Использование схем в системе TEXT
Схемы в системе TEXT используются для управления процессом синтеза, а именно для принятия решения о том, что сказать дальше (на каждом данном шаге в процессе создания текста). Они выполняют роль плана текста.
Четыре схемы, разработанные нами по результатам анализа текстов (рис. 5—8), используются в качестве основы для схем системы TEXT.Схемы были реализованы с использованием формализма, основанного на расширенной сети переходов (ATN) (Woods, 1970). ATN есть представление грамматики в виде графа; оно позволяет приписывать дугам действия, которые могут создавать или проверять различные регистры. Первоначально формализм ATN был создан для анализа предложений. В случае анализа предложения движение по некоторой дуге влечет за собой обработку некоторого слова из входной цепочки и расширение дерева синтаксического анализа таким образом, чтобы оно включало новое слово вместе с его категорией.
В системе TEXT ATN используется не для построения дерева анализа, а для построения дискурса. Движение по дуге соответствует выбору некоторой пропозиции для формируемого ответа, а состояния в сети соответствуют заполненным состояниям схемы ответа. В ходе этой процедуры обработки какой-либо цепочки не происходит; вместо этого обрабатывается фонд релевантных знаний, хотя и не по порядку, и он не обязательно оказывается полностью исчерпанным после того, как построен граф.
Существенное различие между ATN, используемой в системе TEXT, и обычной ATN касается управления альтернативными вариантами. В системе TEXT для каждого состояния вычисляются все возможные последующие состояния и для выбора одной из множества возможных дуг используется функция, осуществляющая фокусные ограничения. Таким образом, хотя исследуются все возможные последующие состояния, реально выбирается только одно. В этом состоит отличие от обычной ATN, где допускается отслеживание вариантов (backtraking) без каких-либо ограничений.
Как только схема для данной ответной реакции выбрана, ответ строится путем прохождения схемы, начиная с исходного состояния. Вопрос о том, можно ли пройти по данной дуге, решается в зависимости от типа дуги. В ATN-графах системы TEXT имеется пять типов дуг: fill, jump, push, subr и pop. Дуги fill используются для представления предикатов схемы. С каждым предикатом связана функция, которая „сопоставляет" его с фондом релевантных знаний и выбирает все пропозиции фонда, соответствующие данному предикату. По дуге типа fill можно пройти в том случае, если ее предикат подбирает хотя бы одну пропозицию из фонда. После прохождения дуги подобранная пропозиция включается в схему.
Дуги типа jump функционируют так же, как и в обычных ATN, и используются для обработки факультативных предикатов. Дуги subr (subroutine — подпрограмма) используются для упрощения графа. Они обозначают некоторый подграф, и по ним можно пройти в том случае, если можно пройти по названному подграфу. Дуги типа pop отмечают выход из графа, дуги push используются для рекурсии.
На рис. 10 — 14 показаны графы, в которых реализованы схемы, используемые в системе TEXT. Схемы системы TEXT не содержат тех предикатов исходных схем, для которых отсутствует информация в предикатной области системы, и, таким образом, эти схемы являются подмножествами соответствующих схем, полученных нами в результате предварительного анализа текстов (см. рис. 5 — 8).
Граф идентификации системы TEXT (рис. 10 и 11) имеет в качестве первой дуги дугу типа fill, выходящую из начального состояния ИД/11. Эта дуга представляет первый предикат схемы — предикат идентификации. За первой дугой следует факультативная дуга (subr Описание/), которая может быть пропущена, если выбрана дуга jump, также выходящая из состояния ИД/ИД. Подграф, имеющий название Описание/ (рис. 11), представляет вторую строку исходной схемы и учитывает три предиката из этой схемы. За этим
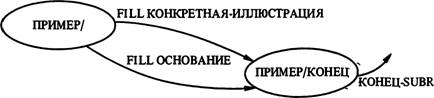
ззо подграфом следует по крайней мере один предикат из подграфа Пример/ (то есть либо „конкретная иллюстрация", либо „основание").
Дуга Пример/ ведет к состоянию ИД/ПР, из которого по дуге pop можно выйти из схемы. С другой стороны, можно получить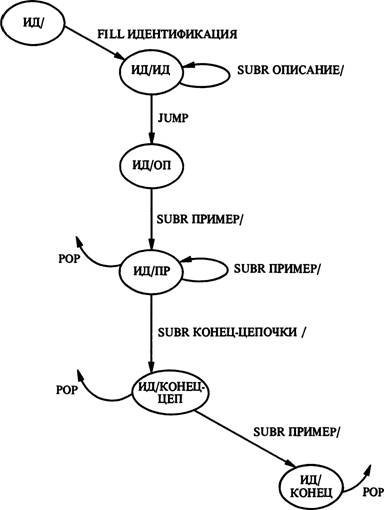
Рис. 10. Граф схемы идентификации.
еще несколько прогонов дуги Пример/ с помощью циклического возврата через состояние ИД/ПР или пройти по дугам факультативных предикатов из подграфа Кон-цеп/, за которым опять следует еще одна факультативная дуга Пример/. Эти две последние дуги соответствуют двум последним строчкам исходной схемы (рис. 5).
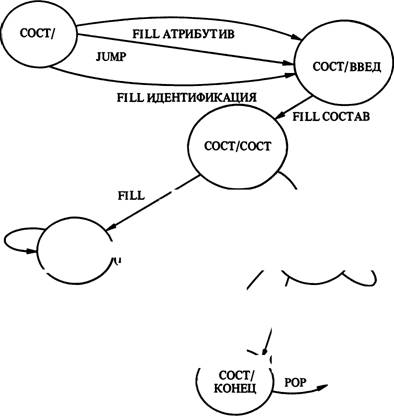
И схема состава (рис. 12), и схема атрибутива (рис. 13) в системе TEXT являются модифицированными версиями схем, полученных при анализе текстов. Граф состава имеет в качестве факультативного начала предикат „атрибутива" или предикат „идентификации", так что он может быть использован для построения ответов на запросы об имеющейся информации или об определениях. После состояния СОСТ/ВВЕД граф отражает соответствующую схему
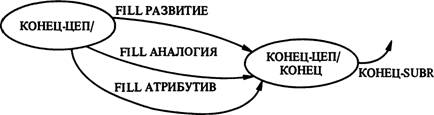
Рис. 11. Подграфы схемы идентификации.
FILL АТРИБУТИВ
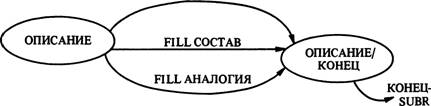
(рис. 6). Заметим, что две альтернативы, имеющие место в схеме („причина — следствие *" и „атрибутив *"), из версии системы TEXT исключены, остается лишь альтернатива, начинающаяся с предикатов „глубинная идентификация"/„глубинный атрибутив". В граф включены только два предиката из последней строки схемы („атрибутив" и „аналогия").
Граф атрибутива в системе TEXT не включает имеющиеся в исходной схеме (рис. 7) предикаты „ограничение", „вопрос", „проблема", „ответ" и „противопоставление", поскольку они не отражены в предметной области базы данных. Кроме того, предикат исходной схемы „представитель" в версии системы TEXT передан как „классификация", а предикаты „сравнение" и „противопоставление" — как „аналогия" (чтобы опираться на уже использовавшиеся предикаты).
Из последней строки исходной схемы в граф системы TEXT включен только предикат „объяснение".Схема сравнения и противопоставления (рис. 14) была модифицирована для того, чтобы обеспечить равноправную противопоставленность этих понятий. Схема противопоставления, полученная
FILL '
Рис. 12. Граф состава.
FILL АТРИБУТИВ
"ИДЕНТИФИКАЦИЯ \ (ИСХОДНОЕ МНОЖЕСТВО) (ИСХОДНОЕ 1
МНОЖЕСТВОК™^—_ FILL атрибутив
FTI Ї OCHOR А НИР IT (СЛЕДУЮЩИЙ *
СОСТ/ИД ) ОСНОВАНИЕ / сост/ATP L у ЭЛЕМЕНТ
Исходное множество^ множества)
ИДЕНТИФИКАЦИЯ / / FILL ОСНОВАНИЕ
(СЛЕДУЮЩИЙ ЭЛЕМЕНТ / / (СЛЕДУЮЩИЙ ЭЛЕМЕНТ
МНОЖЕСТВА) / / МНОЖЕСТВА)
FILL АТРИБУТИВ /___________ /fill аналогия
Л Л(К0Н£ЦФОКУСНОГО МНОЖЕСТВА) МНОЖЕСТВА) '
из анализа текстов, предназначена для противопоставления главного понятия второстепенному. В большинстве случаев второстепенное понятие либо обсуждалось в предшествующем тексте, либо, по мнению автора, является известным читателю. В системе TEXT в настоящее время не сохраняются знания о предшествующей части дискурса, при этом модель пользователя строится только статически. Таким образом, система не знает, располагает ли пользователь большим объемом знаний об одном понятии, чем о другом, и сравнение должно носить уравновешенный характер. Эта уравновешенность
ззз
достигается за счет того, что вначале даются черты сходства между двумя объектами, а затем различия между ними.
Схема сравнения и противопоставления предписывает наличие контрастивной структуры, не уточняя, какие предикаты должны быть использованы. Чтобы это уточнить, схема системы TEXT пред-
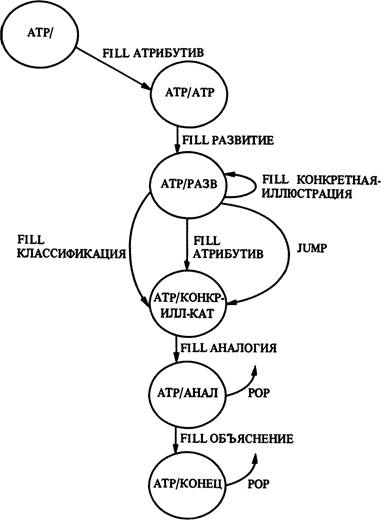
Рис. 13. Граф атрибутива.
усматривает рекурсивное использование трех других схем. Рекурсивное обращение к какой-либо схеме отмечается на графе дугой типа push. Когда происходит обращение к другой схеме, фонд знаний пополняется информацией, релевантной для этой части ответа (на рис. 14 это обозначается с помощью действия set (устанавливать, определять) на каждой дуге типа push).
В графе сравнения и противопоставления системы TEXT схема идентификации используется для установления сходства между двумя объектами. Схема, используемая для контрастивной части
PUSH АТРИБУТИВ (ОЧЕНЬ ПОХОЖИ)?
JUMP
(НЕТ СХОДСТВА)?
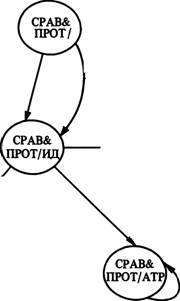
PUSH ИДЕНТИФИКАЦИЯ ^СХОДСТВО)?
МНОЖЕСТВО ИЗ ФОНДА ЗНАНИЙ = ФАКТЫ О МНОЖЕСТВЕ СУЩНОСТЕЙ
PUSH ИДЕНТИФИКАЦИЯ (ОЧЕНЬ НЕПОХОЖИ)?
МНОЖЕСТВО ИЗ ФОНДА ЗНАНИЙ = ФАКТЫ О СУЩНОСТИ 2
МНОЖЕСТВО ИЗ ФОНДА ЗНАНИЙ=ФАКТЫ О СУЩНОСТИ 1
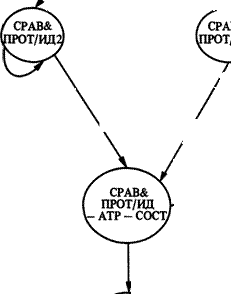
PUSH СОСТАВ (РАЗЛИЧИЕ МЕЖДУ КЛАССАМИ)?
FILL УМОЗАКЛЮЧЕНИЕ
POP
PUSH
ИДЕНТИФИКАЦИЯ (СЛЕДУЮЩИЙ ЭЛЕМЕНТ МНОЖЕСТВА)?
МНОЖЕСТВО ИЗ ФОНДА ЗНАНИЙ = ФАКТЫ О СЛЕДУЮЩЕЙ СУЩНОСТИ
'PUSH АТРИБУТИВ (СЛЕДУЮЩИЙ ЭЛЕМЕНТ VJUMP JUMP/ МНОЖЕСТВА)?
' МНОЖЕСТВО ИЗ ФОНДА ЗНАНИЙ = ФАКТЫ О СЛЕДУЮЩЕЙ СУЩНОСТИ

Рис. 14. Граф сравнения и противопоставления.
ответа, зависит от того, какова семантическая информация о сравниваемых сущностях. Может использоваться либо схема идентификации, либо схема атрибутива, либо схема состава в зависимости от того, являются ли эти две сущности совсем непохожими, очень
похожими или занимают промежуточное положение (что определяется с помощью проверок на каждой из этих трех дуг типа push). Эта проблема обсуждается ниже, в разделе, описывающем выбор схемы. Схема сравнения и противопоставления завершается прямым сравнением двух сущностей через предикат „умозаключение".
5.2.1. Формирование ответа на вопрос.
Чтобы ответить на вопрос, система TEXT прежде всего выбирает схему, управляющую формированием ответа. Затем ответ формируется путем заполнения схемы.
5.2.2. Выбор схемы.
Выбор стратегии ответа в соответствии с целью дискурса достигается в системе TEXT через установление соответствия между схемами и типами вопросов.
Например, в случае вопроса, касающегося определения термина, применимы одни схемы, в случае вопроса, касающегося описания некоторой информации,— другие. Распределение схем по типам вопросов представлено в сжатом виде на рис. 15.Рис. 15. Схемы, обслуживающие разные типы вопросов системы TEXT.
Запросы об определениях
Идентификация
Состав
Запросы об имеющейся информации
Атрибутив
Состав
Запросы о различиях между объектами
Сравнение и противопоставление
На основе данного типа вопросов выбираются связанные с ним схемы, способные служить в качестве структуры ответной реакции. Далее из этого множества выбирается одна-единственная схема на основе той информации, которая имеется для ответа на вопрос. Это один из случаев, когда семантическая информация взаимодействует с информацией о структуре дискурса для определения структуры синтезируемого текста.
В ответ на запросы об определениях и об имеющейся информации схема состава выбирается в том случае, если фонд релевантных знаний содержит „богатое” описание составных частей запрашиваемого объекта и меньше информации о самом объекте. Эта ситуация возникает тогда, когда запрашиваемый объект находится в иерархии базы знаний на более высоком уровне, чем некоторый заранее заданный уровень. Заметим, что чем более высокое место в иерархии занимает некая сущность, тем меньше имеется информации для описания представляемого ею множества частных случаев, поскольку чем больше оказывается класс, тем меньше общих свойств у членов этого класса. Если ситуация не такова, то используется схема идентификации для вопросов об определении и схема атрибутива для вопросов об информации. Так, для вопроса „Что такое управляемый снаряд?” (пример 10) выбирается схема состава, поскольку о подтипах управляемых снарядов имеется больше информации, чем о самом управляемом снаряде, тогда как для вопроса „Что такое корабль?” (пример 11) выбирается схема идентификации.
Схема сравнения и противопоставления всегда выбирается в ответ на запрос о различии между объектами, однако для определения подсхемы, обслуживающей контрастивную часть ответа, используются сведения о типе информации, находящейся в фонде релевантных знаний. Когда два объекта концептуально очень близки (см. McKeown, 1982), выбирается подсхема атрибутива. Это делается для того, чтобы описать подробные различия между ними (пример 12) 12. Когда два объекта очень сильно различаются, выбирается подсхема идентификации. Это делается для того, чтобы описать родовые различия между ними (пример 13). В остальных случаях выбирается подсхема состава.
Пример 10.
(определение УПРАВЛЯЕМЫЙ)
; Что такое управляемый снаряд?
Выбранная схема: состав
Словарная обработка. Вход в тактический компонент.
Управляемый снаряд — это самодвижущийся снаряд. В базе данных ONR существует два типа управляемых снарядов: торпеды и ракеты. У ракеты цель находится в воздухе или на поверхности земли. У торпеды цель находится под водой. Местонахождение цели ракеты отмечается атрибутом БД ОПИСАНИЕ, а характеристики полета вводятся атрибутом БД ВЫСОТА. Подводные характеристики торпеды вводятся атрибутами БД под рубрикой ГЛУБИНА (например, МАКСИМАЛЬНАЯ ГЛУБИНА ДЕЙСТВИЯ). Атрибуты БД для управляемого снаряда — ВРЕМЯ ДО ЦЕЛИ & ЕДИНИЦЫ, ГО- РИЗ. ДАЛЬНОСТЬ & ЕДИНИЦЫ и НАЗВАНИЕ.
Пример 11.
(определение КОРАБЛЬ)
; Что такое корабль?
Выбранная схема: идентификация.
Словарная обработка. Вход в тактический компонент.
Корабль — это водное транспортное средство, движущееся по поверхности воды. Характеристики его поверхностного хода вводятся атрибутами БД ВОДОИЗМЕЩЕНИЕ и ОСАДКА. В число других атрибутов БД для корабля входят: МАКСИМАЛЬНАЯ СКОРОСТЬ, ДВИГАТЕЛЬ, ТОПЛИВО (ЗАПАС ТОПЛИВА и ВИД ТОПЛИВА), РАЗМЕРЫ, ДАЛЬНОСТЬ ПЛАВАНИЯ В ЗАВИСИМОСТИ ОТ СКОРОСТИ и ОФИЦИАЛЬНОЕ НАЗВАНИЕ. Например, „DOWNES” имеет МАКСИМАЛЬНУЮ СКОРОСТЬ 29, ДВИГАТЕЛЬ — ПАРОВУЮ ТУРБИНУ, ТОПЛИВО —810 (ЗАПАС ТОПЛИВА) и БУНКЕРНОЕ (ВИД ТОПЛИВА), РАЗМЕРЫ — 25 (ОСАДКА), 46 (ШИРИНА) и 438 (ДЛИНА) и ДАЛЬНОСТЬ ПЛАВАНИЯ В ЗАВИСИМОСТИ ОТ СКОРОСТИ — 4200 (ЭКОНОМИЧНАЯ ДАЛЬНОСТЬ ПЛАВАНИЯ) и 2200 (ДАЛЬНОСТЬ АВТОНОМНОГО ПЛАВАНИЯ).
Пример 12.
(различие КОРАБЛЬ-СОПРОВОЖДЕНИЯ КРЕЙСЕР)
; Чем отличается корабль сопровождения от крейсера?
Выработанная схема: сравнение и противопоставление-
атрибутив.
Словарная обработка. Вход в тактический компонент.
Крейсер и корабль сопровождения — надводные корабли. Характеристики надводного хода корабля вводятся атрибутами БД ВОДОИЗМЕЩЕНИЕ и ОСАДКА. Атрибуты БД корабля: МАКСИМАЛЬНАЯ СКОРОСТЬ, ДВИГАТЕЛЬ, ТОПЛИВО (ЗАПАС ТОПЛИВА и ВИД ТОПЛИВА), РАЗМЕРЫ, ДАЛЬНОСТЬ ПЛАВАНИЯ В ЗАВИСИМОСТИ ОТ СКОРОСТИ и ОФИЦИАЛЬНОЕ НАЗВАНИЕ. Корабли сопровождения имеют водоизмещение от 3400 до 4100. Все корабли сопровождения в базе данных ONR имеют: ЗАМЕЧАНИЯ — 0, ТИП ТОПЛИВА — БУНКЕРНОЕ, ВЫСОТА МАЧТЫ — 85 и ДВИГАТЕЛЬ — ПАРОВАЯ ТУРБИНА. Корабли сопровождения имеют на борту от 2 до 22 торпед, 16 ракет и 1—2 орудия. Крейсеры имеют ДВИГАТЕЛЬ — ПАРОВУЮ ТУРБИНУ и ДЛИНУ — от 510 до 673. Все крейсеры в базе данных ONR имеют: ЗАМЕЧАНИЯ — 0, ТИП ТОПЛИВА — БУНКЕРНОЕ. Все крейсеры имеют на борту от 8 до 42 торпед, от 4 до 98 ракет и от 1 до 4 орудий. Таким образом, корабль сопровождения имеет меньшую ДЛИНУ и меньшее ВОДОИЗМЕЩЕНИЕ, чем крейсер.
Пример 13.
(различие ЭСМИНЕЦ БОМБА)
; Какая разница между эсминцем и бомбой?
Выбранная схема: сравнение и противопоставление-
идентификация.
Словарная обработка. Вход в тактический компонент.
Эсминец — это надводный корабль с ОСАДКОЙ от 15 до 222. Корабль — это транспортное средство. Бомба — это свободно падающий снаряд, цель которого расположена на поверхности земли. Свободно падающий снаряд — это смертоносное средство разрушения. Таким образом, бомба и эсминец — совсем разные вещи.
5.2.3.
Еще по теме Использование схем в системе TEXT:
- 6.6. Использование топографических карт, планов, схем в деятельности уголовно-исполнительной системы.
- 2.1 Организационное проектирование на основании использования типовых структурных схем
- 2. Возможность использования схем в качестве языка философии
- 2.2.3. Идея схем в проектировании, типология схем
- МОДЕЛЬ СИНТЕЗА В СИСТЕМЕ TEXT
- ПРИМЕР РАБОТЫ СИСТЕМЫ TEXT
- 1.3. Анализ известных методик расчета тепловых схем модульных котельных и систем расчетов утилизации теплоты
- ОЦЕНКА ОТВЕТОВ, СИНТЕЗИРУЕМЫХ СИСТЕМОЙ TEXT
- 3.3.1. Внедрение и использование систем автоматизированного проектирования
- 3.2. Формирование и использование инструментария имидж-системы вуза
- Философский текст: культурно-коммуникационный аспект Philosophical Text: Cultural and Communicatory Aspect
- Использование рейтинговой системы FAROUT
- Использование системы вознаграждений.
- Принципы построения и использования информационных систем
- § 3. Правовые основы и возможности использования информационных систем в борьбе с преступностью
- 1.5 Исследование динамической системы с использованием пакета Mathcad
- 1.3 Исследование динамической системы с использованием пакета Matlab