Тестирование и оценка результатов
Задачами множественного регрессионного анализа являются получение надежной оценки параметров для независимых переменных на основе выборки, а также статистических выводов об этих параметрах, как индивидуальных, так и сгруппированных, и
проверка правильности оценочного уравнения регрессии.
Компьютерная распечатка, представленная в табл. 8.2, содержит эти выводы, а также результаты статистических тестов. Однако необходимо принять во внимание, что компьютер работает с данными, представленными лишь в правильном формате.Компьютер только следует процедуре, заданной программой, и он выполнит любой регрессионный анализ, данные для которого представлены в корректной форме, независимо от экономического смысла. Таким образом, задача исследователя заключается в определении правильности применения результатов расчета для прогнозирования спроса. Пригодность модели может быть определена путем ответа на два фундаментальных вопроса: «Имеют ли параметры регрессии правильный знак и разумные значения?» и «Насколько хорошо изменения спроса объясняются изменениями независимых переменных (как по отдельности, так и в совокупности)?».
Ответ на первый вопрос основан на экономической теории и на суждениях исследователя. Для того чтобы ответить на второй вопрос, необходимо провести определенные статистические тесты, оценивающие как отдельные параметры, так и модель в целом.
Шаг 1. Тестирование пригодности модели
Знаки коэффициентов. Каждый коэффициент регрессии (параметр) представляет собой крайнее значение реакции переменной спроса на единичное изменение соответствующей независимой переменной. Знак параметра указывает направление изменения переменной спроса по отношению к изменению независимой переменной. Положительный знак показывает, что переменная спроса изменяется в том же направлении, что и независимая переменная; отрицательный — что эти переменные изменяются в противоположных направлениях.
Исследователь может проверить знак параметра, чтобы определить, показывает ли он теоретически правильное относительное изменение переменных. хч.Возвращаясь к табл. 8.2, мы видим, что увеличение Хх и Х2 ведут к увеличению Q . Отметим, что положительные знаки b и Ь2 согласуются с теорией. Если знак неверен, то это может говорить о том, что мы неправильно построили модель, упустив важную переменную. В некоторых случаях неверный знак сопутствует другим симптомам возникновения статистической проблемы мультиколлинеарности.
Величины параметров. Это проверка параметра на экономический смысл. Хотя и не существует общепринятых пределов, большинство экономистов субъективно ограничивают значения каждого параметра определенными рамками. Иногда параметр может принять такое значение, которое явно невозможно. Например, предположим, что мы смоделировали совокупный спрос (в долларах) как функцию цены и наличного дохода:
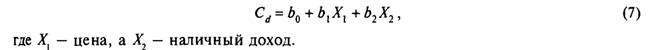
Теперь предположим, что знаки параметров верны, но Ь2 = 1,3. Есть ли в этом какой- либо смысл? Конечно, нет, так как Ь2 представляет собой крайнее значение совокупной склонности потребителя совершить покупку или, что более понятно, дополнительную возможность совершить покупку при возрастании дохода на одну единицу. Следовательно, значение 1,3 явно бессмысленно, так как в соответствии с ним средний потребитель должен потратить 1,3 долл, из каждого дополнительного доллара дохода.
Шаг 2. Статистические тесты и оценки
Данные тестов. Стандартная компьютерная программа для линейной регрессии выдает некоторые статистические данные, с помощью которых можно ответить на следующие вопросы: «Насколько хорошо изменения независимых переменных объясняют изменение зависимой переменной как по отдельности, так и в целом?» и «Имеют ли независимые переменные статистическую значимость?». Иными словами, насколько надежными являются отдельные параметры при прогнозировании значений зависимой переменной?
Для регрессии в целом существуют следующие тесты: множественный коэффициент детерминации, R* [66];
скорректированный множественный коэффициент детерминации, R1; /^-статистика для регрессии;
средняя квадратичная ошибка оценки для регрессии.
Для параметров отдельных переменных существуют тесты на: среднюю квадратичную ошибку коэффициента регрессии; соотношение для t-тестирования для каждого параметра.
Способы интерпретации и использования этих методов проверки будут рассмотрены более детально.
Общие тесты
Множественный коэффициент детерминации, Я2. Как уже было отмечено, множественная регрессия описывает регрессионную плоскость, и наблюденные точки лежат выше, ниже или на этой плоскости. Множественный коэффициент детерминации является мерой того, насколько хорошо плоскость, описываемая регрессионным уравнением, удовлетворяет экспериментальным данным. Как мы показали в предыдущей главе, полная вариация1 переменной спроса может быть разделена на две части:
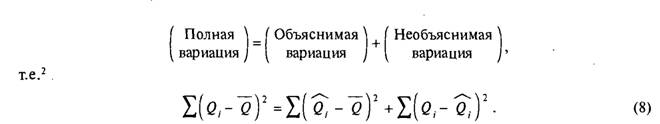
Множественный коэффициент детерминации, В2, определяется как часть общего изменения переменной спроса, относящаяся к изменениям всех вместе взятых независимых переменных из наилучшего выбранного уравнения спроса. Этот коэффициент имеет исключительно математический смысл и не определяет никакой причинно-следственной связи. Множественный коэффициент детерминации вычисляется по следующей формуле:

' Определения вариации и дисперсии в данном случае находятся в соответствии. Вариация - это сумма квадратов отклонений наблюденных значений от линии регрессии. Дисперсия - это арифметическое среднее вариации.
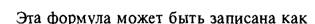
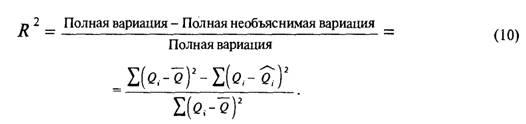
На компьютерной распечатке, представленной в табл. 8.2, под заголовком «Анализ дисперсии» мы видим величину суммы квадратов регрессии, SSR (полная объяснимая вариация), которая равна 53 844,7, в то время как полная сумма квадратов, SST, составляет 53 901,6. Иными словами, значение R[67] [68] (которое напечатано ниже) составляет 53 844,7/53 901,6 = 0,9989.
Это означает, что 99,89% изменений объема продаж объясняется изменениями численности целевого населения и дохода на душу населения, взятыми вместе и подставленными в наилучшее уравнение регрессии.Величина R2 лежит в интервале от нуля до единицы. Нулевое значение говорит о том, что между спросом и всеми другими переменными не существует связи. Значение R2 = 1 показывает, что все изменения спроса объясняются одновременными изменениями независимых переменных1. Для эмпирического анализа нет ничего необычного в том, чтобы получить высокий R1 при статистически незначимых или имеющих бессмысленный знак коэффициентах регрессии. Более того, одним из свойств метода наименьших квадратов для множественной регрессии является то, что при добавлении еще одной независимой переменной может произойти не снижение, а, наоборот, повышение R1 вне зависимости от того, связана ли введенная переменная со спросом или нет. По этой причине может возникнуть желание (с целью достичь более высокого значения R2) ввести как можно больше переменных. Однако с этим желанием надо бороться, так как немного можно сказать о модели, которая включает переменные, не имеющие теоретического обоснования. Мы должны помнить, что нашей целью является разработка надежных оценок истинных групповых параметров, а не получение высокого R1.
Скорректированный множественный коэффициент детерминации, R2. Еще одной характеристикой R2 является его чувствительность к количеству наблюдений, входящих в регрессию. Если количество наблюдений равно количеству независимых переменных, то каждая точка^наблюдений будет лежать точно на регрессионной плоскости и расчетное значение Q будет равно наблюденному значению Q. Тогда R2 = 1, однако это говорит скорее о недостатке информации, чем о благоприятном совпадении. Чтобы получить информативные результаты, мы должны иметь количество наблюдений, достаточное для того, чтобы переменная спроса имела некоторую свободу изменений, т.е. число степеней свободы должно быть больше нуля2.
Гпава 8.
Оценка спроса: множественный регрессионный анализДля того чтобы уделить должное внимание степеням свободы, определяемым количеством наблюдений и количеством параметров._статистики ввели скорректированный множественный коэффициент детерминации, R2. Его формула имеет следующий вид:
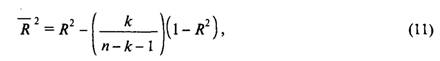
где n — количество наблюдений, а к — количество независимых переменных.
Каковы приемлемые значения для R 2 ? Это, в основном, дело индивидуальных
соображений, и соображения эти меняются в зависимости от исследуемого объекта.
Кросс-секционный анализ, рассматривающий демографические связи, имеет тенден- — 2
цию занижать уровень R по сравнению с методом временных рядов, работающим с ретроспективными связями. Обычно если количество наблюдений по крайней мере в три или четыре раза больше количества независимых переменных, то приемлемым считается R 2 > 0,75.
Чтобы выяснить, объясняет ли регрессионное уравнение статистически значимую часть полной вариации зависимой переменной, рассмотрим /"-тестирование на полную значимость.
F-тестирование на полную значимость. Множественный коэффициент детерминации, R2, и скорректированный множественный коэффициент детерминации, R 2, показывают величину объяснимой вариации. Однако эти коэффициенты ничего не говорят о статистической значимости объяснимой вариации. Чтобы ответить на этот вопрос, мы используем отношение вариаций, известное как /"-статистика. Подобно R 2, F-статистика зависит от числа степеней свободы. Критерий /"-статистики рассчитывается как
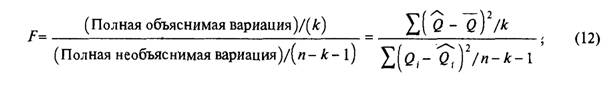
где F - критерий /"-статистики;
к - количество независимых переменных; п - количество наблюдений.
Числитель уравнения (12) представляет собой дисперсию зависимой переменной[69] вследствие вариации независимых переменных. Она рассчитывается как сумма квадратов дисперсии (объяснимая вариация), деленная на число степеней свободы, df Так как для каждой независимой переменной существует только одна возможность изменения, то df= к.
Знаменатель уравнения (12) представляет собой остаточную дисперсию, которая не может быть объяснена вариацией независимых переменных. Она рассчитывается как разность или погрешность суммы квадратов (необъяснимая вариация), деленная на число степеней свободы. В знаменателе вариация зависит от количества наблюдений, п, за вычетом (к + 1) оцененных параметров, /0, / Ьк. Следовательно, df= п - к — 1.
Так как /"-параметр близко связан с коэффициентом детерминации, R2, он может быть рассчитан как1

F-тест на полную значимость основан на том, что для статистической значимости регрессионного уравнения по крайней мере один из истинных параметров регрессии должен быть равен нулю. Расчетное значение /■'-критерия используется для проверки нулевой гипотезы2 о том, что все истинные регрессионные параметры равны нулю.
Если эта гипотеза верна, то не существует действительной связи между зависимой и независимой переменными. В экстремальном случае как R2, так и /■'-критерий должны быть равными нулю, но в любом случае они очень малы. По мере возрастания /■'-крите- рия в какой-то точке он становится достаточно большим, чтобы можно было с достаточной степенью уверенности отвергнуть нулевую гипотезу. Это значение /■'-критерия устанавливает верхний предел значений F, которые возможны в случае выполнения нулевой гипотезы. Это значение известно как критическое значение /■'-распределения.
Таблицы для критических значений /■'-распределения строятся для четырех уровней статистической значимости. Табл. Gв Приложении, расположенном в конце книги, представляет собой матрицу критических значений Fс уровнем значимости 0,05 и 0,01, что соответствует уровням доверия 95 и 99% соответственно. Чтобы воспользоваться таблицей, необходимо знать число степеней свободы, к, в числителе и число степеней свободы, п - к— 1, в знаменателе уравнения (12) или уравнения (13). Для каждой комбинации кип - к - 1 записано критическое значение критерия F. Например, как следует из таблицы, для уровня значимости 0,05 критическое значение F для 3 степеней свободы в числителе и 15 степеней свободы в знаменателе составляет 3,29. Это означает, что если

нулевая гипотеза выполняется, то вероятность превышения F= 3,29 составляет 0,05, или 5%. Иначе говоря, если расчетное значение Fпревышает 3,29, то мы на 95% можем быть уверены, что коэффициенты регрессии не равны нулю. Если мы хотим быть уверены в этом на 99%, то мы должны найти критическое значение Fдля уровня значимости 0,01. Это значение составляет 5,42 для того же числа степеней свободы.
На распечатке в табл. 8.2 представлено расчетное значение /^ (строка «Анализ дисперсии»). В данном примере на распечатке содержится информация о регрессии двух независимых переменных, базирующаяся на 15 наблюдениях. Следовательно, числитель имеет 2 степени свободы, а знаменатель имеет 15-2-1 = 12 степеней свободы. Таким образом, расчетное значение /■'-критерия составляет
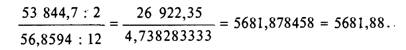
Это значит, что объяснимая (факторная) дисперсия в 5681,88 раз больше, чем необъяснимая (остаточная).
Согласно табл. G для 2 степеней свободы в числителе и 12 степеней свободы в знаменателе при уровне значимости 0,01 критическое значение /■'составляет 6,93. Иными словами, если нулевая гипотеза (о том, что все параметры регрессии равны нулю) выполняется, то критическое значение F= 6,93 может быть превышено только один раз из ста попыток. Так как расчетное значение Fсоставляет 5681,88, мы отвергаем нулевую гипотезу и делаем вывод, что регрессия в целом статистически значима на уровне 0,01.
Однако это не означает, что все независимые переменные значимы. Каждая независимая переменная должна быть подвергнута отдельной проверке на статистическую значимость. Мы это сделаем, когда будем проверять отдельные параметры. Но вначале мы хотим рассмотреть еще один способ полного статистического тестирования по средней квадратичной ошибке оценки.
Средняя квадратичная ошибка оценки. Средняя квадратичная ошибка оценки характеризует разброс наблюденных точек от теоретической линии регрессии. Если имеется средняя квадратичная ошибка оценки, 5, то можно рассчитать доверительные интервалы для оцененных значений зависимой переменной при различных уровнях доверия. Доверительный интервал представляет собой такой диапазон значений, в котором в течение некоторого заданного отрезка времени можно ожидать данное наблюдение.
Средняя квадратичная ошибка оценки - это оцененное среднее квадратичное отклонение вероятностного распределения значений зависимой переменной при поддержании на постоянном уровне всех независимых переменных. Иными словами, она определдет разброс случайных наблюденных значений Q относительно оцененных значений Q . Для множественной регрессии средняя квадратичная ошибка оценки рассчитывается как квадратный корень среднего значения суммы квадратичных отклонений (погрешность среднего квадрата) по формуле:

На компьютерной распечатке, представленной в табл. 8.2, средний квадрат ошибки составляет 4,73828. Тогда средняя квадратичная ошибка оценки составит
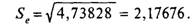
Так как мы предположили нормальное распределение отклонений от оптимальной плоскости, можно ожидать, что около 68% всех наблюденных значений Q будет находиться относительно плоскости регрессии внутри некоторого интервала, равного одной средней квадратичной ошибке; около 95% значений можно ожидать лежащими внутри интервала, равного двум средним квадратичным ошибкам, и практически все точки можно ожидать лежащими внутри интервала, равного трем средним квадратичным ошибкам. Конечно, чем меньше средняя квадратичная ошибка, тем больше связь между зависимой и независимой переменными и тем лучше подходит уравнение регрессии к наблюденным данным.
Тестирование отдельных параметров
До сих пор мы проводили проверку надежности и значимости независимых переменных как группы, предполагая при этом, что все они изменяются одновременно. Необходимо провести для каждой независимой переменной отдельную проверку на надежность и значимость, «заморозив» при этом все остальные переменные. Для этого мы используем среднюю квадратичную ошибку коэффициента регрессии и /-тестирование. Обе эти величины включены в стандартную компьютерную распечатку.
Средняя квадратичная ошибка коэффициента регрессии (Standard Error of the Regression Coefficient - SERC). Каждый регрессионный коэффициент, b., является средним значением нормально распределенных вероятностных значений. Средняя квадратичная ошибка коэффициента регрессии определяет разброс значений относительно коэффициента регрессии так же, как среднее квадратичное отклонение определяет разброс случайных переменных относительно их среднего значения. Чтобы рассчитать SERC, компьютерная программа использует сложную формулу для каждого коэффициента регрессии, а результаты расчета выводятся на распечатку.
SERC позволяет определять надежность каждого параметра по отдельности. Если средняя квадратичная ошибка мала по сравнению с оцениваемым параметром, то это говорит о том, что этот параметр близок к истинному значению. Тем не менее следует определить, может ли истинный параметр быть равным нулю. С этой целью для получения соотношения /-тестирования коэффициент регрессии делится на среднюю квадратичную ошибку, а результат этой операции также выводится в числе стандартных выводимых данных компьютерной программы. Иными словами, /-соотношение есть количество средних квадратичных ошибок, содержащееся в коэффициенте регрессии1. Оно рассчитывается как
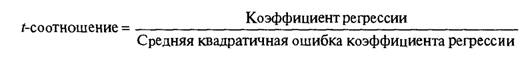
и используется для проверки статистической значимости каждого отдельного параметра.
Определение индивидуальной значимости с помощью /-тестирования. Если отдельная переменная является статистически значимой, то истинное значение ее параметра
' Так как средняя квадратичная ошибка коэффициента регрессии всегда положительна, (-соотношение принимает знак коэффициента регрессии. Знак не играет роли — нам важно только значение.
не может равняться нулю. Следовательно, мы должны провести проверку нулевой гипотезы на равенство нулю параметра при переменной (т.е. Н0 : р. = 0). Если можно отбросить это предположение, то мы можем быть уверены, что независимая переменная никак не влияет на зависимую переменную. Мы можем проверить это предположение с помощью /-соотношения и соответствующего /-распределения.
t-распределение. Это распределение малых групп значений из неизвестного набора. Подобно нормальному распределению, /-распределение симметрично относительно нуля, а площадь под его кривой равна единичной вероятности. Точный размер кривой зависит от числа степеней свободы, рассчитанного как и — Лс — 1, где Лс — количество независимых переменных, а и — количество наблюдений в выборке. По мере увеличения объема выборки /-распределение приближается к нормальному, и при бесконечно большом числе степеней свободы эти два распределения совпадают. Приближение к этому пределу происходит довольно быстро. Существует довольно широко применяемое правило, говорящее о том, что нормальное распределение применимо при п > 30.
Как правило, /-статистика и /-распределение применяются для проверки гипотез при уровне статистической значимости а, где а — вероятность ошибки типа 1, обычно принимаемая за 0,05 или 0,01. Для проведения проверки разделим соответствующее t- распределение на три части (рис. 8.4). Точно в середине (что соответствует математическому ожиданию) «вырежем» отрезок, равный (1 — а) от полной вероятности, ограниченный слева величиной -/ , а справа - величиной +/и/2. Иначе говоря, в каждом «хвосте» остается вероятность а/2. Вместо этого (что не показано на рисунке) всю величину можно поместить в один «хвост», правый или левый, ограниченный величиной плюс или минус /и.
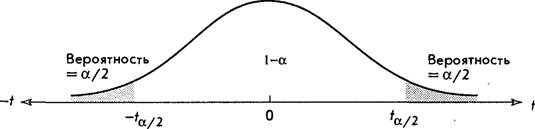
Рис. 8.4. Типичное распределение с /-критерием по двум «хвостам»
t-mecmupoeanue по одному и по двум «хвостам», /-тестирование проводится для проверки нулевой гипотезы о равенстве нулю коэффициента р.. Если эта гипотеза может быть отвергнута на уровне значимости а, то можно заключить, что переменная X. статистически значима на уровне а.
В основном /-тестирование может проводиться по одному или по двум «хвостам» распределения. В первом случае необходимо выявлять отклонения от нуля только в одном направлении. Например, предположим, что производитель игрушек хочет проверить утверждение продавца своей продукции, что среднее время работы батареек в его игрушках составляет 10 ч непрерывной работы. В данном случае продавца не волнует, если среднее время работы будет больше чем 10 ч, но он вернет товар, если случайно в каком-либо образце среднее время работы составит менее 10 ч. Нулевая гипотеза имеет следующий вид: Н0: р = 10. Альтернативная гипотеза есть Я,: р < 10. Полная площадь несостоятельности нулевой гипотезы — левый «хвост» /-распределения. Для множественной регрессии тестирование по двум «хвостам» используется для проверки нулевой гипотезы о равенстве нулю истинного коэффициента регрессии: Я0: р = 0. Если можно отвергнуть эту гипотезу, то справедливо утверждение, что независимая переменная не имеет никакого
влияния на зависимую переменную. Мы можем отвергнуть эту гипотезу, если /-соотно- шение падает в любом из «хвостов» /-распределения.
Значение / показывает количество средних квадратичных отклонений от среднего, /-значения, равные + / (см. рис. 8.4), называются критическими значениями / для проверки по двум «хвостам», /-значения, равные ± /и (не показаны на рисунке), называются критическими значениями / для тестирования по одному «хвосту». Критические значения / содержатся в табл. F в Приложении в конце книги. Табл. F представляет собой матрицу, в строках которой расположены степени свободы, а в столбцах — значения а. Каждая ячейка матрицы содержит критическое значение /, соответствующее определенному уровню значимости (заданному числу степеней свободы), которое определяет /-распределение.
Заголовки столбцов имеют два индекса: верхний, а/2, и нижний, а. Следует отметить, что /-критерий статистической значимости коэффициентов регрессии требует только сравнения /-соотношения с критическим значением / для выбранного уровня значимости при соответствующем числе степеней свободы: Если /-соотношение больше, то мы отвергаем гипотезу, что р. = 0, и приходим к выводу, что переменная X. Статистически значима на уровне а.
В примере, представленном в табл. 8.2, дано /-соотношение для Xt = 81,942 и Х2 = 9,504. Предположим, мы хотим проверить значимость на уровне 0,01. В табл. F находим критическое значение / для а/2 = 0,005 и df— 12. Это значение равно 3,055. Так как оба этих отношения во много раз больше критического значения, мы приходим к выводу, что обе переменные статистически значимы на уровне 0,01.
Доверительные интервалы для коэффициентов регрессии. Если /-критерий показывает, что истинный параметр не равен нулю, все же с некоторым уровнем уверенности хотелось бы знать интервал, в котором лежит истинный параметр. Этот интервал легко найти, зная коэффициент регрессии, Ь., среднюю квадратичную ошибку коэффициента регрессии, Sbi (которая в данном примере рассчитана на компьютере), и соответствующее значение / из табл. F.
Выбрав а (вероятность ошибки типа 1) и определив желаемый уровень доверия 1-а (вероятность несовершения ошибки типа 1), получаем доверительный интервал для b:

Еще по теме Тестирование и оценка результатов:
- Оценка результатов деловой коммуникации
- Коллективные представления о критериях оценки результатов
- Критерии оценки результатов.
- § 5. Оценка результатов осмотра места происшествия
- Особенности оценки затрат и результатов в общественном секторе
- Оценка результатов следственного эксперимента.
- Оценка результатов обучения
- Оценка результатов проделанной работы
- Этап оценки результатов информатизации.
- Экологическая оценка по результатам реализации проекта ХДТ.
- Оценка результатов работы подчинённых
- Оценка результатов лазерной коррекции
- Оценка результатов
- 2.1. Оценка результатов научных проектов
- Оценка результатов подбора
- Оценка результатов деятельности структурных подразделений предприятия