ПРОГРАММЫ ФОРМИРОВАНИЯ СУЖДЕНИЙ, РАБОТАЮЩИЕ С ЕСТЕСТВЕННЫМ ЯЗЫКОМ
Описывая такую область, где известно очень немногое и работы часто строятся по принципу "попытаемся и посмотрим, что получится" (а область, о которой идет речь, именно такова), испытываешь естественное желание без каких-либо обобщений перечислить то, что в этой области сделано.
До сих пор мы избегали подобной манеры изложения, но сейчас мы позволим себе некоторую вольность и просто перескажем две работы, которые представляются особенно интересными. Мы не будем забывать о пяти вопросах, интересующих нас все время, в остальных же моментах описание этих работ не будет единообразным.СИСТЕМА МАКДЕРМОТТА
Существует тонкое, но весьма интересное различие между программой МакДермотта TOPLE (1974) и другими программами, описываемыми в наших статьях. Обычно системы (например, система понимания детских рассказов) делают основной упор на аппарат умозаключений, необходимый для ответа на вопросы по тексту. Основная задача TOPLE состоит не в выводе умозаключений и не в ответе на вопросы, а в формировании "системы убеждений" (believing). Основной вопрос, интересующий МакДермотта, состоит в следующем: "Каким образом мы приходим к определенному убеждению (начинаем верить во что-то)?" Интуитивно представляется, что здесь играет роль авторитетность источника и степень соответствия новой информации уже имеющимся убеждениям. МакДермотт исходит из этой общепринятой концепции и пытается ее расширить. Нас работа МакДермотта интересует потому, что рассматриваемый им процесс требует применения умозаключений.
Дальнейшее изложение почти целиком основывается на описании излюбленного примера МакДермотта. Система TOPLE способна обрабатывать предложения, относящиеся к узкой предметной области — ”микромиру", в котором имеются экспериментатор и обезьяна, находящиеся в одной комнате (ср. микромир системы Т. Винограда SHRDLU).
В системе SHRDLU ситуации относятся к "миру кубиков", а в системе TOPLE рассматривается проблема "обезьяна и бананы", описанная МакКарти. Работа МакКарти состояла в построении аксиоматики знаний, которые необходимы обезьяне, пытающейся достать подвешенные на потолке и непосредственно недоступные ей бананы. При этом имеется ящик, который можно передвигать, что позволяет обезьяне доставать бананы. МакДермотт не рассматривал детали этой ситуации, а просто использовал ее как достаточно известный пример.TOPLE воспринимает предложения в настоящем времени, касающиеся того, что происходит в комнате обезьяны и пытается "поверить" тому, что ей говорят, проверяя соответствие новых фактов тем, которые ей уже известны. В отличие от строго детерминированного "мира кубиков" (см. часть I статьи Уилкса), TOPLE допускает в своем мире некоторую неопределенность; это касается, например, местоположения предметов в комнате или причин, по которым обезьяна выполнила какое-либо действие. Однако все станет гораздо понятнее, если мы просто приведем некоторые примеры работы системы.
Как и Чарняк, МакДермотт не занимался специально анализом естественного языка, его интересовали только вопросы кореференции и неоднозначности, поэтому он тоже принял решение вводить в систему не предложения английского языка, а их семантические представления. В этих последних допустимы случаи неоднозначности, которые система должна разрешать самостоятельно. Мы будем приводить английские фразы, соответствующие этим семантическим представлениям.
The banana is under the table, by the ball.
‘Банан находится под столом, рядом с мячом/
Эта фраза обрабатывается как содержащая два утверждения. Первое утверждение нас не интересует, а второе представляет определенный интерес, поскольку, как отмечает МакДермотт, оно может описывать по меньшей мере две ситуации:
(13) Мяч тоже находится под столом.
(14) Мяч столь велик, что не помещается под столом; он находится около стола.
Очевидно, что ситуация (14) достаточно странная, так как мячи редко бывают такими большими; однако, если заменить мяч, скажем, на торшер, то соответствующая ситуация
(15) Торшер находится около стола.
будет вполне нормальной. TOPLE выберет ситуацию (13), поскольку имеет некоторое представление о вероятных размерах предметов в комнате.
Более интересным примером поведения программы будет ее реакция на фразу:
The monkey goes over to the table.
‘Обезьяна подходит к столу.’
TOPLE хочет ’’поверить" этому утверждению. Программа для GO ‘ИДТИ’ сообщает, что выполнение действия GO означает желание и возможность со стороны обезьяны выполнить это действие. Второе условие не вызывает трудностей, однако программа не знает, почему Спиро (так зовут обезьяну) хочет идти к столу. Подходящей причйной мог бы быть интерес обезьяны к чему-либо, находящемуся в данном месте — к столу, мячу или банану. У TOPLE нет оснований для того, чтобы предположить у Спиро интерес к столу, но Спиро может захотеть играть в мяч или съесть банан. Неопределенность в этом вопросе заставляет TOPLE генерировать два альтернативных варианта желаний и намерений Спиро. (Предлагаемое ниже представление отличается от представления МакДермотта тем, что последнее сложнее. Однако, поскольку мы не собираемся рассматривать и обсуждать это представление, в примере оно существенно упрощено.)
В ситуации 0:
(WANT SPIRO (HOLD SPIRO BAN 1))
‘(ХОТЕТЬ СПИРО (ДЕРЖАТЬ СПИРО БАНАН 1))’ (WANT SPIRO (EAT SPIRO BAN 1))
‘(ХОТЕТЬ СПИРО (СЪЕСТЬ СПИРО БАНАН 1))’ (HUNGRY SPIRO)
‘(ГОЛОДЕН СПИРО)’
(GO SPIRO TAB 1)
‘(ИДТИ СПИРО СТОЛ 1)’
В ситуации 1:
(AT SPIRO ТАВ1)
‘(У СПИРО СТОЛ 1)’
(PICK-UP SPIRO BAN 1)
‘(ПОДНИМАТЬ СПИРО БАНАН 1)’
В ситуации 2:
(HOLD SPIRO BAN 1)
‘(ДЕРЖАТЬ СПИРО БАНАН 1)’
(EAT SPIRO BAN 1)
‘(ЕСТЬ СПИРО БАНАН 1)’
В ситуации 4:
BAN 1 ceases to exist
‘БАНАН 1 перестает существовать’
Или:
В ситуации О':
(WANT SPIRO (HOLD SPIRO BALL 1)) ‘(ХОТЕТЬ СПИРО (ДЕРЖАТЬ СПИРО МЯЧ 1))’ (WANT SPIRO (PLAY SPIRO BALL 1)) ‘(ХОТЕТЬ СПИРО (ИГРАТЬ СПИРО МЯЧ 1))’ (GO SPIRO TAB 1)
‘(ИДТИ СПИРО СТОЛ 1)’
В ситуации 5:
(AT SPIRO TAB 1)
‘(У СПИРО СТОЛ 1)’
В ситуации 6:
(PLAY SPIRO BALL 1)
‘(ИГРАТЬ СПИРО МЯЧ 1)’
(PICK-UP SPIRO BALL 1)
‘(ПОДНИМАТЬ СПИРО МЯЧ 1)’
В ситуации 7:
(HOLD SPIRO BALL 1)
‘(ДЕРЖАТЬ СПИРО МЯЧ 1)’
«В приведенном примере каждая ситуация описывает отдельное состояние мира, каждое последующее состояние является результатом действий в предшествующем состоянии.
Две последовательности ситуаций взаимно исключают друг друга: ситуации 1 и 5 обе являются продолжениями состояния 0. (Отметим, что состояние 0 имеет два варианта, каждый из вариантов запоминается.) Последовательности генерируются путем моделирования поведения Спиро с помощью целей, соответствующих его желаниям. ((HUNGR Y SPIRO) в ситуации 0 и (WANT SPIRO (PLAY SPIROBALL 1)) в ситуации O' являются главными допущениями, которые введены для объяснения поведения обезьяны».
В этом месте программа создает два ”возможных мира": в одном из них Спиро голоден, в другом — Спиро хочет поиграть. Далее каждый "мир" снабжается действиями, ожидаемыми при принятии соответствующего допущения о желаниях Спиро. Теперь системе нужно некоторое подтверждение одного или другого допущения. Следующая введенная фраза Spiro picks up the banana ‘Спиро поднимает банан’ и дает системе нужное подтверждение. А именно, эта фраза согласуется с предсказываемым действием в ситуации 1, что оправдывает всю серию ситуаций 0—4. В действительности были упомянуты только действия до ситуации 2; сведения о том, что Спиро съест банан, являются предсказанием системы TOPLE. Вторая последовательность ситуации (O', 5—7) будет просто отброшена как нереализованная.
Как и следовало ожидать, система понимания естественного языка TOPLE придерживается многих убеждений, которые нельзя считать выведенными из входных текстов, но о которых система "догадалась" самостоятельно; поэтому она должна давать себе отчет в том, по каким причинам она поверила в то, что вошло в ее "систему убеждений". TOPLE отличается от других рассматриваемых нами систем в том отношении, что если новая информация вступает в противоречие с ее догадками, то она способна предложить новые гипотезы, которые объясняют как старую, так и новую информацию.
Эту способность обеспечивает механизм TOPLE, который называется "кругом убеждений". Возьмем несколько модифицированный вариант одного из искусственных примеров МакДермотта (не имеющих ничего общего с миром обезьяны и бананов).
Пусть мы знаем, что Фред — птица, но он не летает. Чтобы поверить обоим этим утверждениям, мы должны построить гипотезу, объясняющую противоречие. Например, мы можем предположить, что Фред — пингвин. Для подкрепления этой гипотезы мы можем попытаться определить, где живет Фред, надеясь обнаружить, что он живет в Антарктике. Пусть, однако, нам удалось выяснить только то, что он живет в Южном полушарии. Это подкрепляет гипотезу, что Фред живет в Антарктике, но ни в коей мере не доказывает ее. Используя "круги убеждений", мы можем описать состояние наших знаний в текущий момент следующим образом. Посмотрим сначала только на одинарные непрерывные стрелки. Они образуют круг, соответствующий нашей исходной ситуации. Стрелки направлены от имеющихся утверждений, затрудняющих интерпретацию, к гипотетическому, которое разрешает противоречие. Но поскольку тот факт, что Фред — пингвин, нами(IS FRED BIRD)- (ЯВЛЯЕТСЯ ФРЕД ПТИЦА)"
(IS FRED PENGUIN) (FLIGHTLESS FRED)
(ЯВЛЯЕТСЯ ФРЕД ^—---------------------------- -(HE ЛЕТАЕТ ФРЕД).
И ПИНГВИН) (LIVES FRED SOUTHERN-HEMI)
(LIVES FRED ANTARCTICA) (ЖИВЕТ ФРЕД ЮЖН0Е ПОЛУШАРИЕ) (ЖИВЕТ ФРЕД АНТАРКТИКА)'-** ^
(IN ANTARCTICA SOUTHERN-HEMI)
(В АНТАРКТИКА ЮЖНОЕ ПОЛУШАРИЕ)
не доказан, мы пытаемся подтвердить его тем, что Фред живет в Антарктике, что изображено на схеме с помощью круга из двойных стрелок. Но и последнее утверждение ничем не доказано, поэтому мы используем утверждение о том, что Фред живет в Южном полушарии. Круг, образованный пунктирными стрелками, подкрепляет предположение о том, что Фред живет в Антарктике. Каждому кругу приписана (хотя и не показана на схеме) программа, которая помогает, когда для этого появляются основания, подвергать сомнению любой из элементов данного круга. Так, если мы узнаем, что Фред живет в Сиднее, то мы должны подвергнуть сомнению нашу гипотезу, что он живет в Антарктике. Чтобы найти выход, можно предположить, что либо Фред является страусом, либо он живет в зоопарке, и попытаться подкрепить эти гипотезы.
Что здесь особенно интересно, так это открывающаяся возможность измерения степени правдоподобия того или иного факта, которое можно осуществить путем подсчета количества неоправдавшихся предположений, понадобившихся программе для перевода некоторого факта из класса неправдоподобных в число правдоподобных. А это в свою очередь интересно потому, что, используя наши знания о мире, например, для установления антецедента местоимения, мы обычно руководствуемся не тем, что один из возможный способов приведет к неправдоподобной ситуации, а тем, что один способ дает несколько более правдоподобную ситуацию, чем другой (об установлении кореферентных связей см. часть II статьи Уилкса).
Возвращаясь к нашим пяти вопросам, мы можем сказать, что программа МакДермотта заслуживает внимания в нескольких аспектах. В отношении того, зачем и когда обращаться к умозаключениям (применение умозаключений), программа МакДермотта отличается от других программ, как мы уже говорили, тем, что умозаключения в йей делаются для подкрепления тех или иных взглядов, а не для заполнения пропусков в рассказе. А это, как было отмечено, открывает интересные возможности для установления кореферентных связей. В то же время сфера установления правдоподобия убеждений сама по себе настолько не разработана, что в этом отношении рассматриваемую программу практически не с чем сравнивать. Интересное решение предлагается в системе TOPLE для вопроса организации знаний.
Когда в систему вводится новое утверждение, то известные факты, с которыми оно должно комбинироваться с целью получения новых умозаключений, могут храниться в одном из двух мест. Наиболее очевидным местом является серия стандартных подпрограмм, помеченных ключевыми предикатами и примерно соответствующих базовым стандартным подпрограммам Чарняка. (Это очень приблизительное сравнение, поскольку МакДермотт использует названные подпрограммы еще и для поиска фактов.) Например, мы видели работу программы с ключевым предикатом GO, которая привела к построению двух возможных миров, соответствующих двум предположениям о том, зачем Спиро пошел к столу. Другим местом, где входное утверждение должно искать факты, является множественная "структура мира". Как мы помним, в зависимости от того, за бананом или за мячом пошел Спиро, TOPLE предсказывает два возможных продолжения рассказа. Каждое из продолжений опирается на собственный "возможный мир", то есть на отдельную базу данных, но обе эти базы связаны с "реальным миром" в том смысле, что факты, известные в реальном мире, вводятся в каждый из возможных миров. Таким образом, в этот момент актуализированы сразу три базы данных, которые организованы следующим образом (см. схему на с. 295).
Как уже говорилось, поступление следующей фразы (Spiro picked up the banana) подтверждает одно из высказываний того возможного мира, который расположен в левой части нашей схемы, и поэтому именно эта картина мира признается истинным продолжением "реального мира", а альтернативная картина мира отбрасывается. При этом производится ряд умозаключений. Так, выводится, что Спиро пошел к столу, чтобы поднять банан и съесть его.
Картина "реального мира", включающая информацию о расположении стола, банана и мяча

Картина мира, основанная на предположении, что Спиро хочет съесть банан (ситуации 0 — 4)
Картина мира, основанная на предположении, что Спиро хочет поиграть в мяч (ситуации 0'; 5-7)
Эта множественная структура мира выполняет в системе МакДермотта примерно ту же роль, что демоны в системе Чарняка, а именно — позволяет системе TOPLE предсказывать то, что может случиться, и узнавать подтверждения предсказаний, когда они встречаются. Однако с формальной точки зрения два названных механизма отнюдь не являются эквивалентными. Прежде всего, множественные миры не подсказывают ясного решения в том случае, когда ситуация допускает несколько альтернативных вариантов и при этом выбор варианта не влияет на дальнейший ход действия. Например, если человек сдает купленную вещь обратно в магазин, он может получить деньги, или специальный чек, или однотипную вещь, или другую вещь, но той же стоимости. Нетрудно представить себе единый демон, включающий все эти варианты. TOPLE же в этом случае, по-видимому, должна построить четыре разных мира. Кажется разумным видоизменить множественную структуру мира TOPLE таким образом, чтобы в ней допускались переменные и один и тот же мир мог бы допускать вариативность. Конечно, введение переменных нарушает первоначальный замысел МакДермотта, в связи с чем потребуются и дальнейшие переделки, необходимые для введения некоторого аналога демонов. Это возвращает нас к старому вопросу о том, в какой момент следует прекращать расширение одного формализма и заменять его другим формализмом.
В то же время множественная структура мира удобнее, чем демоны, при моделировании серии последовательных действий. И наконец, системы МакДермотта и Чарняка сходны в том отношении, что обе они не могут производить нужные обобщения в случаях, подобных описанной выше ситуации с использованием зонта.
СИСТЕМА РИГЕРА
Работу Ригера можно было бы считать интересной уже потому, что это первая попытка применения теории концептуальных зависимостей Шенка к проблемам умозаключений и знания. Однако, как представляется, по существу работа Ригера очень мало связана с теорией концептуальных зависимостей, что видно хотя бы из того, что в своих более поздних публикациях Ригер почти не упоминает эту теорию. С другой стороны, эта работа весьма значительна сама по себе, поэтому ее, по-видимому, можно рассматривать и независимо от теории концептуальных зависимостей.
Программа Ригера, которой он не дал названия, имеет своей основной задачей вывод умозаключений на основе входных текстов. Как и в системах Чарняка и МакДермотта, в системе Ригера на вход подаются не фразы естественного языка, а их формальные представления (на языке концептуальных зависимостей).
Ригер пытается охватить такой широкий круг проблем, что на одном коротком примере очень трудно показать все существенные черты его программы. Все же типичным для работы Ригера примером можно считать фразу такого типа:
John hit Магу ‘Джон ударил Мери/
Из этой входной фразы программа выведет умозаключения типа следующих:
(16) John probably used his hand.
|/Джон, возможно, использовал свою руку/
(17) Mary was probably hurt.
‘Мери, возможно, была ранена/
(18) John probably wanted to hurt Mary.
‘Джон, возможно, хотел ранить Мери/
(19) John might have been angry with Mary.
‘Возможно, до этого Джон рассердился на Мери/
(20) John and Mary are near each other.
‘Джон и Мери находятся близко друг к другу.’
Mary now wants to feel better.
‘Сейчас Мери хочет поправиться/
John probably wants Mary to feel better.
‘Джон, возможно, хочет, чтобы Мери поправилась.’
Этот пример типичен в следующих отношениях, (а) Умозаключения строятся на основе одной фразы. Ригер рассматривает также несколько примеров текстов длиной в 3—4 фразы, подавляющее же большинство его примеров состоит из 1—2 фраз. (Ь) Во фразах говорится о простых действиях, вроде действия ’’ударить", в них не рассматриваются более сложные события, такие, как "день рождения" или ’’покупка вещей в магазине", (с) Программа производит много сложных умозаключений, часть которых представляется несколько сомнительной — ср. последнее умозаключение в приведенном выше примере. Программа построила это умозаключение, поскольку она полагает, во-первых, что желание Мери поправиться является результатом того, что Джон ее ударил, и, во-вторых, что Джон хочет, чтобы произошли все следствия, вытекающие из его действия. Возможно, это конкретное умозаключение Ригер сочтет ошибочным, однако его общая позиция состоит в том, что программы, которые выводят ’’лишние" умозаключения, предпочтительнее программ, которые могут вывести слишком мало умозаключений.
Попытка прямого описания набора программ, входящих в систему (а задача системы состоит не только в простом построении умозаключений, но и в автоматическом понимании рассказов, в ведении диалога, в разрешении лексической многозначности и проблем референции, в ответах йа вопросы, относящиеся не столько к содержанию рассказов, сколько к модели мира, введенной в систему), неизбежно привела бы к введению большого количества деталей и мало дала бы по существу. Вместо этого мы охарактеризуем систему в рамках ответов на наши пять вопросов. Мы отвлекаемся от многих черт системы и рассматриваем лишь те ее аспекты, которые представляются наиболее интересными с теоретической точки зрения. Наше описание является скорее теорией Чарняка на базе программы Ригера (если понимать различие между теорией и программой так, как было предложено выше), чем теорией самого Ригера.
СЕМАНТИЧЕСКОЕ ПРЕДСТАВЛЕНИЕ. Как уже говорилось, Ригер использует теорию концептуальных зависимостей, которая, несомненно, относится к теориям семантических представлений.
ПРИМЕНЕНИЕ УМОЗАКЛЮЧЕНИЙ. Большая часть интересных, хотя порой и спорных, решений в системе Ригера относится к этому разделу. Например, в важном вопросе о том, какое количество умозаключений должно делаться по ходу прочтения текста, Ригер придерживается крайней точки зрения, считая, что их количество должно быть огромным. Конечно, никто в сущности не представляет, каким может оказаться нужное количество умозаключений, и потому сказать, что их количество должно быть огромным,— все равно, что не сказать почти ничего. Однако, принимая во внимание приводимые Ригером примеры умозаключений, которые, по его мнению, необходимы, а также его общую позицию относительно статуса умозаключений, можно считать, что предполагаемое в его работах количество умозаключений на несколько порядков выше того, с которым могли бы согласиться МакДермотт или Чарняк. Например, Ригер считает, что умозаключения рефлекторны, и человек, услышав фразу, производит их почти бессознательно. Цель таких "неуправляемых" умозаключений состоит в установлении соотношений между только что услышанным и известным ранее. Согласно Ри- геру, входные фразы как бы задают точки в "пространстве умозаключений", а цель неуправляемых умозаключений — произвести расширение сфер вокруг этих точек в пространстве умозаключений таким образом, чтобы эти сферы пересеклись с другими, существовавшими ранее. Для сравнения отметим, что модели Чарняка и МакДермотта производят умозаключения только для заполнения специфических лакун, поскольку оба эти автора исходят из предположения, согласно которому неуправляемый вывод умозаключений выльется в огромное число операций и пересечение сфер не будет достигнуто за разумное время. Другим способом иллюстрации различия между двумя рассматриваемыми точками зрения может служить пример того, какие умозаключения Ригер считает разумным производить во время обработки входного текста.
Входная фраза: John told Mary that Bill wants a book.
‘Джон сказал Мери, что Билл хочет книгу.*
Умозаключения: Bill wants to possess a book.
‘Билл хочет получить книгу/
John believes that Bill wants a book. ‘Джон считает, что Билл хочет книгу/ Mary now knows that Bill wants a book. ‘Сейчас Мери знает, что Билл хочет книгу/ Bill probably wants to read a book. ‘Вероятно, Билл хочет прочесть книгу/ Bill might want to know the concepts contained in the book.
‘Возможно, Билл хочет знать содержание книги/
Bill might get himself a book. ‘Возможно, Билл получил книгу/ John might give Bill a book.
‘Возможно, Джон дает Биллу книгу/ Mary might give Bill a book.
‘Возможно, Мери дает Биллу книгу.’ John may want Mary to give Bill a book. ‘Возможно, Джон хочет, чтобы Мери дала Биллу книгу/
John and Mary may have been together recently.
‘Возможно, Джон и Мери недавно были вместе/
Из всех этих умозаключений другие исследователи признали бы разумным вывод только первого умозаключения. (Иначе говоря, существуют условия, в которых может быть выведено каждое из них. Например, если нам известно, что у Мери есть несколько экземпляров книги, о которой идет речь, то можно считать желательным предпоследнее умозаключение. Но это скорее исключение, чем общее правило.) Другие темы, рассматриваемые Ригером и относящиеся к применению умозаключений,— это соотношение между референцией и умозаключениями (см. часть II статьи Уилкса) и классификация умозаключений. Умозаключения классифицируются с точки зрения типа знаний, которые хочет получить тот, кто их производит. (Если читателю непонятно, почему эта тема отнесена к разделу "применение умозаключений", то он получит необходимые разъяснения позже.)
Не представляется возможным рассматривать все типы умозаключений, предлагаемые Ригером (ему самому на это потребовалось около 150 страниц). Поэтому мы ограничимся простым перечислением тех типов умозаключений, которые достаточно очевидны. (За исключением первого типа умозаключений, все остальное — цитаты из Ригера.)
1. Конкретизирующие умозаключения. На языке концептуальных зависимостей представление действий включает пробелы, которые заполняются текущей информацией (или конкретизируются). Например, именно умозаключение такого типа отвечает за то, что из фразы John hit Магу выводится информация о том, что Джон использовал свою руку (16).
2. Умозаключения, устанавливающие причину: каковы вероятные причины действия или состояния (см. пример 19).
3. Умозаключения, устанавливающие результа- т ы : каковы вероятные результаты действия или состояния (пример 17).
4. Умозаключения, устанавливающие мотивы: почему деятель хотел (хотел бы) совершить действие (пример 18).
5. Умозаключения, устанавливающие возможности: каким должно быть состояние "мира" для того, чтобы произошло данное действие (пример 20).
6. Умозаключения, устанавливающие функции: почему люди хотят владеть предметами.
7. Умозаключения, прогнозирующие возможности: если человек хочет, чтобы имело место некоторое состояние мира, то является ли это состояние результатом какого-либо прогнозируемого действия.
8. Умозаключения, устанавливающие отсутствие возможностей: если человек не может совершить желаемое действие, можно ли объяснить это отсутствием некоторого предшествующего состояния мира.
9. Умозаключения, устанавливающие контрмеры: если некоторое действие вызывает (вызовет) нежелательный результат, что может сделать человек для полного или частичного предотвращения действия.
10. Умозаключения, прогнозирующие действия: если известны потребности и желания человека, какие действия он может произвести для достижения своих потребностей.
11. Умозаключения, прогнозирующие расширение знаний: если известно, что человек располагает определенными знаниями, то какими еще знаниями он может располагать.
12. Нормативные умозаключения: если известно, что считается нормальным, установить, насколько достоверна некоторая информация при отсутствии точной информации.
13. Умозаключения, устанавливающие продолжительность состояний: предсказать примерную продолжительность состояния или действия.
14. Умозаключения, устанавливающие свойства: если известны некоторые свойства сущности и ситуации, в которых эта сущность имеет место, какие дополнительные свойства данной сущности можно предсказать.
15. Ситуационные умозаключения: какую дополнительную информацию о некоторой известной ситуации можно представить себе (или вывести).
16. Умозаключения, устанавливающие намерения говорящего: для чего говорящий это сказал; что можно вывести, зная то, как он это сказал.
Так, типичным примером умозаключения типа 7 (то есть умозаключения, прогнозирующего возможности) будет следующий:
Andy blew on the hot meat.
‘Энди подул на горячее мясо.’
Мы предполагаем, что Энди намеревается съесть мясо на том основании, что дуют на мясо для того, чтобы оно остыло, а определенная температура пищи — это обычная предпосылка (или, по терминологии Ригера, "условие, создающее возможность") приема пищи. Итак, из желания Энди добиться требуемого состояния мы делаем вывод о том действии, которое он хочет произвести.
Но для чего нам нужна такая классификация? Ее назначение — помочь ограничить число умозаключений, выводимых системой. Дело в том, что Ригер и другие авторы, работы которых рассматриваются в этой статье, считают, что большую часть выводов программа должна производить во время обработки входного текста, а не во время обработки запроса. В то же время, поскольку в принципе из фразы текста можно вывести бесконечное количество умозаключений, мы должны, по меньшей мере, выделить два класса умозаключений: те, которые система будет выводить немедленно, и те, которые будут выводиться только при поступлении соответствующего запроса. (Именно здесь и встает вопрос о применении умозаключений.) Но вопрос о том, какие умозаключения следует выводить немедленно, решается в соответствии с реальными задачами системы (как она должна преобразовать входной текст). Поэтому мало просто разделить умозаключения на две группы, скорее мы должны произвести более тонкую классификацию, в результате которой система сумеет определять границы, в которых следует выводить умозаключения при обработке входных текстов, изменяя эти границы в случае необходимости. Для этого и нужна классификация умозаключений.
Именно таким способом и использует Ригер свою классификацию, но, учитывая, что, согласно его мнению, исследователь не должен сильно ограничивать число выводимых системой умозаключений (вспомним расширение сфер умозаключений), его соображения об использовании типов умозаключений не кажутся слишком убедительными и, следовательно, его классификацию нельзя считать особенно полезной. Более того, сам он, по крайней мере до сих пор, использовал лишь четыре из предложенных им шестнадцати типов умозаключений. То, что он посвящает столько времени классификации и при этом не дает убедительных примеров ее использования, нельзя не признать серьезным недостатком его работы.
ОРГАНИЗАЦИЯ. Предложения Ригера в этой области можно объяснить в тех терминах, которыми мы пользовались при описании работы Чарняка. Нужная для вывода умозаключений информация сгруппирована в пучки (которые Ригер называет молекулами умозаключений), соответствующие базовым подпрограммам Чарняка. Единицам поиска фактов соответствуют у Ригера "нормальные молекулы" (с той разницей, что в системе Ригера эти единицы используются гораздо реже, чем у Чарняка, поскольку Ригер стремится вывести большинство умозаключений во время обработки входного текста). У Ригера нет образований, соответствующих демонам Чарняка,— более того, он критикует идею демонов, считая, что лучше немедленно производить все умозаключения, чем ждать указаний на необходимость введения демонов. Иногда это представляется правдоподобным; например, из того, что Джек голоден, следует, что он, возможно, поест. Если же использовать стратегию демонов, то следует включить демон, который попытается найти подтверждения того, что Джек ест. В этом случае допустимы обе стратегии, однако в других случаях отсутствие в системе Ригера демонов (или их эквивалентов) вызывает серьезные трудности. Например, если Дженет трясет копилку, демоны предусматривают возможности как наличия, так и отсутствия в ней денег. А каким образом введет оба такие утверждения система Ригера? Отметим, что МакДермотт решает эту задачу, используя альтернативные возможные миры, которые функционально в данном случае аналогичны демонам, Ригер же не имеет никаких средств для отражения альтернативных миров.
МЕХАНИЗМ УМОЗАКЛЮЧЕНИЙ. Молекулы умозаключений, которые, как указывалось, выполняют большую часть вывода умозаключений, являются на самом деле программами на LISP’e. Некоторые факты, такие, как основное назначение предмета (например, основное назначение телефона — передача информации), представлены в форме данных. Тем не менее большая часть фактов представлена в форме программ, и Ригер является сторонником процессуального представления.
СОДЕРЖАНИЕ. По существу, ответа нет.
СИСТЕМЫ, ИСПОЛЬЗУЮЩИЕ ФРЕЙМЫ
Большая часть современных работ по теме, рассматриваемой в этой главе, использует терминологию и идеи, которые восходят к работе Минского о фреймах (Minsky, 1975). Это — сложная работа, но ее ведущая мысль весьма проста: единицы знаний, используемые программой понимания текста, должны быть гораздо крупнее, чем те единицы, которые использовались в описанных выше системах. Мы будем рассматривать теорию фреймов Минского как относящуюся к организации, а не к четырем остальным интересующим нас вопросам. Тем не менее следует отметить, что работа Минского затрагивает много других про- 0лем, о которых мы даже не будем упоминать.
Отправным пунктом работы Минского является вовсе не естественный язык, а задача объяснения способности видеть. Проблема, с которой имеет дело Минский (как и всякий, кто работает с цифровой ЭВМ последовательного действия (то есть с машиной, осуществляющей в определенный момент только одну операцию)), состоит в том, чтобы смоделировать способность человека, входящего в комнату или куда-либо еще, охватить все единым взглядом. Если люди действительно видят именно таким образом, это может служить аргументом в пользу того, что их восприятие не "последовательно", а скорее "параллельно", то есть они воспринимают одновременно много разных частей одной сцены. Минский предположил, что способность видеть все единым взглядом иллюзорна, а на самом деле вйдение — протяженный во времени процесс. Но ему надлежало объяснить, каким образом оно осуществляется так гладко и быстро. Согласно Минскому, перед тем, как войти, например, в комнату, мы обычно имеем представление о том, что мы увидим. Если комната нам знакома, наше предварительное знание включает разного рода детали, например расположение мебели, покрытие пола и т. п. Если предположить, что все эти части соединены воедино в нашем представлении, то, входя в комнату, мы должны только проверить, произошли ли в комнате изменения по сравнению с нашим исходным представлением. Этот фрагмент знаний Минский называет фреймом. Но даже если мы входим в незнакомую комнату, мы все же имеем много информации о том, что ожидать. По меньшей мере тип двери скажет нам, что она ведет в комнату, а не в зал и не на улицу. Более того, обычно у нас имеется представление о типе комнаты — будь то жилая комната, комната в учреждении или класс, и в каждом из этих случаев соответствующий фрейм скажет нам, что именно нам следует ожидать, поэтому осмотр комнаты требует только сравнения данной конкретной комнаты с обычной комнатой этого типа. Таким образом, фрейм —это структура данных, представляющих стереотипную визуальную ситуацию. При переходе к естественному языку нам следует только отбросить слово "визуальный".
При таком подходе к нашим знаниям о комнате нам необходимы определенные средства для представления этих знаний. Если речь идет об известной нам комнате, нам нужно задать имеющиеся в ней предметы. Каждый предмет будем представлять единицей, называемой "терминалом" фрейма. Терминал описывает предмет, задавая его специфические черты. В случае стереотипной комнаты, например типичной комнаты в учреждении, терминалы будут описывать скорее не конкретные, а прототипические предметы, например "стандартный канцелярский стол". Терминалы задают типичные свойства предметов. Минский считает, что в действительности люди сводят конкретные предметы к их прототипам, в результате чего у них и формируются их собственные представления о стандартных предметах (как бы вводятся переменные с незаполненными значениями). Однако на самом деле теория Минского практически не зависит от того, описывает ли терминал неопределенный, "смазанный" образ канцелярского стола, который мы просто опознали, войдя в комнату, или определенный стандартный образ, который необходимо дополнить специфическими деталями конкретного стола.
Кроме терминалов, нам нужна информация об отношениях между объектами и о способах использования фрейма. Более того, нужны указатели, соединяющие данный фрейм с другими, описывающими ту же самую сущность (например, комнату), но с иных точек зрения. Так, входя в комнату, мы не видим стены, находящейся за нашей спиной, и потому, как считает Минский, описание этой стены в фрейме нашего "видения" должно отсутствовать. В то же время должны быть родственные фреймы, включающие описание этой стены. Для того чтобы избежать дублирования информации в родственных фреймах, принято соглашение о том, что фреймы могут иметь общие терминалы. Так, если у нас представлены четыре фрейма (каждый из них описывает вид комнаты, ориентированный на одну из стен), то во всех четырех будут даны описания предметов, находящихся в центре комнаты, а каждая стена будет фигурировать в трех фреймах. Разрешая использование фреймами общих терминалов, мы освобождаемся от необходимости вновь описывать уже описанные предметы (см. схему на с. 306).
Мы начали рассмотрение фреймов с их применения к описанию зрительных образов, поскольку это наиболее наглядный пример. Если обратимся к проблемам, касающимся естественного языка, то фреймы становятся более сложными. Прежде всего в этом случае Минский предлагает уже не единый тип фрейма, а четыре их типа, приблизительно соответствующих синтаксическому представлению, семантическому представлению, представлению стереотипных событий и представлению свойств коммуникативной ситуации. Первые два типа представлений достаточно понятны. Последний, четвертый тип, относится к способам
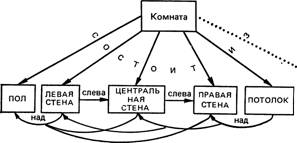
’Ач..........
/'Невидимая" ; задняя стена
подачи информации в рассказах, диалогах или научных трудах. Например, в рассказах обычно наличествует одно или несколько действующих лиц, сюжет, некоторая ведущая мысль. Во фрейме рассказа должны быть, следовательно, отражены принятые способы его построения. Существует много опытов подобного описания (с этой точки зрения можно взглянуть и на литературоведение), однако до сей поры еще не было предложено ничего, что могло бы внести достаточную для наших целей ясность в рассматриваемый вопрос.
Наиболее интересными из перечисленных типов фреймов представляются фреймы третьего типа, описывающие стереотипные события, или, как называет их Минский, ”фреймы сценариев". Минский не говорит ничего конкретного о таких фреймах, однако один из его примеров дает представление о его замысле. Это набросок фрейма, описывающего празднование дня рождения. Такой фрейм можно использовать для автоматического понимания простых рассказов типа тех, которые были рассмотрены выше. В частности, информация о том, что на день рождения принято дарить подарки, необходима для понимания таких рассказов, как, например, следующий:
Jane was invited to Jack’s birthday party. She wondered if he would like a kite.
m
‘Джейн пригласили на день рождения Джека. Она думала, понравится ли Джеку змей.’
Предложенный Минским набросок фрейма имеет вид:
ОДЕЖДА Лучше праздничная
ПОДАРОК Должен понравиться хозяину
Должен быть куплен и красиво упакован
ИГРЫ...... Прятки; жмурки
УКРАШЕНИЯ .... Воздушные шары, ленты, цвет
ная бумага
ПРАЗДНИЧНАЯ ЕДА Торт, мороженое, газированная
вода, бутерброды с сосисками
ТОРТ Свечи, задувание, пожелания,
пение, песни о дне рождения МОРОЖЕНОЕ .... Стандартное ассорти (из трех
цветов)
Это описание удовлетворяет предложенному выше общему виду фрейма: единицы левого столбца соответствуют терминалам, а единицы правого столбца задают значения переменных для каждого терминала. Однако сам Минский в той же работе утверждает, что задание терминалов и вопросы, при этом встающие, вызывают очень много трудностей. Затем он предлагает иную по сравнению с приведенной выше форму того же фрейма:
Y должен купить Р для Х‘а... Выбрать Р!
Х‘у должен нравиться Р Понравится ли Х‘у Р?
Купить Р с............................................. Где купить Р? Подвоп-
Достать деньги для покупки Р ... Где достать . росы для
деньги? I ФРейма
v тт подарок"
Y должен одеться Что должен г
надеть Y?
Сравнивая два предложенных варианта, отметим, что первый напоминает статическое описание того, что происходит на праздновании дня рождения, а второй выглядит скорее как набор инструкций, которые должен выполнить тот, кто впервые собирается на день рождения. Отметим, например, что во втором варианте не упоминаются украшения. Можно вообразить другую серию инструкций, для именинника (в качестве отдельного фрейма: как следует принимать гостей), и в этом фрейме будет упомянуто о выборе украшений.
ДАЛЬНЕЙШИЕ РАЗРАБОТКИ ФРЕЙМОВ
Сам Минский нигде не говорит о различии между двумя вариантами фреймов, однако многие его последователи отдают предпочтение второму варианту перед первым. Так, в двух недавних работах (Schank — Abelson, 1975 и Charniak, 1975b) описываются формальные объекты, весьма напоминающие сценарные фреймы Минского. В обеих работах фреймы представлены в форме инструкций относительно способа выполнения некоторого действия. В работе Шенка и Абельсона эти формальные объекты называются сценариями (scripts), как и в предшествующих работах Абельсона, о которых мы не имеем возможности здесь говорить. Предложенный ими сценарий касается поведения посетителя ресторана. Чарняк, вслед за Минским, называет соответствующие представления информации сценарными фреймами. Рассматриваемая Чар- няком предметная область — посещение магазина (универсама). Представляется, однако, что различие между предложениями Шенка — Абельсона, с одной стороны, и Чарняка, с другой стороны, чисто терминологическое, а содержательно между этими двумя представлениями ощутимого различия нет.
Как и у Минского, сценарный фрейм (далее — просто фрейм) — это структура данных относительно некоторой темы, такой, как покупка товаров в магазине, принятие душа или использование копилки. Каждый фрейм состоит прежде всего из набора утверждений о теме фрейма, называемых "утверждениями фрейма" (далее УФ). УФ примерно соответствуют терминалам Минского, особенно если рассматривать терминалы как вопросы к теме фрейма. (Вопросы можно считать способом выражения утверждений, ив Minsky, 1975 нет никаких указаний на противное.) УФ записаны на подходящем для программной реализации семантическом языке, но в наших примерах мы пользуемся обычным английским языком.
Основным средством понимания фразы рассказа является ее соотнесение с одним или более УФ. Например, отдельным УФ во фрейме "посещение магазина" будет такоез
(21) SHOPPER obtain use of BASKET. ‘ПОКУПАТЕЛЬ берет КОРЗИНУ.’
(SHOPPER, BASKET и в принципе любая часть УФ, написанная заглавными буквами, являются переменными. Эти переменные имеют ограничения; так, ПОКУПАТЕЛЬ — это, вероятно, человек, и по меньшей мере — одушевленное существо, а КОРЗИНА относится к классу корзин, а не, скажем, карманов.) Это УФ будет соотнесено со второй фразой следующего текста:
(22) Jack was going to get some things at the supermarket. The basket he took was the last one left. ‘Джек собирался кое-что купить в магазине. Корзина, которую он взял, была последней.’
Здесь мы предполагаем, что часть второй фразы будет представлена следующим образом:
(23) Jack 1 obtain use of basket 1.
‘Джек 1 берет корзину 1.’
(Напомним, что и (21) и (23) на самом деле записаны на общем семантическом языке.) Сведения о том, что (23) появилось при сопоставлении (22) с (21), задаются в форме специального указателя от соответствующей фразы текста к УФ.
Фрейм посещения магазина имеет ряд других УФ, связанных с (21), например, таких:
(24) (21) usually occurs before (25).
‘(21) обычно происходит раньше, чем (25).*
(25) SHOPPER obtains PURCHASE-ITEMS. ‘ПОКУПАТЕЛЬ берет ТОВАРЫ.’
Каждая модификация (например (24)) определенного УФ считается верной для всех утверждений рассказа (УР), соотнесенных с УФ (например (23)), если нет очевидных указаний на противоположное. Поэтому с помощью (24) мы можем заключить, что ко времени события (22) Джек еще не закончил покупку товаров. Другие модификации
(21) укажут, что, вероятно, Джек был в магазине, когда он брал корзину, и что он взял ее для использования в магазине.
Переменная SHOPPER в (21) появляется также в (25), и, вообще говоря, одна переменная может использоваться во многих УФ. Поэтому сферой действия переменных должен быть по меньшей мере тот фрейм, в котором они появляются. Если УР соотносится с УФ, переменная УФ становится связанной. Естественно, что за этими случаями связанности (конкретизации) надо следить. Например, отсутствие подобного наблюдения приведет к тому, что система не заметит странности такого рассказа:
Jack went to the supermarket. He got a cart and started up and down the aisles. Bill took the goods to the checkout counter and left.
‘Джек пошел в магазин. Он взял тележку и стал катать ее взад и вперед по проходу. Билл отнес товары к кассиру у выхода и ушел.’
Вероятно, не следует в процессе наблюдения за такого рода случаями связанности действительно менять фрейм. Вместо этого можно оставлять фрейм нетронутым, а связанные переменные хранить в особой структуре, называемой образом фрейма (сокращенно ОФ). У фреймов, описывающих определенные действия, например покупку товаров, будут образованы отдельные ОФ для каждой реализации этого действия. Так, если два человека одновременно находятся в одном магазине или один человек посещает два магазина, то в обоих случаях такой ситуации будут соответствовать два ОФ, что позволит различать соответствующие случаи посещения магазинов.
Большая часть информации будет храниться в виде связанных переменных (покупатель, товар, магазин, тележка и т. п.). Однако информация о связанных переменных не исчерпывает всей той информации, которой мы хотели бы располагать в ОФ; например, нам, возможно, понадобится указатель от ОФ к некоторым, если не ко всем УР, которым сопоставлены УФ. Более интересен тот факт, что в ОФ фреймов, описывающих действия, указывается, на какой стадии развития ситуации находится действие для каждой фразы рассказа. Так, например, мы сочтем странным следующий рассказ:
Jack drove to the supermarket. He got what he needed, and took it to his car. He then got a shopping cart. ‘Джек приехал на машине в магазин. Он купил то, что ему было нужно, и отнес покупки в машину. Затем он взял тележку для покупок.’
Как мы уже сказали, УФ модифицируются с помощью утверждений, выстраивающих события ва времени, поэтому для того чтобы заметить странность рассказа, необходимо иметь в ОФ один или несколько указателей к УФ, с помощью которых определяется, какое из событий в уже проанализированной части рассказа является самым поздним по времени.
Чтобы читатель получил более наглядное представление о том, какой вид будет иметь подобный фрейм, мы приведем один пример, однако при его рассмотрении следует иметь в виду следующее: во-первых, это лишь небольшой фрагмент общего фрейма, описывающего покупку товаров в магазине, и, во-вторых, в этом фрагменте, возможно, содержится много неточностей.
(26) Goal: SHOPPER owns PURCHASE-ITEMS
‘Цель: ПОКУПАТЕЛЬ владеет ТОВАРАМИ’
SHOPPER decide if to use basket, if so set up cart-carry Fl
‘ПОКУПАТЕЛЬ решает, нужна ли ему корзина, если да, вызвать фрейм F1 ’’тележка"’
a) SHOPPER obtain BASKET * cart-carry ‘ПОКУПАТЕЛЬ берет КОРЗИНУ *”тележка“’
SHOPPER obtain PURCHASE-ITEMS ‘ПОКУПАТЕЛЬ берет ТОВАРЫ’
1
method-suggested ‘предлагаемый способ’
Do for all ITEM € PURCHASE-ITEMS ‘Выполнить для каждой ВЕЩИ-ТОВАРА’
SHOPPER choose ITEM € PURCHASE-ITEMS- COLLECTED
‘ПОКУПАТЕЛЬ выбирает ВЕЩЬ С ТОВАР- -ОТБИРАЕМЫЙ’
SHOPPER at ITEM ‘ПОКУПАТЕЛЬ у ВЕЩИ’
si de-condition COLLECTED at ITEM also ‘побочное условие, накладываемое также на ВЕЩЬ: ОТБИРАЕМАЯ’
method-suggested ‘предлагаемый способ’
b) —cart-carry (SHOPPER, BASKET, COLLECTED, ITEM)
‘тележка (ПОКУПАТЕЛЬ, КОРЗИНА, ОТБИРАЕМЫЙ, ВЕЩЬ)’
SHOPPER hold ITEM ‘ПОКУПАТЕЛЬ держит ВЕЩЬ’
с) ITEM in BASKET *cart-carry ‘ВЕЩЬ в КОРЗИНЕ *”тележка“’ COLLECTED - COLLECTED + ITEM ‘ОТБИРАЕМОЕ ОТБИРАЕМОЕ + ВЕЩЬ’
End ‘ Конец’
SHOPPER at CHECK-OUT-COUNTER ‘ПОКУПАТЕЛЬ у КАССИРА’
SHOPPER pay for PURCHASE-ITEMS ‘ПОКУПАТЕЛЬ платит за ТОВАРЫ’ SHOPPER leave SUPERMARKET ‘ПОКУПАТЕЛЬ покидает МАГАЗИН’
Мы не будем объяснять названия, которые в общих чертах понятны сами по себе, однако в двух местах мы хотим внести уточнения. Первое касается того, что фрейм вызывает ”подфрейм“ (”cart-carry“, строка (Ь)), который объясняет, как следует использовать в магазине тележку. Более того, строки (а) и (с) снабжены особыми пометами, показывающими, что они также являются утверждениями фрейма ’’тележка", в связи с чем они (/) применяются только тогда, когда фрейм ’’тележка" активизируется и (it) значительная часть их содержания определяется их местом в структуре этого фрейма (например, именно во фрейме ’’тележка" объяснено, почему товары следует складывать в тележку).
ФРЕЙМЫ VS. ДЕМОНЫ
Чтобы продемонстрировать некоторые достоинства фреймов, сравним их с демонами, которые были описаны выше. Одно преимущество фреймов перед демонами можно было заметить ранее. Речь идет о проблеме обращения с фактами типа фактов о зонте, которые потребовали построения особой схемы (12). Читатель может вернуться к этой схеме и убедиться самостоятельно, что она естественно покрывается моделью, основанной на фреймах (ср. особенно ’’использование зонта").
Однако фреймы обладают и другими преимуществами перед демонами. Чтобы их раскрыть, укажем на аналогию между демоном и УФ. Аналогия сводится к тому, что УФ выполняют именно ту функцию, которую призваны были выполнять демоны: они оценивают существенность фразы в данном контексте. Так, для приведенной ниже последовательности фраз оценка существенности каждой из них может быть определена на основании того, что они отвечают некоторым УФ, но не на основании того, что они отвечают некоторым демонам.
Jack got a cart.
‘Джек взял тележку.*
Jack picked up a carton of milk.
‘Джек взял пакет молока.*
Jack walked further down the aisle.
‘Джек пошел дальше по проходу.*
Jack walked to the front of the store. He put the groceries on the counter.
‘Джек пошел к выходу. Он положил бакалейные товары на прилавок.’
В этом сравнении интересно то, что демон содержит минимум 3—4 утверждения, тогда как УФ всегда состоят из одного утверждения. УФ обладают высокой компактностью, по крайней мере сравнительно с демонами. Причину этого заметить нетрудно. Демоны, будучи независимыми друг от друга фактами, должны сами связывать свои переменные, и большая часть демона имеет целью проверку правильности связывания переменных (например, единица демона BASKET ‘корзина’ должна быть сопоставлена с единицей, обозначающей корзину, а не пакет молока). Та же проверка осуществляется и для фрейма, но, поскольку переменные обычно проходят через весь фрейм, а не принадлежат отдельным УФ, эта проверка осуществляется более экономными средствами. Более того, структура фрейма в неявном виде содержит все умозаключения из каждого УФ, тогда как для демона эти умозаключения должны быть сформулированы эксплицитно. Таким образом, вторым преимуществом фрейма является экономия памяти, позволяющая вводить больше фактов.
Сравнение УФ и демонов выявляет и третий аспект, в котором, как представляется, УФ превосходят демоны. Многие критикуют модель, использующую демоны, за то, что каждое упоминание в тексте некоторой темы активизирует все связанные с ней демоны, хотя в действительности каждый раз используется лишь небольшая их часть. Такой подход может вызвать возражения по одной из двух причин. Одна состоит в том, что наличие множества потенциально допустимых демонов затрудняет выбор тех, которые действительно следует применять в данном случае. Но эта трудность возникает и при использовании фреймов, поскольку число демонов и УФ сравнимы.
Вторая причина недовольства большим количеством активизируемых демонов касается времени, затрачиваемого на их применение. Если предположить, что вызов демона практически не занимает времени, то никакой проблемы не будет. Однако на самом деле эта процедура все же занимает время, и поэтому трудно оправдать вызов демона, который впоследствии не используется. Фреймовый подход предлагает возможный способ решения этой проблемы, поскольку вместо того чтобы вызывать все демоны, связанные с темой, нужно только построить по фрейму один его образ. Это позволит сэкономить время, но создаст и определенные неудобства. В особенности это касается вопроса поиска: поиск демона производится по индексу и является простым, тогда как просмотр фрейма с целью нахождения нужного утверждения — процесс более длительный, если не предложено никакой упрощающей этот поиск процедуры. Итак, при фреймовом подходе по сравнению с демонами требуется большее время на поиск внутри фрейма, но не требуется вызова неиспользуемых фреймов, как это происходит с демонами, что заставляет отдать предпочтение фреймовому подходу.
В заключение отметим, что во фреймах, которые приводились выше, не встает вопроса о временных отношениях между УФ. О демонах этого сказать нельзя. (Мы вскользь упоминули об этом, отметив, что "допустимые миры" МакДермотта лучше отражают временные отношения, чем демоны.) Мы видели, что во фреймах могут использоваться указатели, позволяющие программе выделять события, которые находятся вне временной последовательности. Что может служить эквивалентом этих указателей в модели, использующей демоны? Прежде всего, где будут храниться такие указатели? Соотносить каждый демон с временным указателем — путь самый неэлегантный, но не ясно, какой другой путь можно еще предложить. Кроме того, где будет храниться сама информация о временных отношениях? Отметим, что эта информация имеет гораздо более сложный вид, чем простая цепочка или даже решетка, отражающая временную соотнесенность. Некоторые временные отношения обязательны (то есть другой порядок действий невозможен), другие — предпочтительны (то есть другой порядок действий нежелателен), а третьи — регулярны (то есть другой порядок действий не принят) (См. Charniak, 1975а). В модели, использующей фреймы, информация о времени может храниться наряду с другой информацией в самом фрейме. Но как хранить эту информацию в модели, использующей демоны, совершенно неясно. Мы не говорим, что это вообще невозможно, однако хранение информации о времени как бы нарушает естественные свойства такой модели.
ЗАКЛЮЧЕНИЕ
По-видимому, фреймы превосходят демоны, но мы отнюдь не хотим вводить читателя в заблуждение и утверждать, что фреймы позволяют ответить на все вопросы, поставленные в нашей первой статье. Остановлюсь на некоторых трудностях, связанных с фреймовым подходом (выше мы о них даже не упоминали).
Одна трудность касается выработки формальных условий активизации фрейма (то есть условий, при которых начинается построение образа фрейма). Самым простым условием было бы наличие в тексте соответствующего ключевого слова (например, supermarket ‘универсам’). Однако очевидно, что это условие неудовлетворительно. Во-первых, часто упоминание слова в тексте не требует вызова фрейма, например, если мы описываем район и перечисляем все его магазины, включая универсам, то соответствующий фрейм не должен активизироваться. С другой стороны, активизация фрейма может понадобиться, даже если ключевое слово и не названо. Например:
As Jack walked down the aisle he picked up a can of tunafish and put it in his basket.
‘Когда Джек шел по проходу, он взял банку тунца и положил ее в корзину.’
Вопрос о том, как быть в такой ситуации, остается открытым.
Еще одна трудность, и значительно более существенная, состоит в том, что фреймы описывают только стереотипные ситуации. Такие ситуации стоят за любым текстом, однако каждый текст, чтобы не быть скучным, должен включать нечто, находящееся за пределами этого стереотипа. Мы не говорили о том, как использовать фреймы при понимании необычных поворотов, которыми полны как любые рассказы, так и сама жизнь.
Список подобных трудностей можно продолжать еще долго, но обратимся в заключение к проблеме, которая влияет на все системы, описанные в этой статье,— проблеме содержания. Возможно, читатель заметил, что каждый раз, когда мы пытаемся ответить на пять вопросов, последний вопрос остается без ответа. Ни один из авторов систем не предложил формальную процедуру выделения информации, нужной для понимания даже простейших рассказов. Это объясняется многими причинами, но основные из них две. Во-первых, проблема содержания исключительно сложна. Чарняк в работе (С h а г п і а к, 1974) попытался проанализировать информацию, необходимую для понимания последней фразы рассказа (16) в нашей первой статье (Не will make you take it back Юн заставит тебя взять его [мяч] обратно’). Его весьма неполный анализ занял около 100 страниц. Во-вторых, нельзя преуспеть в разрешении этой проблемы, если не располагать (хотя бы в общем виде) формальным языком для представления содержания, в противном случае можно написать лишь еще один текст на естественном языке, что мало приблизит нас к цели. Следовательно, мы сможем пытаться формализовать некоторый обозримый фрагмент знаний о мире, необходимый для понимания естественного языка, не ранее, чем мы обретем некоторую уверенность в пригодности используемого нами языка представления знаний.
Тем не менее дело не так безнадежно, как может показаться из предшествующего абзаца. Наши знания в рассматриваемой области увеличиваются, хотя цель все еще далека. Сравним фреймовый подход хотя бы с системой Рафаэл a SIR (см. часть I этой статьи). Система Рафаэла была очень ограниченной, что в то время было неизбежно. Система SIR работала с примерами такого типа: A man has two hands. A hand has five fingers. How many fingers does a man have? ‘У человека две руки. На руке пять пальцев. Сколько пальцев у человека?’ Неясно, как можно было бы расширить SIR, чтобы она понимала назначение корзины в магазине. Новые системы понимают естественный язык в объеме, который для ранних систем был нереальным, а это уже достижение.
ЛИТЕРАТУРА
Charniak, Е. Toward a Model of Children’s Story Comprehension.— In: ’’Memoranda from the Artificial Intelligence Laboratory", Massachusetts Institute of Technology. TR 266, 1972.
Charniak, E. He will make you take it back: A study in the Pragmatics of Language.— In: ’’Memoranda from the Istituto per gli Studi Semantici e Cognitivi", 3. Switzerland, Castagnola, 1974.
Charniak, E. (1975 a). A Partial Taxonomy of Knowledge about Actions.— In: ’’Advanced papers for the Fourth International Joint Conference in Artificial Intelligence", USSR, Tbilisi, 1975 (MIT, Cambridge, Mass., 1975).
Charni ak, E. (1975b). Organization and Inference in a Frame-like System of Common Sense Knowledge.— In:’’Position papers for the Workshop on Theoretical Issues in Natural Language Processing, Massachusetts Institute of Technology", 1975 (BBN, Cambridge, Mass., 1975).
Minsky, M. A Framework for Representing Knowledge.— In: ’’The Psychology of Computer Vision" (Winston) (ed.). New York, McGraw- Hill, 1975, p. 211—277.
Schank, R. and A b e 1 s о n, R. Scripts, Plans and Knowledge.— In: ’’Advanced papers for the Fourth International Joint Conference in Artificial Intelligence", USSR, Tbilisi, 1975 (MIT, Cambridge, Mass., 1975).
АНАЛИЗ ПРЕДЛОЖЕНИЙ АНГЛИЙСКОГО ЯЗЫКА (ЧАСТЬ II)[60]
В этой статье мы продолжим рассмотрение систем, ориентированных на представление структур предложений естественного языка и анализ предложений с целью обнаружения этих структур. В конце статьи мы сопоставим системы, рассмотренные в этой и других работах, по ряду оснований.
Следует иметь в виду, что мы используем термин "анализ" (parsing) не только в стандартном смысле, принятом в математической и вычислительной лингвистике (где анализ понимается как процесс, абсолютно нейтральный к содержанию, к практической ценности или степени нетривиальное™ структур, приписываемых предложениям естественного языка). Так, в первой нашей статье мы иллюстрировали общее понятие анализа на примере грамматики непосредственных составляющих, но читатель уже понял наш вывод о том, что для получения результатов, представляющих хоть какой-нибудь интерес, требуются гораздо более богатые структуры представления смысла и знаний, чем те, которые порождаются НС-грамматиками. Таким образом, термин "анализ" в последующем изложении обозначает процесс, который отнюдь не является нейтральным к тому, что Ю. Чарняк в своей первой статье назвал содержанием представлений. Адекватным результатом анализа, как мы полагаем, могут считаться такие представления, которые проливают свет на явление, названное в нашей первой статье системной неоднозначностью языка, включающей лексическую, структурную (глубинно-падежную) и местоименно-референционную неоднозначность.
Еще по теме ПРОГРАММЫ ФОРМИРОВАНИЯ СУЖДЕНИЙ, РАБОТАЮЩИЕ С ЕСТЕСТВЕННЫМ ЯЗЫКОМ:
- § 1. Сущность суждения. Основания формирования суждений в процессе квалификации преступления
- Общая характеристика программы формирования психологического мышления студентов психологов
- Формирование территориальных программ государственных гарантий по обеспечению медицинским обслуживанием граждан
- 2.4. Расчет численности работающих в цехе 2.4.1. Состав работающих механосборочного цеха
- Глава 3 - Как правильно уйти с работы? «Революции не работают - работают эволюции...
- § 3. Отношения суждений. Логические правила определения истинности юридических суждений
- 91. Товарная политика - это совокупность решений, касающихся формирования эффективной рыночно-ориентированной производственной программы предприятия.
- О числе совершенных фрагментов из 2 и 4 суждений в традиционной интегральной силлогистике из 50 суждений с различной семантикой
- Основные версии естественного права Космологическое естественное право
- § 35. Номинативное полагание и суждение. Могут ли вообще суждения становиться частями номинативных актов
- ЛЕКЦИЯ № 12Сложные суждения. Образование сложных суждений
- О построении совершенной интегральной силлогистики традиционного типа из 50 базисных суждений на основе силлогистики из 42 суждений
- Постановка целей обучающих программ и программ подготовки для сотрудников организации
- Сомнение II О том, что бог наделил человека способностью суждения, подверженной ошибкам, хотя он мог бы дать ему способность суждения, свободную от ошибок
- 7.5. Основные риски при реализации государственных программ на примере программы «Повышение безопасности дорожного движения в 2006- 2012годах»
- 2. ВЗГЛЯД НА ПРИРОДУ ЯЗЫКОВЫХ УНИВЕРСАЛИЙ И ИХ ПОТЕНЦИАЛЬНОЕ ВЛИЯНИЕ НА ОВЛАДЕНИЕ ВТОРЫМ ЯЗЫКОМ ВЗРОСЛЫМИ УЧАЩИМИСЯ