1. Введение. Теория фонологии
Сущность фонологической теории, положенной в основу настоящего описания фонологической системы русского языка, может быть кратко выражена в шести формальных условиях, которым должно удовлетворять любое фонологическое описание.
По мере изложения я остановлюсь подробнее на значении этих условий, а следовательно, и предлагаемой теории для описания чисто фонетических фактов. Я постараюсь сравнить следствия, вытекающие из данной теории, со следствиями, вытекающими из других фонологических теорий.
Вполне исчерпывающий и обобщенный характер, а также простота «практических» следствий, вытекающих из предлагаемой теории, обусловливают ее целесообразность.
1.1. Условие (І). В фонологии речевые факты представляются в виде последовательностей единиц двух типов: сегментов, которым приписываются определенные фонетические признаки (как артикуляторные, так и акустические), и границ[213], которые характеризуются лишь влиянием, оказываемым ими на сегменты.
1.2. Условие (2). Фонетические признаки, используемые для характеристики сегментов, принадлежат к особому узкоотграниченному классу признаков, называемых различительными. Все различительные признаки являются бинарными.
Принятие условия (2) влечет за собой описание всех сегментов во всех языках в терминах ограниченного списка свойств, таких, например, как «назальность», «звонкость», «мягкость» и т. д. По отношению к этому списку свойств существенным является только вопрос: «Обладает ли данный сегмент определенным свойством?» Отсюда следует, что различия между сегментами могут быть выражены только различиями между тем, какие различительные признаки входят в один сегмент, а какие в другой. Следовательно, сегменты (даже в разных языках) могут отличаться друг от друга лишь ограниченным числом различий.
Большинство лингвистов и фонетистов считают, что все человеческие языки можно охарактеризовать посредством ограниченного числа фонетических признаков.
Эта точка зрения в том или ином виде выражена во многих работах по общей фонетике, начиная от «Visible speech» Белла, изданной в 1867 г., и кончая «General phonetics» Хеффнера, вышедшей в 1949 г. Однако многие ученые не согласны с таким мнением. Они считают, говоря словами одного из авторов, что «языки могут отличаться друг от друга беспредельно и самым неожиданным образом»[214].Отсюда вытекает, что условие (2) и точка зрения, приведенная выше, являются взаимно противоречащими суждениями о природе человеческого языка и подлежат эмпирической проверке. Если бы исследование самых различных языков показало, что число различных фонетических признаков, необходимых для фонологического описания, возрастает с увеличением числа исследуемых языков, то условие (2) пришлось бы отвергнуть. Если же, наоборот, подобный анализ показал бы, что по мере включения в исследование все большего числа языков, число различных фонетических признаков незначительно превосходит или совсем не превосходит некую конечную малую величину, то тогда следовало бы принять условие (2).
Несмотря на то что были обнаружены языки, обладающие фонетическими признаками, не присущими западным
Языкам, число таких признаков не Следует преувеличивать. Изучая фонетические модели, проверенные на многих языках, например модели, описанные в книге Н. Трубецкого «Grundzuge der Phonologie» или в книге К. Л. Пайка «Phonetics», а также модифицированный международный фонетический алфавит 1РА, успешно используемый в Англии при изучении африканских и восточных языков, нельзя не обратить внимания на небольшое число встречающихся фонетических признаков (порядка двадцати или менее). Поскольку описанные языки представляют весьма существенную часть всех языков мира, можно ожидать, что число релевантных фонетических признаков не будет значительно увеличиваться по мере того, как все новые языки станут подвергаться научному исследованию. Поэтому представляется, что нет достаточных оснований для того, чтобы по этой причине отвергнуть условие (2).
С другой стороны, условие (2) влечет за собой еще более строгое ограничение. Оно требует, чтобы сегменты определялись с помощью небольшого числа бинарных свойств: различи!ельных признаков[215]. Систематические исследования имеющегося материала по различным языкам продемонстрировали полную пригодность модели бинарных различительных признаков для фонологического описания[216]. До сих пор не было приведено примеров, которые бы поставили под сомнение правильность бинарной схемы[217]. Напротив, распространение бинарной структуры на все гризнаки позволило получить удовлетворительное объяснение некоторых «непонятных» фонетических изменений[218] и дало возможность сформулировать методику оценки фонологических описаний[219].
1.8. Сегменты и границы являются теоретическими конструктами. Следовательно, они должны быть соответствующим образом соотнесены с наблюдаемыми объектами, т. е. действительными фактами речи. Наиболее слабым условием, предъявляемым фонологическому описанию и принимаемым всеми, является
Условие (3). Фонологическое описание должно предусматривать метод получения (извлечения) первоначального высказывания из любой фонологической записи без обращения к информации, не содержащейся в этой записи.
Другими словами, предполагается, что можно будет прочесть фонологическую запись независимо от того, известны ли ее значение, грамматическая структура и т. д. Очевидно, это будет достигнуто только тогда, когда все отличные друг от друга высказывания будут записаны разными последовательностями символов. Однако совсем не обязательно выполнять обратное требование, поскольку можно составить правила, предусматривающие одинаковое чтение нескольких неидентичных последовательностей символов. Например, последовательности символов {m’ok bi} и {m’og bi} были бы произнесены одинаково, если бы было сформулировано правило, согласно которому незвонкие согласные озвончались бы в положении перед звонкими согласными.
Однако в этом случае окажется невозможным определить, исходя только из высказывания, какая из двух (или более) последовательностей символов является действительным отображением данного высказывания. Таким образом, в вышеприведенном примере человек, воспринимающий высказывание [m’ogbi] на слух, не сможет выбрать какое-либо одно из двух фонологических представлений этого высказывания, если не обратится к значению или другой информации, не содержащейся в сигнале. Отсюда следует, что данная последовательность звуков должна быть представлена лишь единственной последовательностью символов. Только в этом случае фонологические описания будут удовлетворять:Условию (За). Фонологическое описание должно включать правила получения (извлечения) точного фонологического отображения любого речевого факта без обращения к информации, не содержащейся в физическом сигнале[220].
1.31. Существует наиболее простой способ построений фонологического описания, которое бы удовлетворяло условию (3 а). Этот способ заключается в создании такой системы символов, при которой каждый символ будет соответствовать одному звуку и наоборот. Если система символов является исчерпывающей в том смысле, что она содержит символ для любого звука, то каждый человек, знакомый с фонетической значимостью символов, сможет не только правильно прочесть любую последовательность символов, но и однозначно записать любое высказывание в виде соответствующей последовательности символов. Именно таким образом фонетисты конца прошлого века пытались построить систему записи, удовлетворяющую условию (3 а). Это нашло свое отражение в знаменитом лозунге «Международной фонетической ассоциации» «Association Internationale de Phonetique»): «Для каждого
/звука особый символ». Однако хорошо известно, что все попытки провести данную идею в жизнь не увенчались успехом, так как они неизбежно приводили к, по-видимому, бесконечному увеличению числа символов, ибо, строго говоря, двух идентичных звуков не существует.
Единственным разумным выходом из этого положения явилось бы некоторое ограничение числа символов.1.32. Эта идея может быть сформулирована как:
Условие (3 а—/): Только различные высказывания
должны записываться с помощью разных последовательностей символов[221]. Число различных символов, которые используются во всех необходимых для этой цели записях, должно быть минимальным[222].
Другими словами, требование «для каждого звука — особый символ» заменено требованием «для каждого высказывания — особая запи ь», причем на число символов, применяемых для записи, было наложено ограничение. Однако ограничение вызвало ряд трудностей. Например, в английском языке [h] и [rj] не встречаются в одинаковом окружении. Согласно условию (За— 1), их следовало бы считать позиционными вариантами одной фонемы, что сильно противоречит нашему интуитивному представлению. Еще более поразительным является тот факт, что любое число (фактов, высказываний, людей) всегда оказывается возможным представить в виде двоичного числа. Из этого следует, что условие (3 а—1) может быть выполнено весьма тривиальным способом, который заключается в принятии алфавита, состоящего только из двух символов. Это, однако, можно сделать и не учитывая фонетических фактов. Таким образом, можно прийти к абсурдному заключению о том, что число фонем во всех языках одинаково и равно двум[223].
Для того чтобы преодолеть эти трудности, было предложено считать позиционные варианты одной фонемы «фонетически одинаковыми». К сожалению, такой подход лишь отодвигает разрешение проблемы до следующего этапа, который заключается в ответе на вопрос, что имеется в виду под термином «фонетически одинаковый». По-видимому, это лишь видоизмененная форма другого вопроса, на который до сих пор также нет ответа: что имеется в виду, когда говорят, что два звука одинаковы.
1.33. Рассмотрим теперь, каково то влияние, которое оказывает условие (3 а) на фонологическую запись некоторых речевых фактов[224].
В русском языке звонкостьявляется различительным признаком всех шумных, кроме /с/, /с/ и /х/, которые не имеют звонких соответствий. Эти три шумных согласных всегда бывают глухими, за исключением тех случаев, когда за ними следует звонкий шумный. В таком положении данные согласные озвончаются. Однако в конце слова (это присуще всем русским шумным) они становятся глухими, если следующее слово не начинается со звонкого шумного,— в этом случае они озвончаются. Например, [m’ok l,i] «мок ли?», Hofm’og bi] «мок бы»; [z’ec l,i] «жечь ли», но [z’ej bi] «жечь бы».
Если записать приведенные выше высказывания в фонологической записи, которая бы удовлетворяла как условию (3), так и условию (3 а), то они бы выглядели так: /m’ok 1,і/, /m’og bi/, /z’ec 1,і/, /z’ec bi/[225]. Кроме того, понадобилось бы правило, гласящее, что шумные, которые не имеют звонких соответствий, т. е. /с/, /с/ и /х/, озвончаются в положении перед звонкими шумными. Однако, поскольку это правило справедливо для всех шумных, единственным результатом попытки выполнить условия (3) и (3 а) будет разделение шумных на два класса и установление специального правила. Если опустить условие (За), то четыре высказывания можно записать следующим образом: {m’ok l,i}, {m’ok bi), {2’ec l,i}, {z’ec bi}, а приведенное выше правило будет распространено на все шумные вместо {с}, {с} и {х}. Таким образом, очевидно, что условие (3 а) приводит к значительному усложнению записи.
Традиционные лингвистические описания включали в себя как системы записи, удовлетворяющие только условию (3), так и системы, удовлетворяющие условиям (3) и (3 а). Первые назывались обычно «морфофонемическими» в отличие от вторых, которые носили название «фонеми- ческих»[226]. В лингвистическом описании нельзя обойтись без морфофонемической записи, так как только с ее помощью можно разрешить неоднозначность, возникающую вследствие омонимии. Например, тот факт, что английская фонологическая запись [th*aeks] (tacks «кнопки» и tax «налог») неоднозначна, объясняется обычно морфофоне- мическим различием «фонемически идентичных» высказываний.
Отметим, однако, что для примеров из русского языка, рассмотренных выше, морфофонемическая запись и правило, касающееся дистрибуции звонкости, вполне достаточны для удовлетворительного описания действительных фактов речи. Следовательно, фонемические системы записи составляют некий дополнительный уровень отображения фактов речи, необходимость которого обусловлена лишь стремлением выполнить условие (3 а). Если можно будет опустить условие (3 а), то исчезнет и необходимость в «фонемической» записи.
1.34. Условие (3 а) относится к операциям по существу аналитическим. Аналитические операции подобного рода хорошо известны во всех науках. Количественный и качественный анализ химических соединений, анализ электрических цепей, определение растений и животных, медицинский диагноз могут служить примерами нахождения соответствующих теоретических моделей для различных комплексов наблюдаемых объектов (например, соответственно,— химическая формула, расположение элементов цепи, классификация внутри общей схемы, название болезни). Однако теоретические конструкты, из которых состоят модели, возникающие в результате различных аналитических операций, постулируются внутри отдельных наук без учета операций, при помощи которых эти конструкты абстрагируются из наблюдаемых объектов. Введение теоретических конструктов никогда не основывается на соображениях, связанных с аналитическими операциями.
Так, например, нельзя себе представить, чтобы в химии в отдельный класс выделялись вещества, которые можно определить визуально, в отличие от веществ, которые требуют применения более сложных методов для своего определения. Однако именно в этом заключается смысл условия (3 а), так как оно вводит различие между фонемами и морфофонемами, исходя лишь из того, что фонемы можно определить на основе только акустической информации, а морфофонемы требуют для своего определения дополнительной информации.
Столь серьезное отклонение от обычной научной практики может быть оправдано лишь в том случае, если будет доказано, что отличия фонологии от других наук настолько велики, что они делают такое отклонение необходимым. Однако до сих пор это не было доказано. Наоборот, вполне обычным является стремление подчеркивать внутреннее тождество проблем фонологии и других наук. Отсюда напрашивается вывод о том, что условие (3 а) — это ничем не оправданное усложнение, которому нет места в научном описании языка.
Устранение условия (3 а) не в такой мере идет в разрез с лингвистической традицией, как это может показаться на первый взгляд. Едва ли является случайным тот факт, что в фонологических описаниях Э. Сепира[227] и до некоторой степени JI. Блумфилда [228] условие (За) отсутствует.
1.4. Условие (4): Фонологическое описание должно быть соответствующим образом включено в грамматику языка. Особое внимание следует обратить на фонологическую запись отдельных морфем. Эту запись нужно выбирать так, чтобы получить простые правила всех грамматических операций, в которых могут участвовать морфемы (например, словоизменение и словопроизводство).
В настоящей работе грамматика рассматривается как некий способ идентификации всех предложений языка[229]. Следовательно, ее можно считать распространенным определением термина «предложение в языке L». По своей структуре грамматика напоминает систему постулатов, из которой путем применения определенных правил можно вывести теоремы. Каждое предложение в языке можно считать теоремой системы постулатов, которая составляет грамматику.
Процесс идентификации начинается с символа «Предложение», поскольку именно этот термин подлежит экспликации посредством грамматики.
В процессе идентификации указанный символ транспонируется в различные системы записи, связанные одна с другой посредством определенных правил; на каждом этапе идентификации предложение записывается определенной комбинацией символов (не обязательно их одномерной последовательностью), что является следствием применения правил грамматики. Для того чтобы отграничить отдельные символы друг от друга и соединить их с соседними символами, перед каждым символом и после него стоит специальный знак &. Далее будет показано, что эти знаки играют важную роль в фонологической записи предложения, поскольку некоторые из них в конечном итоге транспонируются в фонологические границы. Последний этап идентификации предложения — это транспонирование абстрактной записи в звук.
Правила транспонирования, которые образуют грамматику, в общем виде могут быть представлены формулой: «заменить х на у при условии z». Однако правила различаются между собой типом записи, которая получается в результате применения каждого из них.
Различия в типах записи являются следствиями ограничений, налагаемых на возможные значения, принимаемые переменными величинами х, у и z. Набор правил, порождающих запись определенного типа, называется лингвистическим уровнем.
Цель применения правил наивысшего уровня, так называемого уровня непосредственно составляющих, заключается в получении древоподобных моделей, отображающих структуру в терминах непосредственно составляющих предложения. Примером такого дерева может служить представленная на стр. 309 частичная структура русского предложения в терминах непосредственно составляющих.
Структура предложения в терминах непосредственно составляющих считается полностью идентифицированной, когда, применяя перечисленные правила, ни один из символов нельзя заменить другим (например, символ & Присубстантивная группа & не может быть заменен никаким другим символом из перечисленных выше правил).
Эти «незаменяемые» символы называются терминальными символами, а последовательность таких символов называется терминальной цепочкой. Однако, поскольку в действующей грамматике правил гораздо больше, чем в нашем примере, «незаменяемые» символы в нем не являются в действительности терминальными символами правил грамматики непосредственно составляющих русского языка.
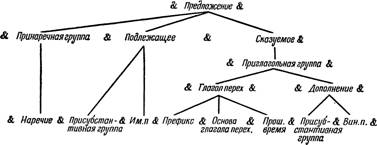
Правила, порождающие это дерево, следующие:
Замени & Предложение & на & Принаречную & Подлежа- & Ска-
группу щее зуемое&
~(1)
„ & Принаречную & на & Наречие & —(2)
группу
„ & Подлежащее & на & Присубстан- & Им. п. & — (3)
тивную
группу
„ & Сказуемое & на & Приглаголь- & —(4)
ную группу
„ & Приглаголь- & на & Глагол перех. & Дополне- & —(5)
ную группу ние
„ & Глагол перех. & на & Префикс & Основа & Прош.
глагола время & перех. — (6)
„ & Дополнение & на & Присубстан- & Вин. п. & — (7)
тивную
группу
Различные точки разветвления дерева соответствуют различным непосредственно составляющим предложения[230]. Следовательно, дерево отображает структуру предложения
по его непосредственно составляющим, а правила грамматики непосредственно составляющих являются формальным аналогом анализа по непосредственно составляющим. Для того чтобы правила порождали деревья такого типа, необходимо ограничить их так, чтобы одно правило не могло заменить более одного символа. Это ограничение предусматривает также обязательное нахождение дерева синтаксической структуры для каждой терминальной цепочки. Кроме того, становится возможным выбрать совершенно однозначный путь от начального символа & Предложение & к любому другому символу (непосредственно составляющему) дерева. Этот путь называется дерива- ционной историей символа.
Далее, к деревьям применяются правила трансформационного уровня. На трансформационном уровне одно правило может заменять более чем один символ. Это позволяет производить в записи такие изменения, которые не могли бы иметь места при применении правил грамматики непосредственно составляющих. Например, можно менять порядок символов в последовательности или исключать некоторые символы вообще. Кроме того, правила трансформации учитывают деривационную историю отдельных символов. Поэтому становится возможным, например, сформулировать различные правила для порождения символа & Присубстантивная группа & из символа & Подлежащее &, с одной стороны, и для порождения того же символа & Присубстантивная группа & из символа & Дополнение &, с другой стороны. Считается (вследствие привлечения деривационной истории отдельных символов), что правила трансформации применяются к деревьям структуры непосредственно составляющих, а не к терминальным цепочкам.
Последний набор правил, так называемые фонологические правила, предусматривает операции над трансформированными терминальными цепочками, состоящими исключительно из особых видов сегментов и границ. Операции заключаются в окончательном приписывании сегментам фонетических признаков.
В отличие от правил грамматики непосредственно составляющих одно фонологическое правило может заменять более одного символа. Однако фонологические правила не учитывают деривационную историю символов, над которыми производятся операции.
1. 41. Вплоть до настоящего момента мы записывали предложения только символами, представляющими определенный класс морфем, например: & Подлежащее &, & Наречие &, & Им. п. & и т. д. Очевидно, на какой-то стадии процесса определения предложения эти символы классов морфем должны быть заменены действительными морфемами; например, символ & Наречие & должен быть заменен тем или иным наречием русского языка. Эта замена может производиться на уровне і непосредственно составляющих, который осуществляется при применении правил типа:
на
А
В
Сит. д.1'
„заменить & Наречие &
»» »
где А, В, С обозначают соответствующие русские наречия например, такие, как там, быстро, вчера и т. д. Правила подобного типа составляют словарь языка.
Выбор некоторых морфем обусловлен контекстом, в котором они встречаются. Например, в русском языке существует тесная связь между фонологическим составом морфемы, заменяющей символ & Основа глагола &, и выбором суффикса настоящего времени.
В принципе возможен спор о том, что в данном случае является определяемым, а что —определяющим. Однако во всех случаях, которые мне приходилось изучать, соображения элементарной экономии требуют, чтобы выбор суффикса зависел от выбора основы, а не наоборот[231].
Подобные соображения всегда лежали в основе лингвистических описаний и были полезными при установлении различий между лексическими и грамматическими морфемами [232]. В настоящей работе не представляется возможным углубляться в вопрос о том, какие классы морфем являются лексическими, а какие грамматическими. Для наших целей достаточно установить, что подобное различение необходимо и что лексические морфемы должны вводиться в фонологическую запись раньше, чем грамматические морфемы.
1.42. Рассмотрим теперь, как вводятся в фонологическую запись отдельные грамматические морфемы. Применение правил грамматики непосредственно составляющих, которые до настоящего момента вполне удовлетворяли нашим целям, приводит в ряде случаев к возникновению трудностей. Рассмотрим эти случаи. В русском языке бывает, что & Существительное & является омофоном & Прилагательного &; например, {s, Чп,} «синь» как & Существительное & и {s,’in,} «синь» как & Прилагательное & в значении «синий». Более того, как & Существительное &, так и & Прилагательное & употребляются перед грамматическими морфемами одного и того же класса, например перед & Мн. ч. & Им. п. &. Следовательно, по правилам грамматики непосредственно составляющих и & Прилагательное &Мн.ч. & Им. п. & и & Существительное & Мн. ч. &, Им. п. &[233] должны дать & {s,’in,} & Мн. ч. & Им. п. &. Здесь возникает существенная трудность: &Мн. ч. & Им. п. & передается разными суффиксами в зависимости от того, за чем оно следует, т. е. стоит ли оно после & Существительного & или после & Прилагательного &. Однако, согласно правилам грамматики непосредственно составляющих, к данной последовательности символов нельзя применять операции, зависящие от деривационной истории символов. Поэтому невозможно транспонировать последовательность & {s,4n,} & Мн. ч. & Им. п. & в две записи, т. е. в {s’,in, -і} «сини» в случае & Существительного & и {s,*in,-iji} «синие» в случае & Прилагательного &.
Выйти из этого затруднения можно, по-видимому, путем установления дополнительных правил грамматики непосредственно составляющих типа:
Заменить & Прилагательное & Мн. ч. & Им. п. & на & Прилагательное & Мн. ч. & Им. п.прилаг. &
Заменить & Существительное & Мн. ч. & Им. п. & на & Существительное & Мн. Ч. & Им. п. существ. &.
Приведенные правила устраняют неоднозначность, содержащуюся в ограничениях, действующих на уровне непосредственно составляющих. Однако за это приходится слишком дорого платить: возрастает число классов грамматических морфем. Вместо того чтобы иметь дело с одним классом грамматических морфем & Им. п. &, приходится разбивать его на более мелкие классы, причем число этих классов будет очень большим, так как омофония наблюдается не только между & Существительным & и & Прилагательным &, но и между другими классами.
Наряду с трудностями, возникающими на уровне непосредственно составляющих в связи с тем, что несколько суффиксов соответствуют одному классу грамматических морфем, приходится встречаться и с трудностями другого рода, возникающими в связи с весьма распространенным явлением «синкретизма»[234]. В лингвистике термин «синкретизм» обозначает явление, при котором один символ выражает несколько грамматических категорий, например падежные окончания существительных в русском языке одновременно с падежом обычно указывают на число или род. Однако правила на уровне непосредственно составляющих весьма строгим образом требуют, чтобы одно правило осуществляло замену не более одного символа.
Следовательно, на этом уровне невозможно применить правило типа: «заменить & Мн. ч. & Им. п. & на & {і} &», где сразу производится замена двух символов— &Мнч. & и & Им. п. &. В итоге, можно сказать, что морфологический процесс словоизменения не может быть включен в правила грамматики непосредственно составляющих.
Естественным разрешением указанных трудностей является включение морфологии (т. е. той части грамматики, которая рассматривает замену символов целых классов грамматических морфем отдельными грамматическими морфемами) в трансформационный уровень, на котором два ограничения, упоминавшиеся выше, теряют свою силу. Такое решение представляется особенно целесообразным, ибо оно совпадает с традиционным способом изучения процессов морфологии, при котором над различными
индивидуальными морфемами производятся различные
операции в зависимости от того, к какому классу эти морфемы принадлежат. В традиционных описаниях замена нескольких символов одним правилом является обычной.
1.5. Как уже было отмечено в § 1. 41, уровень непосредственно составляющих должен содержать правила типа:
Заменить & Наречие & на там (8а)
Заменить & Наречие & на вчера (86)
Заменить & Наречие & на так (8с) и т. д.,
т. е. списки морфем. Однако при научном описании языка нельзя удовлетвориться составлением списков всех существующих морфем. Как синтаксис языка гораздо сложнее исчерпывающего перечня всех предложений, так и фонологическое описание языка не является простым спибком морфем. Фонологическое описание должно включать изложение структурных принципов, в качестве частных случаев которых выступают действительные морфемы.
Процесс порождения данного предложения предусматривает выбор конкретных морфем, составляющих предложение, из целого ряда возможных вариантов, т. е. из списков, подобных правилам (8а) — (8с). Выбор тех или иных морфем осуществляется на основе внеграмматических критериев. Грамматика должна предусматривать правила выбора одной морфемы из списка, причем эти правила привносятся в грамматику извне (возможно, самим говорящим). Правила должны быть даны в форме «выбрать правило (8а)», и грамматика интерпретирует их как команду заменить символ & Наречие & на там.
Вместо того чтобы записывать правила произвольным числовым кодом, который не содержит никакой информации о фонической структуре морфем, можно использовать для этой цели запись морфем непосредственно в терминах различительных признаков, что гораздо больше соответствует целям лингвистического описания. Так, например, вместо команды «выбрать правило (8а)» грамматике может быть задана следующая команда: «заменить & Наречие & на последовательность сегментов, в которой первый сегмент содержит следующие различительные признаки: невокальность, консонантность, некомпактность, высокую тональность, ненапряженность, неназальность и т. д.; второй сегмент содержит различительные признаки: вокальность, неконсонантность, недиффузность, компактность и т. д., а третий сегмент содержит различительные признаки: невокальность, консонантность, некомпактность, низкую тональность, ненапряженность, назаль- ность и т. д.»
Подобные команды удобно представить в виде матриц, в которых каждая вертикальная колонка содержит один сегмент, а в каждом из горизонтальных рядов расположен один различительный признак. Поскольку признаки бинарны, знак (+) означает, что данный сегмент обладает данным различительным признаком, а знак (—) означает, что данный различительный признак отсутствует. Подобная запись показана в табл. 1—1 (см. стр. 321).
Поскольку цель команд — выбрать одну морфему из списка,— важную роль в командах будут играть различительные признаки и их комплексы, служащие для различения морфем. Различительные признаки такого типа и их комплексы называются фонемическими. Признаки и комплексы признаков, распределенные в соответствии с общим правилом языка и, следовательно, не могущие служить для отличия морфем друг от друга, называются нефонемическими.
Каждый фонемический признак в сегменте обозначает какую-то информацию, привнесенную извне. Если грамматика в том понимании, как это изложено в настоящей работе, отражает действительное функционирование языка, то можно считать, что команды выбора отдельных морфем выполняются сознательным усилием со стороны говорящего в отличие от выполнения различных обязательных правил языка, которым говорящий на данном языке подчиняется автоматически. Поскольку мы говорим довольно быстро, иногда со скоростью идентификации до 30 сегментов в секунду, разумно предположить, что все языки построены так, чтобы число различительных признаков, идентифицируемых при выборе отдельных морфем, не превышало некоторой минимальной величины. Это предположение выражено в следующем формальном требовании:
Условие (5). Число идентифицируемых различительных признаков, используемых в фонологической записи, не должно превышать некоторой минимальной величины, необходимой для выполнения условий (3) и (4).
В ходе дальнейшего изложения мы будем оперировать и с нефонемическими признаками, которые остаются не- идентифицируемыми в фонологической записи. Такие не- идентифицируемые признаки будут условно обозначаться нулями на соответствующем месте матрицы [235]. Нули являются вспомогательными символами, применяемыми лишь для удобства изложения; они не несут никакой функции в фонологической системе языка.
1.51. Некоторые признаки являются нефонемическими потому, что их можно предсказать, исходя из каких-то других признаков того же сегмента. Так, например, в русском языке признак «диффузность — недиффузность» является нефонемическим по отношению ко всем звукам, кроме гласных, т. е. можно предсказать дистрибуцию этого признака во всех сегментах, которые являются невокалическими и (или) консонантными. Подобным же образом в сегменте {с} можно предсказать признак «палатализация» во всех случаях независимо от контекста.
Кроме случаев нефонемичности признаков, не зависящей от контекста, во всех языках известны случаи нефонемичности отдельных признаков из отдельных сегментов, входящих в особые контексты. Поскольку применение условия (5) не ограничивается отдельными сегментами, признак должен оставаться неидентифицированным в фонологической записи, если он является нефонемическим вследствие употребления в особом контексте. Подобные контекстуальные ограничения называются дистрибутивными ограничениями. Следовательно, при помощи условия (5) дистрибутивные ограничения вводятся в качестве составной части в грамматику языка. Это — большое достижение настоящей дескриптивной схемы, поскольку изучение и описание дистрибутивных ограничений представляло значительные трудности в лингвистической теории.
Следующие примеры иллюстрируют место дистрибутивных ограничений в настоящей теории.
Пример 1. Хотя сочетания двух гласных весьма обычны на стыке морфем, внутри морфемы в русском языке допускаются только два сочетания гласных {*/ *и\ или {*а*и), например {pa’uk} «паук», jkl/auz+a} «кляуза», {t,i’iinj «тиун». Таким образом, если известно, что последовательность сегментов внутри морфемы состоит из двух гласных, нам будут известны заранее и все различительные признаки второй гласной, кроме ударности, и все различительные признаки первой гласной, кроме диффузности и ударности. Поэтому в словарной записи лексической морфемы, содержащей такую последовательность, необходимо указать только признаки вокальность — невокальность, консонантность — неконсонантность, ударность — неудзрность, а для первой гласной также диффузность — недиффузность. Все другие признаки могут быть однозначно предсказаны; следовательно, согласно условию (5), они должны оставаться неидентифи-
| например: | {*’а | *и} |
| Вокальность | + | — |
| Консонантность | — | — |
| Диффузность | — | 0 |
| Компактность | 0 | 0 |
| Низкая тональность | 0 | 0 |
| Ударность | + | 0 |
Пример 2. Внутри морфемы признак звонкости не является различительным перед шумными согласными, за исключением {*у}, за которым следует гласный или сонорный, т. е. носовой согласный, плавный, или глайд. Звонкость или незвонкость последовательности шумных однозначно определяется последним шумным этой последовательности. Если этот шумный—звонкий, то остальные шумные также являются звонкими, если же он глухой, то остальные шумные, соответственно, глухие. Значит, в таких последовательностях признак звонкости является неопределяемым для всех шумных, кроме последнего.
{*р *s *k) звонкость 00 —
1.512. Случаи, когда признак может быть предсказан, исходя из грамматического контекста, а не из чисто фонологических факторов, строго говоря, не относятся к дистрибутивным ограничениям. Например, в русском языке есть существительные, одни формы которых характеризуются наличием ударных гласных, а другие — наличием безударных гласных. Например, у существительного {v*al\ «вал» во всех формах единственного числа ударение падает на гласную корня, а во всех формах множественного числа — на падежные окончания.
Таким образом, записывая лексическую морфему {v*al\ в словаре, совершенно неправильно указывать, что гласная корня является ударной. Столь же неправильным будет и указание, что гласная корня безударна. Собственно говоря, признак ударности не может быть определен до тех пор, пока не известен грамматический контекст, в котором употребляется {v*al\. Однако, как только этот контекст станет нзеєстньім, ударение будет приписываться автоматически, согласно правилам склонения существительных. Поскольку в этом случае признак ударности может быть предсказан, исходя из других символов, которые так или иначе должны присутствовать в записи, условие (5) требует, чтобы этот признак был не- идентифици ру емым.
В тех случаях, когда признак выводится лишь из определенных грамматических контекстов, необходимо прибегнуть к другой процедуре описания. Так, например, в русском языке появление признака звонкости в шумных согласных на конце слова зависит от того, каким является шумный — звонким (кроме—{*£>}) или глухим. Согласно этому правилу, можно предсказать признак звонкости в последнем сегменте слова {r*og} «рог» в именительном падеже единственного числа и в винительном падеже единственного числа, но не в других падежах. Следовательно, при записи этой лексической морфемы необходимо указывать признак звонкости последнего шумного согласного.
1.52. В русском языке существует ряд основ, формы которых могут иметь беглую гласную. Везде, где эти'чередования не могут быть предсказаны, исходя из других (т. е. грамматических или фонологических) факторов, их следует указать при записи морфемы в словарь. Это делается при помощи символа, который вставляется на то место слова, где появляется беглая гласная, например: jt’ur#k) «турок», но (p’arkj- «парк»; ср. соответствующие формы им. п. ед. ч. {t’urok} и {p’ark} и род. п. ед. ч. {t’urk+a) и (p’ark+a).
Клагстад показал, что, за немногими исключениями, которые можно выделить в отдельный список, гласные признаки # можно определять из контекста[236]. Следовательно, # можно охарактеризовать признаками вокальности и неконсонантности; вместо других признаков будут стоять нули, т. е. # —это гласная без указания различительных признаков гласных.
Итак, лексические морфемы записываются в словаре в виде двухмерных таблиц (матриц), в которых вертикальные ряды соответствуют сегментам, а горизонтальные — различительным признакам. Поскольку все признаки бинарны, они идентифицируются плюсом или минусом. Везде, где признак может быть предсказан из контекста, это находит свое отражение в записи — соответствующие места в матрице остаются неидентифицируемыми. В таблице I—1 показана подобная запись предложения, анализ которого на уровне непосредственно составляющих был приведен в § 1.4[237].
1.53. Теперь необходимо более детально изучить типы сегментов, которые могут включаться в матрицы, отображающие различные морфемы. Определим следующее отношение порядка между типами сегментов: будем считать, что тип сегмента {Л) отличается от типа сегмента {В} тогда и только тогда, когда по крайней мере один признак, являющийся фонемическим в обоих типах, имеет в {Л} значение, отличное от {5}, т. е. плюс в {Л} и минус в {В}, или наоборот.
Примеры:
{Л} {В} {С}
Признак 1 + — + {Л} „не отличается
от“ {С}
Признак 20 + —
(-41 W {С}
Признак 1 + — — Все три типа сегмен-
тов „различны":
Признак 20 +
Набор всех типов сегментов, которые встречаются в матрицах и представляют собой морфемы языка, называется набором полностью идентифицируемых морфонем. Поскольку полностью идентифицируемые морфонемы служат для отличия одной морфемы от другой, они являются аналогами «фонем» и «морфофонем» в других лингвистических теориях. Полностью идентифицируемые морфонемы мы будем записывать прямыми буквами в фигурных скобках ({}).
Подобно другим типам сегментов, которые встречаются в фонологической записи, полностью идентифицируемые морфонемы подчиняются условию (5), требующему, чтобы число идентифицируемых признаков было минимальным [238]. Можно показать, что наложение подобного ограничения на набор полностью идентифицируемых морфем равноценно требованию, чтобы матрица, состоящая из набора полностью идентифицируемых морфонем, была представлена в виде дерева. И если каждая точка разветвления соответствует определенному признаку, а две ветви, отходящие от каждой точки, представляют значения плюс и минус, принимаемые признаком, то путь от начальной точки до терминальной точки дерева будет однозначно определять полностью идентифицируемую морфонему. Поскольку такая диаграмма учитывает только фонемические,
Т абл. I — 1. Запись предложения, приведенного в § 1.4, пссле тсго как прсизведен выбор лексических морфем*
т. е. идентифицируемые, признаки, то полностью идентифицируемые морфонемы однозначно определяются плюсами и минусами, без учета неидентифицируемых признаков.
Возможность изображения матрицы различительных признаков в виде дерева указывает на наличие в матрице по меньшей мере одного признака, идентифицируемого во всех сегментах. Этот признак соответствует первой точке разветвления и делит все типы сегментов на два класса. Каждая из следующих двух точек разветвления соответствует признаку, идентифицируемому во всех сегментах одного из двух подклассов. Эти признаки могут совпадать или быть различными. Таким образом, все типы сегментов делятся уже на четыре подкласса, с каждым из которых можно снова проделать вышеописанную операцию и т. д. Если подкласс содержит всего один тип сегментов, этот тип является полностью идентифицируемым, и путь вдоль дерева описывает состав различительных признаков этого типа сегментов.
Таким образом, представление матрицы в виде дерева равносильно установлению определенной иерархии признаков. Однако такая иерархия может быть и неполной. Например, если в фонологической системе (см. табл. I—3) два признака являются полностью идентифицируемыми, то любой порядок расположения этих признаков будет удовлетворительным. Ниже разбирается ряд примеров, из которых предпоследний иллюстрирует частичное упорядочение признаков по различным критериям. Существование иерархии признаков подтверждает наше интуитивное представление о том, что не все признаки имеют одинаковый вес в данной фонологической системе, например различение гласных и согласных является для различных фонологических систем более фундаментальным, чем различение носовых и неносовых гласных или звонких и глухих согласных.
Нижеследующие примеры изображают матрицы в виде древовидных диаграмм. При одних условиях матрицы можно представить в виде дерева, при других нельзя. Ниже разбираются те и другие условия.
Матрицы некоторых типов сегментов невозможно представить в виде дерева. Например, изображенная ниже матрица не может быть преобразована в дерево, поскольку в ней отсутствует полностью идентифицируемый признак (т. е. признак, не принимающий значение «нуль»).
В левой части дерева, получившегося из этой матрицы, признак 2 предшествует признаку 3, а в правой части — признак 3 предшествует признаку 2.
Мне не удалось установить, встречаются ли подобные случаи в естественных языках.
Ввиду того, что упорядочение признаков является свободным, из одной матрицы можно получить несколько деревьев, отвечающих указанным выше требованиям.
В таком случае при выборе одного из этих деревьев можно руководствоваться условием (5), которое отдает предпочтение дереву более симметричной формы. Для иллюстрации приведем пример из частной системы (сходной с фонологической системой русского языка), где возможны различные модели:
Очевидно, вторая модель является более экономной, так как она содержит больше нулей, что находит свое отражение в большей симметричности второго дерева.
На рис. I—1 фонологическая система языка представлена в виде «дерева». Различные пути вдоль дерева от первой точки разветвления до терминальных точек определяют различные полностью идентифицируемые морфонемы.
Ниже будет показано, что типы сегментов, определяемые путями, начинающимися от первой точки разветвления и заканчивающимися на промежуточных точках, т. е. типы сегментов, «не отличающиеся» от нескольких полностью идентифицируемых морфонем, играют важную роль в функционировании языка. Такие типы сегментов мы будем называть не полностью идентифицируемыми морфонемами и обозначать звездочками при соотвествующих полностью идентифицируемых морфонемах. Необходимо отметить, что признак, идентифицируемый в полностью идентифицируемой морфонеме, может не идентифицироваться в неполностью идентифицируемой морфонеме лишь в том случае, если все признаки, располагающиеся в иерархии дерева ниже данного, будут также неиденти- фицируемыми.
1.54. Из условия (5) вытекает, что только фонемические признаки идентифицируются в фонологической записи. Однако в реальном высказывании не может быть неиден- тифицируемых признаков.
Языки отличаются один от другого тем, какое положение в них занимают иефоиемические признаки. Для некоторых нефонемических признаков существуют определенные правила их фонетической реализации, для других таких правил нет, и их реализация в каждом конкретном случае зависит от говорящего. Именно это различие лежит в основе противопоставления так называемых аллофонов и свободных вариантов фонем.
Нефонемические признаки как свободные варианты нельзя должным образом включить в лингвистическое описание. С точки зрения такого описания интерес представляет только то, что они являются свободными вариантами. Однако эта информация может быть передана и просто путем опущения всякого упоминания об интересующих нас признаках. Таким образом, если в дальнейшем описании не будет содержаться никаких сведений о реализации некоторого признака в определенном контексте, это будет означать, что данный признак является свободным вариантом.
1.55. Правила грамматики составляют некоторую частично упорядоченную систему. Поэтому представляется вполне уместным исследовать, какое место в этой иерархии принадлежит правилам, определяющим нефонеми- ческую дистрибуцию признаков. В настоящей работе такие правила будут называть «F-правилами». Напомним, что на уровне непосредственно составляющих символы лексических морфем заменяются последовательностями сегментов, состоящих из различительных признаков (матриц). Однако на этом уровне символы классов грамматических морфем остаются в записи неизменяемыми (см. табл. I—1). Только после применения трансформационных правил словоизменения и словопроизводства символы классов грамматических морфем (например, «Прошедшее время», «Единственное число» и т. д.) будут заменены их фонологическими последовательностями, которые из них выводятся. Поскольку трансформационные правила вводят в запись дополнительные сегменты, состоящие из различительных признаков, а также изменяют ранее введенные сегменты, расположение F-правил перед трансформациями может повлечь за собой применение некоторых правил дважды: первый раз перед последними трансформационными правилами и второй раз после последнего трансформационного правила. Так, например, согласно трансформационным правилам склонения существительных в русском языке, & {іь'ап} & Ед. ч. & Дат. п. & заменяется на {iv'anu). Если правила, согласно которым безударным гласным приписываются нефонемические признаки, применены до этой трансформации, то эти же правила необходимо будет применить снова во время трансформации или идентифицировать все нефонемические признаки в {«) каким-либо другим путем. Поэтому, видимо, наиболее целесообразно поместить все правила, управляющие дистрибуцией нефонемических признаков, после трансформационных правил. Однако по ряду причин желательно, чтобы некоторые F-правила применялись до трансформаций, даже если это и влечет за собой трудности, описанные выше.
Для русского языка, так же как и для многих других языков, справедливо положение, может быть, и не являющееся всеобщим, согласно которому для правильного функционирования некоторых трансформационных правил, особенно правил словоизменения и словопроизводства, необходимо, чтобы определенные признаки были идентифицированы в записи вне зависимости от того, являются ли эти признаки фонемическими.
Так, например, для правильного применения правил русского спряжения необходима информация о том, окаи- 326 чивается ли глагольная основа на гласный звук[239]. В третьем сегменте основы глагола [rv'a] «рва-ть» признаки «вокальность — невокальность» и «консонантность — неконсонантность» являются нефонемическими, так как в русском языке в морфемах, начинающихся с последовательности сегментов, из которых первый — плавный, а второй — согласный, третий сегмент обязательно должен быть гласным (см. § 2.161, правила морфологической структуры; правило 1с). Таким образом, согласно условию (5), фонологическая запись рассматриваемой морфемы должна выглядеть следующим образом:
rv'a
вокальность — невокальность + — О
консонантность — неконсонантность + + О
Однако, поскольку различительные признаки третьего сегмента остаются неидентифицируемыми, нельзя установить, является ли этот сегмент гласным. Следовательно, определить правильное спряжение этой глагольной основы невозможно. Однако, если F-правило, согласно которому данные нефонемические признаки идентифицируются (правило морфологической структуры 1с), применить до трансформации, то указанные трудности легко устраняются. Поскольку этот пример не является исключением, мы пришли к тому выводу, что по крайней мере некоторые F-правила должны применяться до трансформационных правил вне зависимости от трудностей, которые при этом возникают.
1.56. Соображения, рассмотренные выше, привели нас к выводу о необходимости разделения всех F-правил на две группы. В одну группу входят правила морфологической структуры (MS-правила), которые должны применяться до трансформаций, в другую группу входят фонологические правила (P-правила), применяемые после трансформаций. Естественно возникает вопрос о том, как установить, какие F-правила входят в группу MS-npa- вил, а какие — в группу P-правил. Для русского языка вполне удовлетворительным является следующий критерий [240].
Правила морфологической структуры должны обеспечивать, чтобы все сегменты, появляющиеся в записи,были либо полностью, либо не полностью идентифицируемыми морфонемами.
Другими словами, набор типов сегментов, получающихся после применения правил морфологической структуры, определяется всеми возможными путями вдоль дерева, начиная от первой точки разветвления. Как было отмечено в § 1.53, это ограничивает число признаков, которые могут оставаться неидентифицируемыми: некоторые не- фонемические признаки должны быть идентифицированы именно теперь. Этот результат как раз и является желаемым, поскольку, как это было показано в предыдущем разделе, если в этом месте не ввести некоторого ограничения числа неидентифицируемых признаков, невозможно будет правильно применить трансформационные правила словоизменения и словопроизводства.
Необходимо отметить, что не полностью идентифицируемые морфонемы по терминологии пражской школы являются аналогами «архифонем»[241]. Хотя Трубецкой определил «архифонемы» как «совокупность смыслоразличительных признаков, общих для двух фонем» [242], в своей лингвистической практике он оперировал «архифонемами», в которых более чем один признак был нейтрализованным (неидентифицируемым); см. его «Das mor- phonologische System der russischen Sprache».
Добавим к этому, что правила морфологической структуры предусматривают применение трансформационных правил морфологии русского языка к не полностью идентифицируемым морфонемам, которые в основном идентичны «архифонемам», постулируемым Трубецким в его работе, упомянутой выше.
1.57. Необходимость разделения F-правил на две группы и применения MS-правил перед трансформациями становится еще более очевидной по той причине, что во многих языках наблюдаются существенные различия между огра* ничениями, налагаемыми на последовательности сегментов внутри отдельных морфем, и ограничениями, налагаемыми на последовательности сегментов вообще, без учета деления их на морфемы. Так, например, в русском языке внутри отдельных морфем допускаются лишь очень немногие последовательности гласных, тогда как на стыках морфем практически возможны любые сочетания двух гласных. Другими словами, в сочетаниях гласных внутри морфем многие признаки являются нефонемическими и поэтому должны оставаться неидентифицируемыми в записи.
Многие правила, идентифицирующие эти нефонемические признаки, могут применяться только в том случае, если отдельные морфемы отграничены друг от друга. Однако при трансформациях возможна перегруппировка символов таким образом, что отдельные морфемы уже не будут отграничиваться. Примером этого может служить упоминавшееся выше явление «синкретизма». Другим примером являются так называемые «прерванные морфемы», особенно характерные для семитских языков. «Прерванные морфемы» встречаются и во многих индоевропейских языках, включая русский. Например, в прилагательном среднего рода {p’ust+o} «пусто» признак «Средний род» выражен тем, что ударение падает на основу, и окончанием {-fo}. Поскольку при трансформациях отграничение морфем может исчезать, F-правила, требующие для своего применения информации о начале и о конце морфемы, должны применяться до трансформаций.
1.58. После применения правил морфологической структуры все сегменты, появляющиеся в записи, представляют собой либо полностью, либо не полностью идентифицируемые морфонемы. Поскольку морфонемы однозначно определяются различными путями на дереве, представляющем фонологическую систему языка, становится возможным заменить матрицы, с помощью которых записываются различные лексические морфемы, линейными последовательностями плюсов и минусов при условии, что специальный символ (в нашем случае звездочка) будет обозначать место, где заканчивается идентификация не полностью идентифицируемых морфонем. Для обозначения окончания идентификации полностью идентифицируемых морфонем никакого символа не требуется, так как это определяется автоматически. В нижеследующем примере для облегчения чтения в таких местах вводится пробел. Однако в отличие от звездочки пробел является избыточным символом и его нельзя вносить в запись.
После применения правил морфологической структуры предложение, представленное на табл. I—1, может быть записано следующим образом:
Значение знаков + и— в этой записи должно быть установлено с помощью дерева, изображающего фонологическую систему русского языка (см. рис. I—1). Плюсы и минусы представляют собой команды, приказывающие просматривать дерево сверху вниз, начиная всегда с первой точки разветвления. При этом плюсы указывают на необходимость выбора правой ветви, а минусы — на необходимость выбора левой ветви. После выбора терминальной точки дерева или точки, обозначенной в записи звездочкой, процесс начинается снова, с первой точки разветвления. Данная процедура позволяет нам установить, например, что первый сегмент записи, приведенной выше, является не полностью идентифицируемой морфонемой, определяемой различительными признаками «невокальность, консонантность, некомпактность, низкая тональность, напряженность».
1.581. Важное следствие вытекает из включении в запись не полностью идентифицируемых морфонем. Рао-
смотрим существительное {*/*es} «лес»81, у которого во множественном числе и во II-м местном падеже единственного числа ударение падает на падежные окончания, а во всех других падежах единственного числа — на гласную основы. В свете изложенного в § 1.512 форма родительного падежа единственного числа будет записываться как {*l’es+a}, а форма именительного падежа множественного числа — как {*les+’a}. Однако, поскольку {*les+’a} и {l,is+’a} «лиса» (как и безударные {е} и {1} во всех случаях) являются омофонами, необходимо добавить правило, которое содержало бы утверждение, что безударное {е} переходит в [і], или другое подобное утверждение в терминах различительных признаков. Однако таким образом мы включаем безударное {е} (а также безударное {о}) в фонологическую систему языка, хотя эти комплексы различительных признаков не применяются для различения высказываний. Это является прямым нарушением условия (За—I)[243], которое специально оговаривает невозможность такого шага. Поскольку условие (За—1) было отвергнуто нами в качестве требования, предъявляемого к фонологической записи, такое нарушение является вполне оправданным. Однако необходимо отметить, что существует альтернатива нарушению условия. (За—1), заключающаяся в установлении нескольких записей для всех лексических морфем, содержащих гласный звук {*е}. Так, например, в этом случае {*l*es} надо было бы записывать в виде /1,’es/ и /l,is-/, что, несомненно, нежелательным образом усложняет запись.
1. 6. Выше, в § 1. 42, отмечалось, что после применения трансформационных правил, включающих правила словопроизводства и словоизменения, запись предложения будет состоять только из фонологических символов, т. е. морфонем и границ. Символы классов грамматических морфем будут заменены фонологическими последовательностями, которые из них выводятся, а символ # (гласный, чередующийся с нулем) будет либо представлен гласным, либо исключен из записи. В результате неидентифицированным остается только символ &.
Условие (6): Символы &, согласно правилам морфологии, транспонируются в фонологические границы или исключаются из записи.
Точное описание процесса транспонирования является частью морфологии языка и поэтому не может быть здесь приведено в деталях. В настоящем исследовании мы лишь перечислим все виды границ и все контексты, в которых они встречаются.
В русском языке существуют границы пяти видов, которые обозначаются следующими символами:
1) Граница фонемической синтагмы обозначается вертикальной чертой |.
2) Граница слова обозначается пробелом или, в случаях, когда может возникнуть неясность, символом %.
3) Границы префиксов и предлогов обозначаются символом =.
4) Перед некоторыми окончаниями ставится специальный символ 4, иногда в тех же случаях, во избежание путаницы, ставится символ §.
5) Границы морфем в сокращениях типа {p’art—b,i* l’et} «партбилет» обозначаются символом — (черточка).
Поскольку символ & транспонируется только в указанные пять видов фонологических границ, все символы &, не соответствующие ни одному из этих видов, устраняются из записи. Если в ходе изложения возникнет необходимость как-то обозначить эти стыки морфем, то с этой целью будет употребляться знак (-) (дефис), не являющийся, однако, символом в фонологической записи.
1.7. Теперь можно продолжить идентификацию предложения, взятого нами в качестве примера. После применения трансформационных правил языка получаем следующую запись:
Это и есть фонологическая запись предложения, поскольку она включает только морфонемы и границы, а все правила, необходимые для транспонирования этой записи в звук, описывают только влияние различных конфигураций различительных признаков и / или границ на отдельные комплексы различительных признаков [244].
Фонологические правила можно сформулировать с таким расчетом, чтобы не нужно было обращаться к деривационной истории морфонем и границ. Для этого необходимо существование строгой очередности в применении правил. Если же правила не будут упорядочены, их структура значительно усложнится, тогда нужно будет обращаться к деривационной истории символов.
В качестве иллюстрации рассмотрим следующий пример. В русском языке все плавные и парные согласные смягчаются перед {*е}. Кроме того, безударное {е} становится диффузным, т. е. [ і]. Проще всего изложить эти факты следующим образом.
Правило А: Перед {*е} плавные и парные согласные смягчаются.
Правило Б: Безударное {е} становится диффузным.
Однако, если применить сначала правило Б, то правило А будет необходимо заменить правилом А':
Правило А': Перед {’е[ и перед [і], которое происходит из {е}, плавные и парные некомпактные согласные смягчаются.
Очевидно, правило А проще, чем правило А'. Однако правило А можно применять лишь в том случае, когда установлен порядок применения правил.
В таблице I—2 показано функционирование фонологических правил русского языка применительно к предложению, взятому нами в качестве примера.
На начальной стадии каждая морфонема записывается в виде набора различительных признаков, которые интерпретируются с помощью дерева (рис. I—1), отображающего
взятому в качестве иллюстрации (См. 1.4 и
фонологическую структуру русского языка. Далее, после применения отдельных фонологических правил морфонемы модифицируются. Поскольку лишь некоторые P-правила нужны в нашем примере, не все эти правила показаны в табл. I—2. Первым применяется правило Р 1 Ь, приписывающее признак звонкости морфонемам, в которых этот признак является неидентифицируемым. Далее применяется правило Р-2. Из таблицы ясно функционирование этого правила. Последующие правила применяются строго в порядке своей нумерации до тех пор, пока список правил не исчерпывается. В результате мы получаем так называемую «узкую» транскрипцию предложения, которую можно непосредственно перевести в звук:
3 1 2 3 3 1 4 2 1 4
| fcira | р,jani-jbrad,ag31Szokcerkaf, |
«Вчера пьяный бродяга сжег церковь». Цифры над символами гласных указывают на степень интенсивности их произнесения (динамическое усиление): 1— наивысшая степень интенсивности, 4 — низшая, степень интенсивности.
В принципе фонологические правила должны были бы применяться до тех пор, пока все различительные признаки всех сегментов не будут идентифицированы, причем эти правила должны также предусматривать описание случаев, когда данный признак является свободным вариантом. Тогда было бы необходимо, например, иметь правило, гласящее, что все сонорные в русском языке всегда являются звонкими (за редкими исключениями типа {o*kt, ’abr,*skoj} «октябрьской», где {г,} часто оглушается). Однако такие правила не включаются в настоящее описа ние. Поскольку часто подобные факты оказываются к тому же спорными, мы решили, что ценность таких дополнительных деталей была бы весьма невелика.
2. Фонологическая система русского языка
При проведении фонологического анализа всегда возникает вопрос, насколько предлагаемая схема анализа учитывает имеющиеся данные. В описании абсолютно невозможно перечислить все фонологические особенности речи даже одного человека, поскольку он может употреблять признаки, характерные для других диалектов и даже иностранных языков (например, человек, говорящий по- русски, может различать носовые и неносовые гласные в некоторых (французских) выражениях, составляющих неотъемлемую часть разговорной лексики этого человека). Если попытаться учесть такие факты, становится очевидным, что систематическое фонологическое описание неосуществимо. Поэтому представляется целесообразным рассматривать такие случаи как отклонения и помещать их в специальные разделы, а основную часть грамматики ограничить теми фактами, которые можно описать систематически. В данном описании рассматривается вариант русского языка, в основном идентичный варианту, описанному в таких общеизвестных работах по русскому языку, как недавно изданные академическая «Грамматика русского языка» и словарь русского литературного произношения под редакцией Р. И. Аванесова и С. И. Ожегова [245].
Так называемый «литературный» вариант русского языка, описанный в этих работах, допускает существование вариантов для некоторых фонологических признаков. В настоящем описании была сделана попытка учесть эти варианты. Интересно отметить, что подобные отклонения оказывают влияние не на фонологическую запись высказываний, а на порядок расположения и содержание фонологических правил, которые транспонируют фонологическую запись в звук.
2.1. Морфонемы. На рис. I—1 представлено дерево, отображающее морфонемы русского языка. Эта схема послужила основой для составления матрицы различительных признаков (табл. I—3). В систему входят 43 морфонемы; они идентифицируются 271 командой, каждая из которых указывает на наличие или отсутствие того или иного различительного признака (+ или—в табл. I—3 или ветви на рис. I—1). Таким образом, на идентификацию одной морфемы затрачивается 6,3 команды. Условие (5) требует, чтобы количество команд, используемых в записи, было минимальным. Для того чтобы уяснить, насколько
Рис. I—1. Схема дерева, отображающего морфонемы русского языка. Цифры, стоящие уточек разветвле- ния, соответствуют следующим различительным признакам: 1. Вокальность — невокальность. 2. Консонантность — неконсонантность. 3. Диффузность — недиффузность. 4. Компактность — некомпактность. 5. Низкая тональность — высокая тональность. 6. Напряженность — ненапряженность. 7. Назальность — неназальность. 8. Непрерывность — прерывность. 9. Звонкость — глухость. 10. Мягкость — твердость. И. Ударность— неударность. Левые ветви соответствуют минусам, правые — плюсам.
полно наша схема удовлетворяет условию (5), можно сравнить приведенную выше цифру с log2 43 = 5,26 (5,26 — это нижний предел, достигаемый при сокращении числа команд до минимума). Необходимо подчеркнуть, что к этому сравне ию надо подходить осторожно: единственной целью в данном случае является показать, что процесс сокращения команд привел к весьма удовлетворительным результатам [246].
Табл. I — 3. Матрицы морфонем русского языка.
Еще по теме 1. Введение. Теория фонологии:
- §5. Краткое введение в проблемы чань-буддизма. Теория «отсутствия мыслей»
- Приложение Теория государства и права.Учебно-методический комплекс для студентов заочной формы обучения Введение
- 2.8. Фонология
- Приложение Теория государства и права.Учебно-методический комплекс для студентов очной и очно-заочной форм обучения Введение
- Таксономическая фонология
- Фонология и фонемика
- Лингвистическая фонетика (фонология).
- Фонология.
- Светлицкий И. С.. Экономическая теория: введение в курс: пособие / И.С. Светлицкий. - Минск: БНТУ,2010. - 72 с., 2010
- Критерии, используемые в системной фонологии
- Фонология
- Фонология
- Фонология
- Фонология
- § 1. Определение фонологии
- Лекция № 9. Фонология
- Модуль 1. «Фонетика. Фонология»
- Модуль 1. «Фонетика.Фонология»