковременной памяти. По данным некоторых экспериментов (Broadbent, 1975), возможности кратковременной памяти ограничены примерно четырьмя „порциями" информации (chunks) или примерно двумя единицами в экспериментах по свободному припоминанию, где для поддержания кратковременной памяти могут использоваться меньшие ресурсы (Glanzer & Razel, 1974). Мандлер считает, что сознание ограничивается одной- единственной идеей (Man die г, in press). Понятно, что в кратковременной памяти нет места для всей информации, которую необходимо обрабатывать и поддерживать в процессе понимания текста, как бы мы ее ни членили. Ясно также, что большая часть происходящих процессов при понимании текста не осознается, и поэтому нет причин для отнесения их к кратковременной памяти. Какова все же роль кратковременной памяти в понимании?
Второй тип ограничений памяти, интересующий нас здесь, связан с ограничениями поисковых возможностей. Чтобы найти в памяти какой-либо элемент, поисковый стимул, или ключ (сие), должен, по крайней мере, частично совпадать с закодированной единицей. Стимул, или ключ, должен подходить к коду. Эффективность памяти определяется не кодированием или поиском, а взаимодействием кодирования и поиска. Это и есть принцип специфического кодирования Тулвинга—Томсона (см. Tulving & Thomson, 1973).
Принятая нами точка зрения относительно кодирования очень проста. Память — это побочный продукт обработки информации; каждый запоминает то, что он делает. Важное значение имеет глубина и детализация обработки: более глубокие и детализированные процессы обработки информации оставляют в памяти больше следов, которые позднее могут быть восстановлены. Множественное кодирование оставляет следы, с которыми может совпасть большее число поисковых стимулов. Таким образом, от характера кодирования в значительной степени зависит, насколько хорошо запомнится то или иное событие: детализированное, семантически осмысленное кодирование событий и хранение их в развитых и легкодоступных структурах обеспечивает высокую степень запоминания.
Решающую роль при этом играет образность. Далее мы покажем, что понимание связного текста совершенно естественно порождает благоприятные условия для кодирования информации в памяти.Поисковый стимул эффективен, если частично совпадает с закодированным в памяти эпизодом. Затем этот эпизод может быть найден и восстановлен в кратковременной, активной памяти. Однако эффективность поиска обычно не просто зависит от эффективности изолированного стимула, но от его действенности в поисковой системе. В такой системе поисковый сигнал не только приводит к восстановлению в памяти нужной информации; одновременно с этим порождается другой сигнал, позволяющий найти расширенную информацию. Поэтому хранящиеся в памяти эпизоды, интегрируемые в такую систему, обнаруживаются гораздо легче, чем неорганизованные, изолированные следы памяти. Ниже мы постараемся показать, что понимание связного текста по самой своей природе ведет к созданию высокоинтегрированных поисковых систем и, тем самым, к высокоорганизованной памяти, в особенности если сравнить соответствующие процессы с запоминанием неорганизованных списков слов в классических исследованиях памяти.
Однако прежде чем перейти к рассмотрению этих проблем, мы вынуждены внести в нашу картину понимания связного текста еще одно усложнение, весьма существенное для исследования памяти. Дело в том, что с точки зрения процессов, происходящих в памяти, целью понимания дискурса является не просто его запоминание, а, скорее, запоминание того, что в нем содержится, то есть того, о чем говорится в связном тексте. Этот очевидный факт имеет далеко идущие последствия, которые необходимо рассмотреть, прежде чем мы сможем продвинуться далее в исследовании динамики запоминания связного текста.
10.1. От репрезентации текста к модели ситуации
Если мы обратимся к моделям обработки связного текста, то заметим, что в большинстве случаев носитель языка постепенно конструирует представление текста в эпизодической памяти. В принципе репрезентация текста включает в себя не только поверхностную— семантическую и прагматическую — информацию, но и схематические суперструктуры. Кроме того, считается, что репрезентация текста имеет иерархическую природу, включающую микроструктуры, организованные посредством линейных связей в терминальные категории.
В предыдущих главах мы указывали на ограничения, характерные для данной концепции. В достаточно общем виде проблема состоит в том, что в репрезентацию текста включаются не только элементы текста, но и элементы знания. Сколько таких элементов входит в состав репрезентации текста? Другими словами, является ли она содержательно богатой и разветвленной структурой, как подсказывает нам интуиция и эксперименты, или же в основном ограничивается представлением самого текста? Где нужно провести границу? В настоящей книге мы последовательно проводим точку зрения, в соответствии с которой репрезентация текста является относительно однородной и не очень сложной; мы полагаем, что в нее необходимо включить только те умозаключения, которые необходимы для установления когерентности на локальном или глобальном уровнях. Другие исследователи выдвигали гипотезы о более обогащенных репрезентациях, включающих в себя дискурс и его контекст, а также внутреннее знание, привлекаемое в процессе интерпретации. Грессер продемонстрировал, например, как тексты в процессе понимания могут обогащаться выводами и следствиями (Graesser, 1981). Мы же считаем, что эти усложнения, за исключением тех, которые текстуально необходимы, являются не частью собственно текстовой репрезентации, а скорее входят в состав конструируемой слушателем или читателем ситуации, модели, обозначенной в тексте. Именно эта модель собирает и поставляет всю релевантную информацию для адекватного понимания текста...
Различие между репрезентацией ситуации и текста не является абсолютно новым. В нашей работе (van Dijk, 1977а) это различие разрабатывалось с помощью таких понятий, как „факты", „возможные миры" и „модели дискурса". Аналогичные понятия использовались и другими исследователями; ср. „дневники референции" Кларка я Маршалла (1978), „референты дискурса" Картунена (1976), „дискурсивные сущности" Нэш-Веббер (1978а), „сети референции" Хабе- ля (1982), „теорию текста—мира" Петефи (1980), „репрезентации дискурса" Кампа (1981) и „ментальные модели" Джонсона-Лэрда (1980). Различаясь в деталях, все эти понятия мотивированы одним и тем же интуитивным представлением: чтобы понять текст, мы должны представлять себе, о чем он. Если мы не в состоянии представить себе ситуацию, в которой индивидуумы обладают свойствами или отношениями, обозначенными в тексте, то не сможем понять и сам текст. Если мы не понимаем отношений между локальными и глобальными фактами, о которых говорится в тексте, то мы не понимаем и текста.
Сказанное является прямым следствием, вытекающим из наших представлений о роли использования знания в понимании текста. Использование знания в понимании текста означает способность соотносить текст с некоторой имеющейся структурой знания, на основе которой и создается модель ситуации. В процессе этого вспоминаются прошлые ситуации, как конкретно-эпизодические, так и обобщенно-семантические ситуации. (Sc han к, 1979). В большинстве интерпретированных нами текстов описываются объекты, лица, места или факты, уже известные нам из прошлого опыта. Хранящиеся в памяти ситуации входят в состав (пересекающихся) структур (или кластеров), образованных по признаку сходства. Поскольку они имеют эпизодический характер, то, разумеется, они субъективны и различны у каждого человека. Так, у каждого из нас есть субъективные кластеры опыта, связанные с городом, в котором мы живем, с домом, друзьями, местом работы и основными событиями жизни. Точно так же у каждого из нас есть в той или иной мере сходные кластеры опыта, связанные с такими понятиями, как страны, города, исторические события, политические события, известные люди. С другой стороны, в случае деконтекстуализации, опыт становится почти или совершенно общим; ср., например, знание арифметики или правил шахматной игры.
Мы полагаем, что в процессе понимания подобные кластеры отыскиваются и используются в качестве основы для модели новой ситуации. Иногда можно непосредственно использовать имеющуюся модель, иногда же ее нужно сконструировать из нескольких частично пригодных, уже существующих моделей. Выдвигалось предположение (Carbonell, 1982), что рассуждение по аналогии является мощным средством для преобразования имеющихся, но неподходящих моделей в модели, отвечающие требованиям определенной задачи. Так, текст напоминает понимающему о некотором прежнем опыте, а затем этот опыт используется для создания модели данной ситуации. Обычно для этого требуется трансформировать каким-то образом старую структуру опыта, и в связи с этим Карбонелл рассматривает различные операторы, которые можно использовать для постепенной трансформации существующей структуры в новую структуру, основанную на анализе „средства—цель". В этом смысле понимание связного текста можно рассматривать как решение определенной задачи.
Сконструированная таким образом модель ситуации представляет собой основу для интерпретации текста. Она охватывает все знание, включая то, которое содержится в тексте имплицитно или же подразумевается. Общее знание используется точно так же, как специфический опыт: и то, и другое образуют основу для моделей ситуаций и, следовательно, для кодирования нового опыта.
10.1.1. Для чего нужна модель ситуации. Теперь рассмотрим ряд специальных лингвистических и психологических понятий, нужных для демонстрации того, что модели ситуации являются не просто правдоподобными, но действительно необходимыми для анализа феноменов понимания дискурса и памяти.
Референция. В философии и лингвистике стало привычным проводить различие между „значением" и „референцией". Мы используем слова или референциальные выражения для обозначения различных объектов — отдельных предметов, свойств, отношений и фактов (истинностных значений) в некотором возможном мире. В психологии различием между значением и референцией обычно пренебрегали. Этот недостаток может быть устранен с помощью модели ситуации. Обозначаемый мир не является когнитивно релевантным: то, что мы видим или представляем,— опять-таки некая конструкция, модель ситуации. Это репрезентация того фрагмента мира, о котором говорится в тексте. Конечно, многое из этого фрагмента остается недоговоренным в тексте, главным образом потому, что слушатель уже многое знает об этом. С другой стороны, главная (семантическая и прагматическая) функция текста состоит в обогащении модели—в получении знания. Все это относится не только к семантической информации в ассертивных контекстах, но и к угрозам, обещаниям и извинениям: эти речевые акты информируют нас о нуждах, желаниях или мнениях говорящего по отношению к нашим действиям.
Это значит, что кроме чисто „семантической" модели ситуации, нам нужна коммуникативная модель контекста, представляющая речевые акты и лежащие в их основе намерения, а также дополнительная информация о говорящем, слушающем и контексте. Мы можем предположить, что именно коммуникативная модель контекста устанавливает связь между моделью ситуации и репрезентацией текста. Репрезентация текста—это, так сказать, семантическое „содержание" коммуникативного акта, референциальной основой которого является модель ситуации. Здесь мы не можем полнее раскрыть точный смысл коммуникативной модели контекста и ее отношений с репрезентацией текста или моделью ситуации.
Кореференция. Выражения в дискурсе относятся не к другим выражениям или лежащим в их основе понятиям текста, а к индивидуумам в модели ситуации. Выражения „мой брат" и „адвокат" могут иметь различные концептуальные значения, но и то и другое может относиться к одному и тому же индивидууму, скажем Джону. Модель ситуации содержит репрезентацию того же индивидуума. Понятие кореференции не будет иметь существенного значения в когнитивной процедурной теории понимания, если у нас нет возможности координировать репрезентацию с моделью ситуации. Джонсон-Лэрд и Гарнэм (1980), Кларк и Маршалл (1978), Карттунен (1976) и Веббер (1978а) углубили разработку этого положения.
Когерентность (связность). В одной из наших предыдущих работ мы подчеркивали, что локальная и глобальная связность основываются на отношениях между пропозициями. Грубо говоря, текстовая база является локально связной, если обозначаемые факты связаны, например, условными, временнь'їми или причинно- следственными отношениями. Опять-таки реальные факты внешнего мира нерелевантны для когнитивной теории, поэтому нам нужна их репрезентация, то есть модель. Если в модели ситуации, построенной слушающим, репрезентируемые факты связаны, тогда данный фрагмент текста является когерентным.
Ситуационные параметры. Такие же аргументы можно привести и в отношении роли, выполняемой в дискурсе параметрами возможного мира, времени и места. Мы уже видели, что в отдельных предложениях текста они часто остаются невыраженными. Иногда эти элементы подразумеваются, выводятся из контекстной информации или только однажды упоминаются в тексте, так что их область действия распространяется на интерпретацию последующих предложений. В репрезентации текста этот вид локализации соответствующих пропозиций объяснить нелегко, а то и невозможно. В модели это было бы очевидно. Модель точно определяется параметрами
обстоятельств; она на самом деле является „моделью ситуации".
Перспектива. В связных текстах могут быть выражены различные и изменяющиеся перспективы, или точки зрения (Black, Turner & Bower 1979). Это означает, что различные люди видят, интерпретируют, описывают и говорят о фактах или ситуациях с различных точек зрения. Однако мы знаем, что описываются одни и те же факты. Это интуитивное представление можно легко объяснить, если у нас имеется устойчивая точка отсчета, а именно— модель ситуации, более или менее независимая от актуального дискурса и его точки зрения.
Перевод. Перевод — это не просто операция по превращению одной поверхностной формы в другую, и даже не превращение одной текстовой репрезентации в другую, но скорее соотнесение текстовых представлений через посредство модели ситуации. Это не так легко заметить, если у двух языков примерно одна и та же база знаний, которая во втором языке столь же имплицитна, что и в первом. Но если дело обстоит по-другому, когда, например, культурный код языка-источника сильно отличается от языка перевода, тогда для перевода требуется эксплицитная модель ситуации, иначе его не удастся сделать осмысленно. Этот момент подчеркивал Хатчинз (Hutchins, 1980), который перевел запись спора о земельных правах жителей островов Тробрианд. Текст кажется совершенно бессмысленным („примитивным", „алогичным") до тех пор, пока мы не соотнесем его с лежащей в основе моделью ситуации— земельным правом и обычаями на Тробриандских островах, которые нам совершенно чужды; но эти права и обычаи известны и обычны для участников спора и имплицитно подразумеваются ими. После такого соотнесения текст становится таким, каков он есть на самом деле: сложным, связным и логичным рассуждением.
Индивидуальные различия в понимании. Хорошо известно, что два человека могут получить одну и ту же информацию, но воспринять ее как два совершенно различных сообщения. Иногда это может сопровождаться построением различающихся репрезентаций текста. Ранее мы обсуждали, как цели и интересы могут привести читателей к построению различных макроструктур одного и того же текста. Возможности искажения микроструктуры текста являются, как правило, меньшими. Однако интерпретационные различия не обязательно должны относиться к уровню репрезентации текста, они скорее появляются на уровне моделей ситуации. Мы слышим одно и то же сообщение, но понимаем его по-разному. Литературные тексты часто не ограничивают жестко модель ситуации, давая читателю большой простор для создания собственной модели. Дебаты о том, что „значит" классический текст, часто ведутся не о самом тексте, а о той модели ситуации, которую нужно построить на его основе.
Уровень описания. В идеальном случае тексты предназначаются для своей аудитории: они предполагают совершенно определенный объем, не утомляющий читателя излишней информацией, но и не лишающий его информации необходимой, то есть той, которая у
читателей отсутствует. Это ведет к большой экономии в коммуникации, при условии общей требуемой базы знаний. Если этого нет, то возникает ситуация, в которой часто оказываются этнографы и дети,—и тогда требуется изменение уровня дискурса: в нем должна быть передана наряду с информацией и необходимая модель ситуации.
Память. В психологической литературе приведено несколько четких демонстраций того, что в определенных условиях люди запоминают модель ситуации, а не репрезентацию текста. Обычно это бывает в условиях, когда очень трудно построить репрезентацию текста, например из-за того, что используется очень много похожих предложений, что приводит к значительной интерференции, поэтому понимающий отвлекается от репрезентации текста и сосредоточивается целиком на модели ситуации, обычно явной и простой (например: Bransford & Franks, 1972; Potts, 1972; Barclay, 1973). Так, легко запомнить, что „ястребы умнее медведей, которые умнее львов, которые умнее, чем волки", но почти невозможно запомнить целую группу сравнительных предложений со всеми аргументами в различных комбинациях. Функция этих предложений состоит единственно в том, чтобы помочь слушателю сконструировать соответствующую модель ситуации, но не текстовую базу (которая в любом случае была бы чрезвычайно обедненной).
Другой способ показать, что запоминается модель ситуации, а не текстовая база, состоит в представлении испытуемым таких пар предложений, которые демонстрируют, что различия в их текстовой базе минимальны (скажем, различие относится только к употреблению предлогов), но зато существуют немалые различия в модели ситуации (один-единственный предлог способен резко изменить описываемые ситуации). В этом случае испытуемые опять-таки смешивают предложения, но не ситуации (Bransford, Barclay & Franks, 1972; Garnham, 1981). И, наоборот, бывают ситуации, когда люди запоминают текст, вообще не имея модели ситуации, например, когда детей учат петь древнееврейские тексты и тексты Корана, а они их не понимают. Однако обычно долговременная память заполняется очень скудно, если отсутствует понимание, или, что то же самое, модель ситуации; это было продемонстрировано, например, хорошо известными работами Брэнсфорда и Джонсона (Bransford & Johnson, 1972). Существуют достаточно серьезные теоретические объяснения того, почему память должна быть теснее связана с моделью ситуации, а не с самой текстовой базой; поиск скорее всего производится в том случае, если эпизод, содержащийся в памяти, входит в более крупную структуру, которая может служить поисковой системой. В силу своей природы модели ситуации стремятся к вхождению в такие системы и образуют часть более крупной модели, тогда как текстовая база более свободно ассоциируется с этими структурами, часто через соответствующую модель. Тогда поиск текстовой базы требует активации модели, но не наоборот. Это, разумеется, верно не во всех случаях, поскольку хотя и возможно отыскать текстовую базу непосредственно по
какому-то одному элементу текста, но это скорее исключение, чем правило. Далее, сама текстовая база, выполнив свою основную функцию в качестве переходной ступени к модели ситуации, редко активируется повторно, тогда как корреспондирующая модель, при условии, если она содержит важную для индивидуума информацию, может подвергаться широкому использованию и обновлению, как мы увидим в дальнейшем. Эта поисковая практика чрезвычайно усиливает поисковые способности модели (Hogan & Kintsch, 1971), в то время как сама текстовая база не обладает такими преимуществами.
Переупорядочивание. Когда людям рассказывают истории, в которых нарушен порядок событий, они часто пересказывают их в канонической форме (см. Kintsch, Mandel & Kozminsky, 1977). Есть два способа объяснить этот феномен, и оба они используют модель ситуации. Во-первых, возможно, что при пересказе люди реконструируют рассказ на основе модели ситуации, сформировавшейся у них при прослушивании рассказа в искаженной форме: и когда у них появляются соответствующие схемы знаний, они получают возможность из искаженной последовательности построить каноническую модель; при пересказе они работают именно с этой моделью, а не с собственно текстовым представлением. Возможен и другой случай, когда, несмотря на искаженный источник, текстовое представление вводится в память в правильной последовательности. Однако единственная возможность произвести такое упорядочение связана с построением модели ситуации в канонической форме, после такого построения ее используют для перестройки текстового представления. В любом случае переупорядочивание искаженного повествования предполагает построение модели ситуации.
Межмодальная интеграция. Часто встречаются случаи, когда необходима интеграция информации из текстовых и нетекстовых источников. Модель ситуации, которую можно модифицировать либо с помощью прямого восприятия и действия, либо через посредство дискурса, образует столь необходимую связь между модальностями.
Решение задач. Модель ситуации играет особенно важную роль, когда на основе чтения текста нужно выполнить какое-либо действие, например, решить задачу. Основой для решения задач является не сама текстовая база непосредственно, а выведенная из нее модель. Техника решения задач, например, математика и логика, применяется к модели, а не прямо к естественному языку. Поэтому логика—неподходящий формализм для языкового представления. Язык просто дает сигналы, указывающие на то, какой тип модели нужно сконструировать, а понимающие интерпретируют эти сигналы стратегически. Модель ситуации, являющаяся результатом интерпретирующего процесса, образует основу для дальнейших когнитивных операций, таких, как формальное логическое рассуждение и другие виды выводов и решения задач. В заключительном разделе этой главы мы опишем случаи, когда модель ситуации образует основу для использования арифметических операций, как это происходит при решении словесных задач в арифметике.
Обновление и соотнесение. Это две наиболее важные функции использования модели ситуации. Репрезентации текста связаны с другими элементами в памяти—общим знанием, а также личным опытом—в значительной степени через соответствующие им модели. Таким образом, они участвуют в сети памяти, которая определяет их дальнейшее использование с помощью моделей, построенных на их основе. Точнее говоря, не всегда бывает так, что каждый текст ведет к построению отдельной и новой модели ситуации. Гораздо чаще уже существующая модель ситуации изменяется под воздействием нового текста. Это происходит, например, при обновлении знаний после сообщения новостей. То, что мы помним о таких широко освещаемых в печати событиях, как, например, Уотергейт, обновляется часто, и так же часто модифицируется модель ситуации, которая интегрирует разнообразный опыт и содержит в себе не только декларативные утверждения, но и мнения, установки, эмоции и даже, возможно, мораль. Несмотря на чрезвычайно важную роль обновления знаний, экспериментальные исследования и теоретические разработки в этой области находятся пока на начальном этапе. Интересная работа по обновлению памяти на основе сообщаемых новостей была проделана Ларсеном (Larsen, 1982) и Финдалом и Хейджером (Findahl and Hoijer, 1981); теоретические аспекты процесса обновления были исследованы с помощью моделирующей программы Колоднером (Kolodner, 1980).
Обучение. Последней по порядку, но не по значимости является использование модели ситуации в качестве основы обучения. Обучение по тексту—это обычно не заучивание текста. Концептуально лучше всего представить себе обучение как модификацию модели ситуации. Вопросы о том, какие модификации заслуживают названия „обучение", как они осуществляются, какие здесь действуют механизмы и ограничения, выходят за рамки настоящей книги. Однако после долгого отставания теория обучения вновь выходит на передний край, уже в рамках когнитивной науки (см., например, Anderson, 1982). Мы можем только надеяться, что представленная здесь теория понимания связного текста обеспечит надежную основу для исследования связи обучения и текста. И с практической, и с теоретической точек зрения, потенциально — это одно из наиболее важных направлений исследований.
10.1.2. Почему также необходимы текстовые базы. Приведенные в предыдущем разделе рассуждения, разъясняющие, почему необходимы ситуационные модели, производят убедительное впечатление. Действительно, они являются таким сильным доводом в пользу ситуационной модели, что возникает искушение радикально упростить модель понимания дискурса, отбросив вообще понятие репрезентации текста. Должны ли мы в самом деле настаивать на многоуровневой пропозициональной текстовой базе? Разве не можем мы просто иметь слова с одной стороны, а модель ситуации—с другой? Какую роль играет репрезентация?
Приведем сначала несколько доводов в пользу того, почему представления поверхностной структуры являются необходимыми компонентами текстовой базы:
1. Тексты не просто выражают значения или соотносятся с фактами, элементами и отношениями, они делают это особым, лингвистическим способом. По ряду причин необходимо запоминать поверхностные структуры. Для грамматических отношений, выходящих за пределы предложения, существенное значение может иметь и точная поверхностная структура предыдущего предложения.
2. Тексты могут различаться по стилю: даже если мы говорим об одних и тех же фактах, способ их описания может быть различным. Эти стилистические особенности получат семантические, прагматические и интерактивные интерпретации: и носители языка как на протяжении текста, так и гораздо позже воспринимают данный стиль и его особенности либо непосредственно, либо с помощью поиска релевантных семантических или интерактивных функций.
3. На каждом из уровней текста могут действовать различные риторические операции. Опять-таки эти операции используются не столько для выражения фактов, сколько в коммуникативных целях, чтобы сделать дискурс более эффективным. И снова у пользователей языка может возникнуть различная реакция на такие риторические средства, как рифма, аллитерация, метафора и т. п.
Однако процессы понимания не могут быть ограничены поверхностными структурами — они требуют привлечения концептуальных процессов, основанных на пропозициональных репрезентациях:
1. Дискурсы иногда имеют особую суперструктурную схему. Будучи либо канонической, либо трансформированной, схема чаще всего не зависит от обозначаемых фактов и связана скорее с глобальным упорядочением макросемантической или макропрагмати- ческой информации.
2. На глобальном уровне происходят также возможные (переупорядочения в представлении пропозиций в соответствии с когнитивными, прагматическими, стилистическими, риторическими или интерактивными ограничениями. Эти переупорядочения не столько зависят от фактов, сколько от способа их представления слушателю.
3. То, что было сказано ранее о перспективе, может быть выражено по-другому следующим образом: если речь идет об одних и тех же фактах, мы можем описывать их с разных точек зрения, чтобы люди получали доступ к описаниям с различной перспективой.
Таким образом, существует двойная необходимость в репрезентации текста. С одной стороны, это необходимая стадия на пути к ситуационной модели. По крайней мере, в излагаемой здесь теории мы просто не можем сконструировать эксплицитную модель ситуации без промежуточной пропозициональной репрезентации текста. Впрочем, вряд ли и другие теории могут обойти эту промежуточную стадию, не введя через черный ход некоторого нотационного варианта. Но, с другой стороны, мы должны отделить репрезентацию текста от ситуационной модели, поскольку представление текста и представление ситуации не всегда совпадают. Представление текста вполне может иметь свое собственное и особое существование в памяти. Точно так же, как обычно скорее вспоминают ситуацию, обозначаемую текстом, чем сам текст, могут и часто на самом деле вспоминают текст per se — его организацию, его макроструктуру, которая может (хотя и не обязательно) иметь какие-то общие свойства со структурой ситуации. Для представителя когнитивной науки решающим является выяснение того, что мы относим к тексту и его производным, специфичным только для него структурам типа пропозициональной текстовой базы, и что мы относим к внешнему миру. Эти две вещи смешивать нельзя.
10.1.3. О репрезентации ситуационных моделей. Мы уже приводили ряд доводов в пользу ситуационных моделей. В то же время эти аргументы обеспечивают критерии для создания адекватной теории ситуационных моделей. Критерии должны допускать формулировку различных явлений и процессов в терминах структуры и использования таких моделей. Здесь мы не можем ставить себе целью создание полной теории эпизодических ситуационных моделей, но, тем не менее, некоторые предположения могут послужить предпосылками для создания такой теории. Мы уже видели, что модель ситуации— это интегральная структура эпизодической информации, вобравшая в себя прошлую эпизодическую информацию о какой-то ситуации и задействованную общую информацию из семантической памяти. Далее, при понимании текста модель ситуации должна обеспечивать обновление и, наконец, формировать основу для обучения. Поскольку предшествующие входные данные, а также обобщенный выход и способ использования информации в различных задачах, как правило, различны по структуре, мы должны предположить, что модель ситуации также имеет схематический характер. Подобно сценариям и фреймам, она должна допускать существование переменных терминальных категорий. Это—приемлемая гипотеза, поскольку она позволяет нам (а) использовать (части) сценариев и фреймов в качестве каркаса ситуационной модели, и наоборот; (б) легко переходить от модели ситуации к более абстрактному деконтекстуализован- ному сценарию или фрейму с помощью процесса обучения. В самом деле, если нам довелось только раз лететь на самолете, у нас еще нет сценария, а есть только одна-единственная ситуационная модель соответствующего эпизода (об эпизодической иллюстрации формирования сценариев у детей см. Schank & Abelson, 1977). Приобретаемый позднее опыт такого рода дополнит, скорректирует основанную на опыте схему и одновременно войдет в нее. Другими словами, модель ситуации отличается от фрейма или сценария тем, что носит гораздо более личностный характер, основана на личном опыте и охватывает многие детали, от которых можно абстрагироваться при обучении. Теперь представим на минуту, что такой эпизодический след прошлой информации связан со сложным событием или эпизодом вроде дорожного происшествия. Или потому, что мы были участниками такого происшествия, или потому, что видели подобное или слышали рассказ о таком событии, у нас формируется представление об этом сложном событии. В соответствии с нашей теорией комплексной обработки информации прошлый опыт, скорее всего, недоступен во всех деталях. Гораздо более вероятно, что прошлое событие будет доступно в результате поиска на макроуровне. Другими словами, модель ситуации формируется— и обновляется—главным образом, предшествующими макропропозициями (на основе восприятия, действия или дискурса) вкупе с некоторыми случайными деталями.
Соблазнительно выдвинуть гипотетическое предположение, что структура ситуационной модели образуется фреймом, подобным пропозициональному фрейму: на вершине его предикат, содержащий информацию „участие в дорожном происшествии", а затем следует список участников, расположенных, например, таким образом, что роль агента может быть заполнена самим действующим лицом „Я", после чего могут следовать другие участники. Затем событие локализуется по месту, времени и условиям. Отметим, что макропропозиция, представляющая прошлую информацию, может быть менее полной и не включать, например, других участников и информацию о других подробностях. Однако в модели ситуации должна быть полная схема, в которой по мере накопления опыта могут заполняться „пустые" категории. Коль скоро мы предположили, что пропозициональная схема в качестве терминальных единиц имеет атомарные пропозиции, то опыт, получаемый об аналогичных событиях (дорожных происшествиях), может накапливаться путем заполнения терминальных категорий соответствующими пропозициями. Конечно, можно представить себе, что эти пропозиции как-то упорядочены. Во-первых, может быть упорядочение по новизне с размещением в каждой категории новейшей информации сверху. Но наряду с этим может быть и упорядочение по релевантности: мы, без сомнения, лучше помним аварию, случившуюся с нами 5 лет назад, чем происшествие, о котором мы читали в газете 5 дней назад (и которое может быть даже понято без обращения к личным воспоминаниям о перенесенной аварии). В любом случае информация о некоторых конечных категориях может в свою очередь стать настолько сложной, что сама будет суммирована в какие-то макропропозиции: мы можем сгруппировать опыт дорожных происшествий в определенный класс и проделать то же самое с аналогичными условиями происшествий. Отметим, что подробности каждой ситуации могут быть легко вписаны в такой фрейм модели: дополнительные характеристики участников могут быть размещены под терминальными категориями участников, и то же самое относится к свойствам самого события и его локализации. Точно так же у нас есть обратные макроправила, позволяющие нам разложить макрособытие на подготовительные или обусловливающие события, составляющие события и последствия.
Этот вид формата ситуационной модели легко отыскивается и хорошо согласуется с другими основными положениями. В процессе понимания текста мы прежде всего стремимся установить некоторую временную (provisional) макропропозицию. Эта макропропозиция станет отличным поисковым стимулом для обнаружения макропропозиции, доминирующей над комплексной ситуационной моделью. И наоборот, множество порций, или „кусков" (chunks), информации, полученных из воспринимаемого текста, четко вписывается в соответствующие релевантные категории ситуационной модели на различных макроуровнях.
Можно предположить также, что недавнее использование модели ситуации или частое обращение к ней дает возможность понимающему обнаруживать сравнительно больше деталей, относящихся к предыдущей ситуации. Кроме того, если модель ситуации используется часто, многие детали и подробности ее терминальных категорий могут не быть—и обычно не бывают—доступными для последующего понимания. В этом случае имеет место обобщение и деконтексту ализация, то есть обучение: для ситуации данного вида мы формируем фрейм или сценарий. Такой общий сценарий или фрейм (или пакет организации памяти—ПОП) легче использовать в дальнейшем с помощью простого обращения к нему, и он может предоставить все релевантные задействованные подробности вместе с новой информацией об актуальной ситуации. В этом случае, возможно, понадобится отыскать в прошлых состояниях ситуационной модели только недавний или очень релевантный прошлый опыт. Так, чтобы иметь возможность поехать в метро в Нью-Йорке, мне достаточно просто сценария, или фрейма „поездка в метро", если таковой имеется, и наличия новой релевантной и специфичной информации о ситуации. Но в то же время я могу—даже если езжу в метро каждый день—вспомнить о вчерашней поездке, во время которой мне встретился какой-то странный человек, или о прошлогодней поездке, когда в метро был пожар. Если же у меня нет ни сценария, ни фрейма, я могу вспомнить только давнюю и нечеткую информацию (то есть макроинформацию) на основе модели, построенной мною несколько лет назад после поездки в метро в Нью- Йорке, или на основе похожих ситуаций (поездка в метро в Париже).
Другой важный момент связан с возможной уникальностью ситуационных моделей. Являются ли они моделями одной уникальной ситуации, о которой мы получаем дополнительную информацию (например, о гражданской войне в Сальвадоре), или модель ситуации— это гибкая схема, допускающая собирание сходных ситуаций? Последнее предположение кажется более вероятным: эпизодическая память—это не просто неорганизованная свалка несметного количества ситуационных моделей; скорее всего, сходный опыт собирается в ней воедино. Хотя это не значит, что у нас нет возможности селективного поиска в памяти какой-то специфичной ситуации: мы можем делать это либо с помощью выборочного поиска деталей из терминальных категорий ситуационной модели, либо при помощи поиска репрезентации текста или других репрезентаций, которые у нас есть об этом специфичном событии. Только обобщенное понятие ситуационных моделей допускает эффективный поиск сходной информации и всевозможные обобщения в процессах обучения. С помощью теории макроструктур можно объяснить стратегические процессы организации и поиска различных событий в рамках одних и тех же макропропозиций.
И все же мы знаем очень мало об условиях, благоприятствующих или препятствующих конструированию ситуационных моделей из текстов. Ранее мы рассматривали некоторые исследования, где выдвигалось предположение о том, что если имеются очень сложные тексты, хотя описываемые ситуации просты, то читатели могут обойтись без репрезентации текста и сосредоточиться на модели. Соответственно можно представить, что простые тексты, описывающие сложные и непонятные ситуации, побуждают к тому, чтобы сосредоточиться на текстовой базе, отвлекаясь от модели.
10.2. Основные характеристики модели переработки
В результате обсуждения ситуационной модели у нас теперь есть все необходимые составные части для построения процессуальной модели, описывающей понимание связного текста. Вряд ли, конечно, стоит полагать, что может существовать только одна процессуальная модель понимания текста. В гл. 1 говорилось о нечеткости и размытости, свойственных термину „понимание". Существует множество видов понимания связных текстов. Поэтому все, что мы можем здесь предпринять, сводится к представлению основных характеристик процессуальной модели или, так сказать, инструкций для построения такой модели в некоторой конкретной и четко определенной ситуации. Модели понимания для специфических, конкретных ситуаций могут и должны быть эксплицитными, полными и проверяемыми. Однако общие характеристики, излагаемые здесь, по необходимости должны оставаться нечеткими и недоопре- деленными, поскольку они должны прилагаться к широкому разнообразию типов поведения, называемому пониманием связного текста. Здесь (и в разделе 10.5) мы опишем эти характеристики и покажем, как они могут быть использованы для разработки определенной модели переработки в конкретной экспериментальной ситуации.
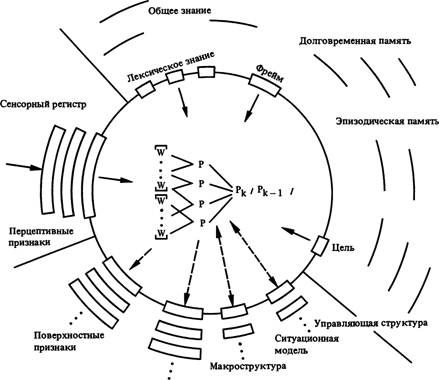
Сейчас мы просто суммируем то, что уже было высказано или подразумевалось в различных частях книги. На рис. 10.1 иллюстрируется сущность предлагаемой процессуальной модели. Она содержит многочисленные уровни репрезентации обработки, участвующие в понимании связного текста и считающиеся важными на всем протяжении книги. На этот раз вопрос состоит в том, как эти многочисленные уровни работают и взаимодействуют в реальном времени. Последовательное течение переработки при понимании изображено на схеме центральным кругом. За пределами круга расположены различные системы памяти, взаимодействующие между собой.
В основном представлены три больших класса этих систем. Во-первых, это сенсорный регистр, хранящий в свернутом виде поступающую перцептивную информацию и делающий ее доступной для центрального процессора. Для наших целей вполне достаточно
Препозиционная
структура
Эпизодическая текстовая память
Рис. 10.1. Схема действия системы памяти в процессе понимания связного текста. Круг изображает рабочую память, содержащую слова и пропозиции; Р* находится в процессе конструирования, тогда как предшествующая пропозиция Pk-i хранится в буферной памяти с ограниченной емкостью.
стандартное описание этого процесса (обзор литературы см. в работе Kintsch, 1977а, chap. 3). Отметим, что в любой момент времени процессору доступны только некоторые перцептивные признаки.
Во-вторых, существует долговременная память понимающего. Для наших целей необязательно проводить четкое различие между общим знанием и личным опытом. Как мы неоднократно подчеркивали, и то и другое может служить релевантным источником знания в процессе понимания. Они различаются только условиями, в которых проводится их поиск, а не способами использования в процессе понимания. Некоторые из этих структур знания предположительно являются активными в любой нужный момент, как, например, лексическое знание, которое требуется по мере обработки слов, или более крупные системы знания, формирующие сценарии или фреймы, которые служат основой порождаемых пропозициональных структур. К долговременной памяти мы отнесли также, до некоторой степени произвольно, цели и задачи понимающего, его желания, интересы и эмоции, то есть активную управляющую структуру.
К третьему компоненту относится конструируемая репрезентация памяти, эпизодическая текстовая память, а также модель ситуации. В эпизодической текстовой памяти выделяется поверхностная память, пропозициональная текстовая база и макроструктура. Другие взаимосвязи, которые могут наличествовать в различных зонах памяти, не представлены в явном виде на рис. 10.1. Конструируемые в памяти репрезентации текста можно вообразить в виде стеков, устроенных по магазинному принципу (push-down stacks), то есть при добавлении новых элементов старые элементы отодвигаются все дальше и глубже. Таким образом, поиск по сигналам новизны осуществим только для нескольких новых элементов в каждом стеке. Однако элементы стека не только упорядочиваются по новизне, они еще и тесно связаны друг с другом (по крайней мере, пропозициональные представления и модель ситуации), а также скоординированы с соответствующими элементами в параллельных структурах. Следовательно, элементы могут быть найдены не просто с помощью сигналов новизны, но и по их взаимосвязям с другими элементами как в одном и том же стеке, так и в параллельных стеках. Поскольку модель ситуации является наиболее взаимосвязанной и интегрированной структурой, ее найти легче всего, в то время как сигналы новизны уже более неэффективны. С другой стороны, поиск в пословной поверхностной памяти возможен только с помощью частичного совпадения, в результате которого оказываются доступными порции информации, содержащиеся в поверхностной памяти. Реальная поисковая система для поверхностной памяти отсутствует. Пропозициональная структура, включающая макроструктуру, это сеть взаимосвязей и отношений, в пределах которой одна пропозиция ведет к другой, образуя в целом эффективную поисковую структуру.
В центре рис. 10.1, окруженный этими системами памяти изображен центральный процессор. В этом устройстве происходят все когнитивные операции. Так, чтобы изменить какой-то элемент в системах памяти, его необходимо перенести в центральный процессор. Единственная операция, которая может быть выполнена с элементами памяти вне процессора,— это поиск.
Центральный процессор имеет центр и периферию. Хотя и не существует ограничений на объем обработки информации, которая может быть выполнена в центральном регистре (за исключением ограничений на ресурсы, о которых упоминалось ранее), есть серьезные ограничения на количество информации, которое может поддерживаться в активном состоянии в рабочем регистре. Хорошо известны ограничения емкости кратковременной памяти. Мы полагаем (и это указано на рис. 10.1), что в общем кратковременная память способна удерживать порцию информации, которая находится в состоянии текущей обработки, и плюс к этому некоторую информацию для установления связи, перенесенную из предшествующей порции. Обрабатываемая порция состоит из сложной пропозиции Р*, содержащей ряд атомарных пропозиций Р. Каждая из атомарных пропозиций выведена из некоторых фрагментов текста, обозначенных на рис. 10.1 буквой W. В общем сложная, или комплексная, пропозиция Р к часто соответствует некоторым фразам или предложениям на языковом уровне. Отсюда следует, что в любой момент
ПРОИСШЕСТВИЕ переворот (Люси, парусная лодка)
~ СРЕДСТВО ПЕРЕДВИЖЕНИЯ парусная лодка
новая
— ЛИЦО Люси
— ВРЕМЯ (X, день) — ветреный
— МЕСТОНАХОЖДЕНИЕ при выходе из ( X, гавань)
\ \ сразу Саусалито
процесса понимания в кратковременной памяти содержатся поверхностные представления одного или двух последних простых предложений и выведенные из них атомарные пропозиции, объединенные на основе некоторой структуры знаний и образующие пропозициональную единицу Р. Кроме того, кратковременная буферная память содержит некоторую остаточную информацию из предшествующей текстовой пропозиции Pfc-i. В общем, это будет не какая-то целостная единица, включающая все свои подчиненные атомарные пропозиции и актуальные языковые формы, из которых они выведены, а „скелетная" версия Р*-і. Если Р основано на структуре знания (на фрейме или сценарии, построенном для этой цели), то эффективная стратегия будет заключаться в том, чтобы дойти только до основных ячеек („слотов") Р/с-1, удаляя несущественную информацию, вроде той, которая приписывается в схеме позициям модификатора.
Нельзя точнее охарактеризовать принципы, управляющие этой буферной памятью в данный момент, поскольку они могут контролироваться стратегически и до некоторой степени изменяться в зависимости от ситуации. Рассмотрим, однако, следующий пример. Предположим, мы поняли предложение On a stormy afternoon, Lucy overturned her new sailboat just outside Sausalito harbor. (‘Ветреным днем Люси перевернулась на своей новой парусной лодке сразу при выходе из гавани Саусалито’) как „происшествие" и пришли к следующей сложной пропозиции (чтобы не отвлекаться от существа дела, используем нестрогую нотацию) (см. схему на стр. 191). Предположим, что буферная память ограничена тремя атомарными пропозициями (это разумное число—в свете некоторых оценок, полученных в предыдущей работе, использующей модель Кинча— ван Дейка; см. Kintsch & van Dijk, 1978). В данном случае в комплексной пропозиции будут сохранены три верхних ячейки, специфицирующие характер происшествия, средство передвижения и лицо участника. Модификаторы будут отброшены, и в данном случае это относится к ячейкам времени и местонахождения. Отброшенными оказываются и поверхностные языковые выражения, из которых была извлечена пропозициональная информация. („Отбросить" здесь означает просто удалить из кратковременной памяти—следы, конечно, останутся в эпизодической текстовой памяти). Таким образом, если будет прочитано следующее предложение She got away with a scare, but the expensive new boat was badly damaged (‘Она сама отделалась испугом, но новая дорогая лодка оказалась серьезно повреждена’), то теперь его можно интерпретировать в терминах пропозиции происшествия, все еще сохраняющегося в кратковременной памяти и устанавливающего связь между этими двумя предложениями. Если для интерпретации воспринимаемого предложения требуется более ранняя информация, то, чтобы найти ее, нужно проделать в эпизодической памяти реактивирующий поиск. Предположим, что в нашем примере речь дальше пойдет не о Люси и ее лодке, а о самом дне происшествия (напомним, что информация о нем не хранится в памяти в активном состоянии): On the same afternoon, three other boats sank in the bay (‘В тот же день в заливе потонули еще три лодки’). В этом случае реактивирующий поиск временной ячейки окажется необходимым. Поскольку поиск нацелен на непосредственно предшествующее предложение, он будет скорее всего успешным и потребует немного ресурсов, в отличие от поиска информации, содержащейся в более ранних предложениях.
Как уже неоднократно отмечалось, обработка текстов не ограничивается контекстом схематической репрезентации предшествующего предложения или фразы—есть множество и других факторов, активно влияющих на обработку. В нашей таблице они размещены на границе между центральным процессором кратковременной памяти и окружающими его системами памяти. Для этих активных элементов используется термин управляющая система. В разные моменты процесса понимания активно используются различные структуры знания. Они не входят в кратковременную память, но могут оказывать на нее влияние. То же самое относится к целям и интересам, управляющим целостным эпизодом понимания, и в наиболее значительной степени—к самой текстовой базе. Только что сконструированная макропропозиция влияет на текущую переработку текста в любой из моментов времени самым непосредственным образом; в кратковременную память она при этом не вводится. Будучи активной структурой знания, она непосредственно участвует в процессе. Точно так же активно участвует в процессе, ограничивает и контролирует его последний по времени компонент ситуационной модели. Конечно, создание новых макропропозиций и новых вариантов ситуационной модели происходит в центральном компоненте, хотя и при участии предшествующей модели или макропропозиции, располагающихся на границе данной системы.
Почему управляющая система помещена нами на границе, а не внутри круга? Главным образом потому, что, по нашим представлениям, центральный процессор обладает некоторыми свойствами и кратковременной памяти, и сознания. Теперь мы знаем, что в процессе обработки текста должно участвовать гораздо большее число элементов, чем может поместиться в ограниченный объем кратковременной памяти. Теоретически это даже может быть аргументом против того, чтобы вообще включать кратковременную память, как она понимается в традиционной литературе, в модель понимания связного текста. Однако это значительно ослабило бы объяснительную силу нашей модели как в прежнем варианте, так и в нынешнем. Кроме того, такой шаг было бы трудно согласовать с данными по использованию кратковременной памяти в понимании текста, о чем говорится в следующем разделе главы. Представляется, что наилучшим решением было избранное нами объединение признаков кратковременной памяти и сознания в традициях Уильяма Джеймса. Сознание, по мнению Мандлера (Mandler, in press), содержит в каждый момент времени только одну идею. При рассмотрении понимания текста представляется вполне разумным отождествлять идею с (комплексной) пропозицией. Правда, обычно признают, что ряд идей может находиться на границе сознания; подобные идеи непосредственно доступны сознанию, но, как правило, не осознаются. Аналогичный случай имеет место со структурами знания при понимании текста: они используются, но обычно это не осознается. То же относится к целям, а также к топику и основным темам самого текста (макроструктуре и модели ситуации): в сознании они отсутствуют, хотя и влияют активно на способ понимания дискурса и в любой момент могут быть помещены в фокус внимания. Обычно мы осознаем только слова и их значения. Поэтому мы предполагаем, что центральный процессор на рис. 10.1 состоит из активного, сознающего, но ограниченного по своей емкости центра и периферийной области, где расположены управляющая система и структуры памяти, воздействующие на процесс обработки информации; при этом они непосредственно не осознаются и не имеют ограничений по емкости. Структуры знания, находящиеся за пределами этой границы, то есть вне активных макропропозиций, фреймов и целей, могут участвовать в переработке текста только при условии успешного поиска.
Пояснения к рис. 10.1 вызывают множество вопросов, но на многие из них нет ответа на общем уровне. Необходимо экспериментальное исследование процессов кратковременной памяти, участвующих в понимании текста в конкретных, четко ограниченных ситуациях, чтобы построить конкретные эксплицитные модели этих процессов. Только в этом случае можно надеяться на какое-то понимание этих бесконечно сложных явлений. Но чтобы строить конкретные модели, необходимо иметь общую концепцию, если мы хотим избежать случайных решений.
Вкратце следует указать на связь между данной моделью обработки текста и предшествующим ее вариантом (Kintsch & van Dijk, 1978). Модель 1978 г. можно считать конкретной подмоделью в рамках новой конструкции. Важно подчеркнуть, что прежняя модель, не отличаясь принципиально от новой, является более простым вариантом, в котором опущено многое из изложенного здесь. Например, здесь подробно объясняется, как конструируются комплексные пропозиции, что остается в кратковременной памяти и почему. Все эти процессы рассмотрены с точки зрения того, как знания используются в понимании текста. В прежней модели мы обошли эти проблемы с помощью некоторых формальных правил и статистических данных. Раньше мы считали, что вся обработка происходит циклами, а сейчас полагаем, что все слова немедленно привлекаются к обработке, хотя и циклы играют свою роль в использовании кратковременной памяти, поскольку комплексные пропозиции образуются обычно в кратковременной памяти на границах предложений и фраз точно так же, как в модели 1978 г. Эта модель может оказаться вполне пригодной для некоторых целей, например в тех случаях, когда не нужно вникать в более мелкие подробности, а ограничиваться более общими проблемами памяти, забывания, обобщения и т. д. Таким образом, создание новой модели не означает отказа от прежней модели, несмотря на всю ее неполноту. [...]
10.4. Поиск в эпизодической текстовой памяти
Кратковременная память обнаруживает в процессах понимания текста примерно те же свойства, которые описаны в традиционной литературе. Конечно, порции дискурса—это не то же самое, что список слогов, не имеющих смысла, но их количество и способы испытываемой ими интерференции сравнимы. Зато использование долговременной памяти при понимании текста сначала представляется совсем по-другому. Запоминание текста происходит гораздо лучше, чем запоминание списков слов или бессмысленных слогов. Если люди могут припомнить не более полудюжины из списка случайных слов, то после прочтения странички связного текста они припоминают в десять раз больше. Такое очевидное различие может навести на мысль, что теория запоминания, основанная на экспериментах по заучиванию, не является адекватной теорией запоминания связного текста. Однако можно привести доводы и в пользу классической теории запоминания (Kintsch, 1982b): она достаточно хорошо объясняет, почему запоминание текста происходит гораздо лучше, чем запоминание отдельных слов. Причина заключается в том понимании способов, с помощью которых порождаются репрезентации текста, являющиеся эффективными поисковыми структурами.
В модель Кинча—ван Дейка (1978) не входит описание процессов поиска в явном виде. Все, что имеет в ней отношение к памяти, основано на широко известной гипотезе: припоминается лучше то, что подвергается более тщательной обработке. Некоторые текстовые пропозиции остаются в кратковременной памяти дольше других, поскольку они отбираются для установления связности—в зависимости от их структурной значимости в текстовой базе. Эти пропозиции вспоминаются лучше пропорционально объему дополнительной обработки. Эта дополнительная обработка опять-таки отражается в возрастающей вероятности припоминания. В этом новая модель не отличается от прежней, за исключением того, что она имеет другую основу для отбора пропозиций в кратковременную буферную память...; она связана с тем, что текст организуют фреймы и схемы, то есть структуры знания. Учитывая эту модификацию, уровень припоминания можно предсказать на основе новой модели точно так же, как и на основе модели 1978 г. и модели 1981 г. (Miller & Kintsch, 1981).
Однако память, конечно,— это не просто воплощение различительной силы кодирования. Доминирующую роль играет поиск, взаимодействующий с процессами кодирования. Модель поиска почти непосредственно зависит от характера самой текстовой базы, а также от наличия и структуры ситуационной модели, которую мы здесь временно не учитываем, хотя то, что говорится о поиске в текстовой базе, равным образом относится и к поиску в ситуационной модели. И действительно, характер текстовой базы диктует, по крайней мере в общих чертах, форму модели. Начиная поиск с любого элемента текста, можно обнаружить другие элементы, связанные непосредственно с ним. Найденные элементы становятся затем исходными точками новых поисковых операций, и после их многократного повторения два элемента в репрезентации текста (макропропозиции, текстовые пропозиции, атомарные пропозиции и даже фразы, если мы хотим изучать вербальную память) могут быть связаны длинной поисковой цепочкой с промежуточными узлами. Если текстовая база когерентна, тогда, независимо от начала поиска, в принципе могут быть найдены все элементы. Но если каждая поисковая операция носит вероятностный характер, то поисковые неудачи накапливаются по мере увеличения числа узлов, которые необходимо пройти в процессе поиска. Каковы на самом деле ограничения в этом сетевом поиске, пока точно неизвестно. Но легко могут быть разработаны и испытаны на эмпирических текстах конкретные подмодели, характеризующиеся определенным набором ограничений.
Приведем две иллюстрации. Во-первых, рассмотрим модель свободного припоминания, целиком построенную по принципу „сверху вниз". Это значит, что поиск всегда начинается с верхнего узла и доходит до более нижних узлов репрезентации текста. Пусть г означает вероятность успеха поисковой операции. Тогда пропозиция Р, связанная с верхним узлом посредством к промежуточных макропропозиций М, расположенных только на одной поисковой цепочке, будет найдена с вероятностью rk. Если целевая пропозиция может быть достигнута также через вторую цепочку, содержащую j промежуточных макропропозиций, то поисковая вероятность будет равна г +rJ — гк+3 при условии независимости цепочек.
рг (поиск Pi)=rt-t-r2S-r3St рг (поиск Р2)=г2sг2tc—г4stc рг (поиск P3)=r2t+r2sc-r4stc
Эту схему можно дополнить различными способами. Предположим, например, что поисковая вероятность равна г для связей между макропропозициями (М—М) и между макропропозициями и текстовыми пропозициями (М—Р), но эти разные поисковые вероятности привлекаются для операции в рамках самой пропозициональной схемы. Например, кажется весьма правдоподобным, что атомарные пропозиции Р, заполняющие ячейки в схеме, отыскиваются с вероятностью s, большей, чем вероятность t поисковых пропозиций, которые не заполняют ячейку, но просто добавляются в схему, например, как модификаторы. Далее, можно создать условия, чтобы связи между пропозициями того же уровня также могли использоваться для поиска, например с некоторой вероятностью с. Так, если рассмотреть фрагмент текстовой базы, изображенный здесь, то можно получить следующие поисковые вероятности для атомарных пропозиций Рі—Р3:
М
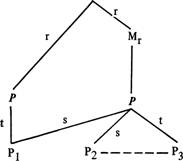
Мы просто следуем по каждой цепочке из верхнего узла до целевой пропозиции, умножая по пути вероятности. Затем вероятности цепочек складываются, а их пересечения при независимости цепочек вычитаются.
Если Р і—Рз найдены успешно и вероятности подсчитаны, тогда их кодирующая сила определяет вероятность их припоминания. Точнее, если пропозиция Р в течение і циклов обработки находится в кратковременной памяти, то вероятность ее припоминания при условии успешного поиска предположительно будет равна р (припоминание//) = 1 - (1 - п)*,
где п есть вероятность успешного кодирования микропропозиции во время одного цикла обработки. Таким образом, формула означает, что припоминание происходит, если имеется по крайней мере один успешный шанс кодирования элемента. Точно так же, если пропозиция Р участвовала в конструировании /=^1 макропропозиций, то сила припоминания будет равна
р (припоминание/У)=1-(1-т)',
где т—это вероятность успешного кодирования макропропозиции в течение одного цикла обработки, р (припоминание/і) и р (припоминание//) взаимодополнительны и независимы. Точно такие же предположения были высказаны в работе Кинча и ван Дейка (Kintsch & van Dijk, 1978). Модель 1978 г. следует рассматривать как ограниченный вариант настоящей модели, где r=s=c = 1. Очевидно, и некоторые другие предположения о поисковых вероятностях могут быть столь же обоснованными. Мы не располагаем необходимыми данными, чтобы решить, какие из этих предположений наиболее адекватны[42]. Если же такие данные будут, то появится возможность сравнить друг с другом различные модели вроде описанной выше.
В качестве второй иллюстрации рассмотрим, как работает в этой модели стимулируемое припоминание. Как и раньше, мы можем построить различные альтернативные модели: связи между интересующими нас элементами определяются текстовой базой, и мы можем установить, как различные типы связей поддерживают поиск. Если, используя снова наш пример, мы знаем, что припомнилась Рг, то можно подсчитать условные вероятности припоминания Pi и Р3 с различным набором предположений. Если в нашем распоряжении окажется соответствующий набор данных, то такой анализ может нам многое рассказать о поисковых процессах в связном тексте.
Однако в основном модель используется не для количественной проверки конкретных гипотез, а для получения качественного объяснения наиболее важных явлений при запоминании дискурса и прежде всего его эффективности. После рассмотрения описанной выше поисковой модели хорошее запоминание текста уже не кажется такой загадкой. В процессе понимания текста происходит образование структур, которые представляют собой весьма эффективные поисковые системы. Материал организуется в порции информации, конструируемые в соответствии с существовавшими прежде единицами памяти, при этом порции тесно взаимосвязаны, что обеспечивается связностью микро- и макроструктур текстовой базы. Благодаря макроструктурам порции информации имеют иерархическую организацию, они связаны с подобными же «порциями» в ситуационной модели.
Это как раз такой тип системы, который, в соответствии с теорией памяти, может быть идеальным для поиска. Он не похож на то, что конструируют испытуемые в лабораторных экспериментах. В традиционных экспериментах по запоминанию списков испытуемые сталкиваются с незнакомой задачей, незнакомым материалом и вынуждены изобретать стратегию кодирования на месте, нередко без соответствующей ситуационной модели. Испытуемые могут опираться только на некоторые общие, но слабые стратегии кодирования, и результат часто бывает далек от оптимального поиска. Когда же испытуемым предлагают простые тексты на какую-то знакомую тему, они оказываются в совершенно другой ситуации. Они могут опираться на богатое фоновое знание и привлекать хорошо освоенные или автоматизированные стратегии понимания. В результате возникает текстовая база, являющаяся одновременно эффективной поисковой системой. Испытуемые являются своего рода экспертами по пониманию: они обладают точными знаниями и необходимыми, хорошо отработанными стратегиями. Подобно экспертам в других областях, их память отражает их квалификацию.
Поэтому текстовую память следует сравнивать с другими видами экспертной памяти, изучавшимися в лабораториях: спецификой памяти опытных телеграфистов (Bryan & Harter, 1899), памятью специалистов по быстрому счету (Muller, 1911; Hunter, 1962), памятью шахматистов (de Groot, 1966; Chase & Simon, 1973), памятью испытуемых, обученных мнемоническим средствам (Bower, 1972; Chase & Ericsson, 1981) и, кроме того, с древним искусством запоминания, которое демонстрировали античные ораторы (Yates, 1966). В свете этих сравнений текстовая память вовсе не выглядит чем-то экстраординарным. Владеющие мнемоникой были экспертами в использовании определенной мнемонической техники, но, столкнувшись с материалом, выходящим за рамки их квалификации, выглядели так же слабо, как и любой другой на их месте. В этом смысле экспертами являются и рядовые читатели: они очень хорошо запоминают простые и знакомые тексты, но память тут же подводит их, если им дается текст, который они не могут вполне понять как следует—либо из-за отсутствия нужной базы знаний (например, при чтении технического текста из незнакомой области), либо потому, что у них не разработаны правильные стратегии (например, при обращении к таким необычным видам дискурса, как поэтические тексты).
Чтобы более подробно проследить параллели между текстовой и экспертной памятью, нужно обратиться к некоторым основным характеристикам экспертной памяти. Они превосходно описаны в работе Чейза и Эрикссона (см. Chase & Ericsson, 1981). Чейз и Эрикссон изучали испытуемого, запоминавшего ряды из 80 и более цифр за одно прослушивание. Запоминание сразу более 80 цифр выглядит загадочным в свете хорошо известных ограничений кратковременной памяти. Ограниченная емкость (span) кратковременной памяти часто считается ее определяющим свойством, и кажется странным, что она может быть так расширена. Однако Чейз и Эрикссон показали, что никакого чудесного расширения не происходит. Емкость кратковременной памяти испытуемого была совершенно нормальной и неизменной. Формируемые им „порции" информации состояли из трех-четырех цифр; кодируемые последовательности не превышали пяти-шести фонем. Таким образом, рабочая емкость памяти испытуемого не отличалась от емкости памяти обычных людей, которые могут запомнить не более семи или девяти единиц.
Описанный эффект вообще не относится к кратковременной памяти, он обязан продуктивному использованию долговременной памяти. Чейз и Эрикссон обнаружили, что это объясняется в основном процессами деления на порции информации и построением эффективной поисковой системы. Трюк состоял в использовании механизма деления на порции информации для связывания следов стимула в иерархическую семантическую структуру. Испытуемый Чейза и Эрикссона придумывал сложный набор стратегий для кодирования последовательностей цифр. С этой целью он использовал хорошо знакомую ему базу знаний: его хобби был бег, и он кодировал цепочки цифр как результаты забегов, которые потом служили ему уникальным поисковым стимулом (сие) для цепочки. Подобно древнеримскому оратору, он размещал запоминаемые числа в имеющейся у него семантической структуре результатов по бегу. Классических ораторов учили запоминать речи, деля их на сцены, которые кодировались как живописные образы и размещались в определенной последовательности (по хорошо известному маршруту). Поиск затем происходил как мысленное движение по маршруту и подбирание по пути соответствующих образов. Такое связывание в поисковую структуру происходит в рабочей памяти и является формой деления информации на порции: богатая, хорошо организованная база знаний результатов по бегу помогает непосредственно распознавать релевантные модели, связывая их с семантическими признаками (например, результат бега на 1 милю, почти мировой рекорд и т. д.). Семантические признаки оказались взаимосвязанными и образовали поисковую структуру, которая вела мнемониста от одного места в памяти к другому.
Существует две необходимых предпосылки для такой поисковой структуры. Во-первых, необходима богатая база знаний типа разветвленной сети результатов бега, имевшейся у испытуемого Чейза и Эрикссона. Во-вторых, все операции по накоплению и поиску должны происходить быстро и без усилий—иначе произойдет переполнение кратковременной памяти. Таким образом, скорость имеет решающее значение. Поэтому прежде чем такие операции станут достаточно автоматизированными, нужна очень большая практика.
Есть несколько поразительных аналогий с текстовой памятью. Текстовая память очень хороша, если ее поддерживает развитая база знаний. Стратегии понимания освоены и заучены до автоматизма. Элементы текста привязаны к основным структурам знания в пропозициональных схемах и используются для деления текста на „порции". Иерархические макроструктуры образуют эффективные поисковые системы. По крайней мере так обстоит дело, когда нужно запомнить простые, знакомые тексты. Если же читаются тексты, для которых нет соответствующей базы знаний, память становится плохой—все это аналогично тому, когда экспертам даются материалы, выходящие за рамки их компетенции. Хорошо запоминаются чаще всего простые повествовательные тексты и гораздо труднее— тексты-описания (Kintsch, Kozminsky, Streby, McKoon & Keenan, 1975; Graesser, Hoffman & Clark, 1980). Память отказывает читателям и в том случае, когда они не могут определить, о чем говорится в данном тексте, поскольку авторы умело это скрывают (Bransford & Johnson, 1982). Так, например, отрывок о стирке белья, написанный таким образом, что читатели не могут определить, о чем в нем говорится, и, следовательно, не могут активировать необходимые знания, запоминается так же плохо, как и список случайных слов (3,6 из 14 единиц содержания текста). Заглавие, из которого читатель узнает, о чем текст, и которое позволяет ему оперировать стратегиями понимания, значительно улучшает запоминание того же отрывка (8 единиц содержания текста). Непонятый абзац плохо запоминается и воспроизводится потому, что без релевантной структуры знания и без соответствующей макропропозиции (выраженной заглавием) нельзя сформировать поисковой схемы. Испытуемые пока еще понимают предложения на локальном уровне и сохраняют в памяти информацию, но хранится она в несвязной форме и поэтому ее невозможно найти (Alba, Alexander, Harker & Carniglia, 1981). Предпосылкой связной репрезентации текста является способность построения связной ситуационной модели. Без этого запоминание текста распадается на куски, в пределах которых поиск проводить так же сложно, как и в списке случайных слов.
Некоторые предварительные экспериментальные результаты, подтверждающие излагаемую здесь интерпретацию текстовой памяти, приведены в работе Кинча (см. Kintsch, 1982b). Если пропозиции используются для деления текста на порции информации, то они должны функционировать аналогично другим единицам памяти. Точнее говоря, эффективность фрагмента текста в качестве поискового стимула должна зависеть от границ порции информации.
Материал легче припоминается, если он содержится в одной и той же порции, а не в различных. Этот классический результат был получен в другой ситуации, где эксперты использовали стратегию деления на порции информации. Например, Чейз и Эрикссон (1981) наблюдали это явление при исследовании того, как их эксперт по памяти использовал порции информации для запоминания цепочек случайных чисел. Они могли довольно точно определить, какого рода порции используются (на основании анализа протокола и других результатов, которые дал эксперимент). Так, они могли выбирать небольшие группы цифр, с тем расчетом, чтобы они не совпадали с границами порции информации. По мере представления одной из этих цифровых групп, испытуемый должен был припомнить цифры, следующие за этой группой в первоначальной цепочке. Это он мог делать очень хорошо, пока стимул и следующие за ним цифры относились к одной и той же порции информации. Но когда стимул воспроизведения приходился на границы порции и оказывалось, что цифры, которые нужно было вспомнить, принадлежали разным порциям, результаты испытуемого значительно ухудшались. Порции информации, определяемые анализом протокола, очевидно, также функционировали и как единицы воспроизведения.
Что касается дискурса, то на основании пропозиционального анализа текста можно предсказать, где проходят границы порций информации. Поэтому, следуя Чейзу и Эрикссону, мы ожидаем, что фрагмент текста, образующий начало порции, является хорошим поисковым стимулом для остальной ее части. Но фрагмент текста, который совпадает с границами порции информации, менее эффективен при поиске последующего текста, находящегося за пределами данной порции.
Пять испытуемых прослушивали отрывки по 250 слов из отчета по психологии. После каждого отрывка повторялась фраза из 6—19 слов из только что прочитанного текста, и испытуемые должны были устно воспроизвести слова, непосредственно следующие за этой фразой в оригинальном тексте. Воспроизведение должно было быть, по возможности, дословным. Если испытуемым это не удавалось, они должны были сказать то, что они запомнили. Для иллюстрации качественной стороны результатов приведем только два примера.
В первом примере стимул воспроизведения заканчивается в середине фразы. Для завершения пропозициональной порции необходимы слова, непосредственно следующие за ним. Так, испытуемые должны были вспомнить следующее:
СТИМУЛ: This discrepancy reflects not only our
‘Это противоречие отражает не только’
ПРОДОЛЖЕНИЕ: society’s concentration of formal educational effort...
‘сосредоточенность нашего общества на формальных усилиях в области образования...’
Ниже приводятся реакции некоторых испытуемых:
РЕАКЦИЯ (a): society’s concentration of effort...
‘сосредоточенность нашего общества на усилиях...’
РЕАКЦИЯ (b): society’s focus on formal education...
‘сосредоточенность нашего общества на формальном образовании...’
РЕАКЦИЯ (с): the shift of concentration of educational research...
‘сдвиг концентрации исследований в области образования...’
Очевидно, что во всех трех случаях реакция испытуемых в той или иной мере дополняет пропозициональную единицу. Кроме того, окончания фраз воспроизводятся практически буквально: в (а) дается буквальное воспроизведение, если не считать двух пропущенных слов; в (Ь) есть пропуски и синонимичная замена; только в (с) не совсем точное завершение фразы, но даже здесь два важных слова воспроизведены дословно. В целом результат можно считать отличным, учитывая, что испытуемые слышали текст только раз, да еще после этого им зачитывался посторонний текст размером в 150 слов. Ясно, что испытуемые не воспроизводили продолжение текста из кратковременной памяти. По-видимому, фраза, использованная как стимул, частично совпадает с порцией памяти на очень раннем уровне анализа, и тем самым эта порция на этом уровне становится доступной и в целом. Таким образом, воспроизводится не только значение, но и словесное выражение дополняемой фразы. Сейчас мы не будем уточнять, вызваны ли пропуски ошибками в кодировании или в поиске.
Рассмотрим теперь стимул воспроизведения, который завершается определенной порцией информации и поэтому вынуждает испытуемого отыскивать следующую порцию. В этом случае задача сводится не только к реинтеграции данной порции информации на основе частичного совпадения, но и к поиску следующей порции в иерархии текстовой базы:
СТИМУЛ: As shown primarily by the work of Schaie
‘Как было впервые показано в работе Шайе’,
ПРОДОЛЖЕНИЕ: a peak of intellectual performance occurs later for current adult cohorts...
‘пик интеллектуальной деятельности у взрослых в данных группах возникает позднее...’
А теперь приведем некоторые реакции:
РЕАКЦИЯ (d): some abilities don’t reach their peak until sometime later.
‘некоторые способности не достигают своего пика вплоть до определенного момента’.
РЕАКЦИЯ (е): a peak occurs much later than previously believed and no decline in intelligence.
‘пик появляется гораздо позднее, чем считали раньше, и никакого упадка интеллекта нет’.
РЕАКЦИЯ (f): (после долгой паузы): Не was finding results that differed from previously held ideas.
‘Он получал результаты, которые отличались от прежних представлений’.
По своему характеру эти реакции отличаются от реакций (а) — (с). Реакции (d) и (е) представляют собой скорее перифразы, чем дословное воспроизведение. Это наводит на мысль, что процесс поиска не происходит прямо в репрезентации текста, а соответствующее продолжение обнаруживается косвенно, через посредство подчиняющей макропропозиции, соединяющей две порции информации, к которым относятся стимул и продолжение. Процесс направлен скорее не на поиск словесной формулировки продолжения, а на использование пропозиционального уровня (в предыдущем же случае сравнение происходило и на языковом, и на пропозициональном уровнях). Для того, чтобы после обнаружения соответствующей макропропозиции достичь языкового уровня, требуется еще один этап поиска, подверженный в свою очередь ошибкам и неудачам.
В случае (f) — перед нами очевидная реконструкция: по-
видимому, испытуемый оказался не в состоянии найти последующую пропозицию и вместо этого произвел частичную реконструкцию, возможно, при помощи макропропозиции, доминирующей над данной порцией текста и имеющей примерно такой смысл: «Прежние исследования демонстрировали X.— В отличие от них Шайе продемонстрировал Y». Реакция (f) необычна: гораздо чаще случается, что если не находится последующая пропозиция, то испытуемые вообще не дают ответа. И в самом деле, примерно в 1/3 случаев не были получены реакции на стимулы, совпадающие с границами порции информации, но совсем не было отказов, если стимул прямо указывал на пропозициональную порцию информации.
Несмотря на предварительный характер этих данных, можно сделать вывод, что стимулированное воспроизведение текста демонстрирует то же деление на порции информации, что и стимулированное воспроизведение цифр специалистом по их запоминанию. Конечно, чтобы окончательно подтвердить это, потребуется гораздо больше данных, но и те, что у нас есть, свидетельствуют: текстовая память,—по крайней мере в идеальных условиях, обеспечивающих адекватное понимание,— по самой своей природе является разновидностью „экспертной" памяти. Не нужно постулировать новых, но еще не исследованных принципов работы памяти для объяснения того факта, что текстовая память гораздо лучше той, которую мы обычно наблюдаем в лабораторных условиях, в экспериментах по заучиванию списков. И в том и другом случае действуют те же самые принципы, однако в процессе понимания дискурса создаются весьма благоприятные условия для запоминания. Хорошо структурированная, многоуровневая, когерентная текстовая база, являющаяся результатом процесса понимания, функционирует как эффективная поисковая система, так что даже чтение или прослушивание текста обеспечивает приемлемый уровень воспроизведения. Правда, это не означает, что невозможно достичь лучшего уровня с помощью специальных процедур кодирования в памяти, описанных, например, в работе Левина (см. Levin, 1982). Конечно, в естественных условиях воспроизведение текста несовершенно, в особенности это относится к деталям, которые нельзя назвать макрорелевантными; для улучшения воспроизведения могут быть использованы различные мнемонические приемы. Например, вполне вероятно, что текстовую память может существенно улучшить использование образности, не влияющее никак на само понимание и построение текстовой базы (за исключением, впрочем, случаев, когда образность может помочь созданию хорошей ситуационной модели). Понимание и воспроизведение связаны только до определенного момента, и улучшение памяти может происходить без воздействия на процесс понимания. [...]
10.6. Эпилог
Завершая книгу, мы хотим кратко охарактеризовать сущность общей теории стратегий понимания. Ее нельзя отнести ни к лингвистике, ни к психологии — это, так сказать, и рыба, и мясо одновременно. С самого начала было ясно, что теория не может охватить все аспекты процесса понимания, хотя в тех границах, которые мы установили для себя, мы попытались достичь полного охвата. Было также ясно, что, несмотря на все усилия, многие положения теории остаются недоработанными. На самом деле, мы представили не столько теорию, сколько ее основания, пытаясь установить принципы ее построения, если дана определенная ситуация понимания. Не может быть такой теории понимания, которая одновременно была бы и общей и частной, потому что нет единого, целостного процесса „понимания". Каждый раз, когда мы пытаемся вникнуть в процесс понимания дискурса, он кажется чуточку иным. Поэтому нужны как раз основы исследования, ряд принципов и методов анализа, которые можно приложить к конкретным случаям. Каждый раз могут получаться несколько иные результаты. Однако, поскольку для построения используются одни и те же блоки, это дает возможность обойтись без произвольных миниатюрных моделей, подгоняемых под данный случай (ad hoc), которые могут быть очень простыми и элегантными, однако по сравнению с реальной сложностью процесса понимания способны лишь вводить в заблуждение.
Ясно, что не только новые ситуации, но и разные теоретические цели требуют новых и отличающихся от прежних моделей. Так, если мы стремимся понять, как используется знание для решения устных (словесных) арифметических задач, то для этого требуется совсем другой уровень анализа, нежели когда нашей целью является предсказание среднего уровня припоминания прочитанного ранее рассказа. Для последнего случая вполне годится вариант нашей модели (см. Kintsch & van Dijk, 1978), который совершенно неадекватен для других целей.
Нечто подобное можно сказать и о принятой системе обозначений, в частности об использованных здесь пропозициональных представлениях. Нет никакой необходимости делать ее сложней, чем нужно. Для грубого членения текста на единицы содержания достаточна довольно поверхностная система обозначений: чем тоньше цели анализа, тем сложнее должна быть данная система. В рамках разработки общей концепции возможно много различных подходов. Не только не нужно, но и нежелательно разрабатывать проблему на всю глубину ее сложности. При наличии общей концепции всегда можно установить, где и когда мы пошли на упрощения, и судить о том, насколько эти упрощения оправданны.
Как оценить адекватность изложенной здесь общей концепции исследования понимания? Хотя, конечно, и возможны сделанные на основе интуиции и анализа литературы самые общие и нестрогие оценки того, что известно о понимании связного текста (а никакие точные оценки—по самой своей природе — невозможны), теория должна быть предельно гибкой и предельно общей. С нашей точки зрения основными критериями ее успеха должна стать наша способность к построению на ее основе эффективных ситуационных и проблемно-специфических моделей, а также возможность экспериментальной проверки различных принципов и импликаций этих моделей. Например, с помощью методов экспериментальной психологии можно получить некоторые эмпирические оценки, хотя и несколько непривычным путем. Сама по себе теория в целом носит слишком общий характер, чтобы ее можно было подвергнуть экспериментальной проверке, но накопление результатов наблюдений и экспериментов в конце концов приведет к ее верификации, или же она будет отвергнута. Описанные здесь эксперименты — не более чем начало. По сравнению с достигнутыми скромными результатами можно и нужно сделать гораздо больше. Мы же в основном располагаем серией демонстраций того, что процессы, развивающиеся в соответствии с теорией, можно действительно наблюдать при соответствующих, тщательно контролируемых лабораторных условиях... Проведение экспериментальных исследований, дополняющих более традиционную функцию эксперимента—функцию проверки теоретических предсказаний,—должно распространиться гораздо шире и сыграть в будущем более важную роль, ибо теории в когнитивной науке становятся все сложнее и все менее доступными для прямой проверки.
Мы видим несколько путей, по которым может развиваться работа в ближайшем будущем. Один из них подразумевался ранее: теперь, когда у нас есть то, что можно назвать приемлемой основой изучения понимания текста, исследование деталей этого процесса сильно упростилось, но для углубления описания необходимо изучить как можно больше этих деталей. Работа будет носить не только теоретический характер, связанный с созданием эксплицитных и конкретных моделей, описывающих четко определенные ситуации; она будет также экспериментальной в том смысле, как об этом говорилось выше. Второе направление связано с выходом за те жесткие рамки, о которых говорилось ранее, и, в частности, с более подробным изучением процессов анализа текста, а также с изучением новой области так называемого „горячего познания" (это мнения, установки и т. п.), которая представляется чрезвычайно интересной. Наконец, третьим направлением будет построение эксплицитного когнитивного перехода к коммуникативному контексту: ситуационному и социокультурному контексту понимания и порождения связного текста.
Еще по теме Заключение:
- + 13. аудиторское заключение: структура, назначение, виды заключений
- 4. Порядок заключения и ведения договора ДМС Подготовка и заключение договора
- 110. Может ли быть удовлетворен иск лица, претендующего на статус субабонента, о заключении договора энергоснабжения в отсутствие согласия на заключение такого договора со стороны энергоснабжающей организации?
- Брак: понятие, условия и порядок его заключения; препятствия к заключению брака; прекращение брака. Недействительность брака
- 187. Предполагает ли заключение договора коммерческого представительства возможность для представителя изменять условия договора, заключенного во исполнение поручения, и исполнять обязанности перед третьим лицом от собственного имени?
- 2.1. Заключение договора
- Заключение договора
- N 3 Заключение эксперта
- Статья 77. Заключение эксперта
- 9.1.4. Заключение