Генетические алгоритмы синтеза нейронных сетей для систем управления
В решении оптимизационных задач комбинаторного типа используют специфические алгоритмы, среди которых выделяются несколько основных методов:
a) Отсечения
b) Комбинаторные
c) Приближенные.
Генетические алгоритмы (ГА) относят - к третьему типу.
Но ГА не могут применяться в чистом виде, им присуще использование специфики задачи, как и различные эвристики локального улучшения, как жадные алгоритмы. Задачи, которые рассматриваются в исследовании -это задачи с ограничениями. Чтобы успешно решить данные задачи при помощи Г нужно использовать методы ухода от ограничений. Данные методы разделяются на три класса:a) прямые,
b) непрямые,
c) отображающие.
Схема ГА представлена на рисунке 1.9.

Рисунок 1.9 - Схема генетического алгоритма
Хорошо зарекомендовали себя в решении различного рода задач оптимизации адаптивные свойства ГА. У ГА имеется свойство неявного параллелизма, что позволяет ему динамически, как отыскивать, так и исследовать области, которые содержат либо локальные, либо глобальные оптимумы. Данные свойства Г позволяют при его работе в динамически изменяющейся среде оптимизировать функционал Q(x).
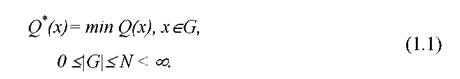
Основная цель задачи дискретной оптимизации - это нахождение из конечного, но достаточно большого числа, лучшего решения. Задача дискретной оптимизации (1.1) сложная, как для классических алгоритмов, так и для ГА, что связано с особенностями задач этого класса.
1. У задач имеется переборный характер, но с ростом параметров задачи перебор становится принципиально невозможным.
2. Эти задачи относятся к нерегулярным и у них может быть несколько оптимумов, в том числе локальных, в которых значение функции не совпадает с глобальным.
3. Кроме этого, возможно, что области допустимых решений несвязны и не выпуклы. Меру близости решений указать затруднительно, так как у «близких» значений x1χ2?Gмогут иметься сколь угодно далеких значений Q(x1)и Q(x2). Чтобы определить близость решения в этих задачах используют различные техники, которые в основном зависят от вида задач.
Чтобы преодолеть эти трудности, предложены различные модификации Г , которые довольно успешно справляются с решением задач такого класса. Одна из этих модификаций - алгоритм генетического программирования (ГП) [28, 41].
В решении нетривиальных задач использование метода автоматического программирования не приводит к успеху, если в нем нет некого иерархического
механизма, учитывающего различные закономерности, симметрии, а также однородности или шаблоны, которые присутствуют в пространстве задач. Таким механизмом в обычных компьютерных программах являются подпрограммы в виде процедур и функций. Эту идею в виде автоматически определяемых функций привнес в ГП Джон Коза. Он показал, что при использовании автоматически определяемых функций существенно повышается эффективность решения задачи методом ГП. Поэтому разумно будет предположить, что функции, которые специфичные в решаемой задаче, будут известны еще до запуска алгоритма ГП и будут включены в функциональное множество. Данные шаги повысят эффективность поисков решений. Данными функциями могут оказаться те функции, которые чаще всего встречаются в популяции. Для определения данных функций используем понятие шаблона.
Шаблоном является функцияf(x1, ..., xn, p1, ..., pm), в которой x1, ..., xn- это независимые аргументы, а p1,..., pmявляются параметрами, вместо которых подставляют произвольные функции g1(x1, ..., xn), ..., gm(x1, ..., xn). Такие, как например: f(x, p) = x + p*sin(p), f(x, x*x) = x + x*x*sin(x*x).
Функция может удовлетворять некоторому шаблону, если в ней будут такие параметры, когда при их подстановке в шаблон может получиться тождественная функция. Шаблон с такими параметрами называют переводом в функцию. К примеру, функцией g(x) = x*x*sin(x*x) удовлетворяется шаблон f(p) = p*sin(p), а fx*x) - перевод fв g.
Шаблон fι доминирует шаблон f2,при условии, что f1и f2различны, а f2 удовлетворяет fl. К примеру: f1(p1, p2) = p1*sin(p2), f2(p) = p*sin(p), где f доминирует значению f2: f2(p) = f1(p, p).
Пересечение функций или шаблонов g1, ..., gnназывают множество шаблонов, которые как F = {f1, .,fm}, :
1. показателем giудовлетворяется fдля всех i, j;
2. нет таких iили j, что fдоминируетfj;
3. нет шаблонаfкоторый бы удовлетворялся giи доминировался бы каким- нибудь шаблоном из F.
Рассмотрим алгоритм поиска шаблонов. Для алгоритма исходная информация - это множество выражений, либо деревьев. На основе данного множества составляем список уникальных поддеревьев, который упорядочен по возрастанию глубины. Например, множество подвыражений: x2+x3, x1*x2, x1*(x2+x3), sin(x2+x3), exp(x1*x2) или множество выражений: x1*(x2+x3), sin(x2+x3), exp(x1*x2)∙
Целью алгоритма является поиск шаблона, который удовлетворяет эти поддеревья. Причём осуществляется поиск в соответствии с такими правилами, как:
1. Каждому шаблону должно удовлетворять хоть бы два подвыражения.
2. Если у f1доминируется f2и нет подвыражения, которым удовлетворяется f1,но не удовлетворяется f2,тоf1нужно отбросить.
В процессе выполнения алгоритма идет перебор в глубину всех сочетаний поддеревьев.
Для каждого из сочетаний находится пересечение поддеревьев, которым и образуются искомые шаблоны. Ниже приведем пример перебора для 4х поддеревьев:
Если каким-либо сочетанием образуется пустое пересечение, то не рассматриваются другие сочетания, «содержащие» это пересечение.
Самый важный этап алгоритма поиска шаблонов -это процесс нахождения пересечений функций, либо поддеревьев. Причем, операции в корневом узле, чтобы пересечение не было пустым, должны быть одинаковыми, т.к. рассматривают поддеревья в порядке возрастания глубины. Поэтому к моменту, когда нужно найти пересечение каких-то поддеревьев, уже должно быть известны те шаблоны, которые одновременно удовлетворят любые пары из дочерних поддеревьев (такое касается поддеревьев глубины от 2 и далее).
Этапы процесса нахождения пересечения функций:
1. Процесс определение комплементарных операндов.
2. Процесс составление всех возможных комбинаций комплементарных операндов.
3. Этап составление шаблона и назначение параметров для всех комбинаций.
4. Процесс по удалению дублирующих шаблонов.
5. Этап по удаление шаблонов, ранее найденных за исключением тех шаблона, которые совпадают с тем шаблоном, который участвует в пересечении.
6. Этап удаления доминирующих шаблонов.
7. Процесс составления переводов в функции полученных шаблонов, участвующих в пересечении.
На 1-ом этапе производят сравнение операндов с учётом их коммутативности, а также ассоциативности операций и определения так называемых комплементарных операндов - операндов, которые имеют одинаковые корневые узлы. Так как в общем случае операнды-функции представляют при помощи разных шаблонов, то требуется найти пересечение данных операндов.
Допускаем, что операнды а и bподдеревьев - это функции, и они удовлетворяют множеству шаблонов F1,а операнд b- F2.В этом случае пересечением а и bбудет подмножество F1∩F2, из которого исключили доминирующие шаблоны.
При ситуации, когда операнд а шаблона - это перевод некого шаблона f, операнд bподдерева - это функция, и он удовлетворяет множеству шаблонов F, F1 - подмножество F, поэтому fудовлетворяет всему объему элементов F1. Тогда пересечением а и bбудет множество F1, из которого исключаются доминирующие шаблоны.
Возможно получение нескольких комбинаций комплементарных операндов при нахождении пересечения операндов. Исходные поддеревья для каждой из комбинаций можно представить в так:
f1 = t1(a11, a12, ...) * t2(b11, b12, ...) * ... * C1 * C2 * ... * d11 * d12* ...
f2 = t1(a21, a22, ...) * t2(b21, b22, ...) * ... * C1 * C2 * ... * d21 * d22 * ...,
где значение t - является шаблонами пересечения операндов, значение C - это переменные, значение d - это некомплементарные операнды.
Основу шаблона составляют комплементарные операнды (tи C), а остальные операнды заменяют параметрами:
f3 = t1(p11, P12, ...) * t2(p21, P22, ∙∙∙) * ∙∙∙ * C1 * C2 * ... * p31 * P32 *∙∙∙
Шаги процесса замены операндов исходных поддеревьев параметрами: Определение уникальных операндов. Например,
1. f = t1(x1, x1)*t2(x1, x1+x2)*x1*(x2+x3)*(x2+x3), f = t1(p1, p1)*t2(p1, P2)*P1*P3*P3 .
2. Сравнение соответствующих операндов шаблону t, например,
R = {(P1,P1), (P1,P2), (P1,P2), (P2,p3)}, T = {(P1,P1), (p2,P1), (p3,p2)},
P = {1, 2, 2, 3}.
3. Сравнение с элементами множества Tпар некомплементарных операндов, полученного на шаге № 2.
4. Назначение параметров операндам, которые не образовали пары на шагах №2 и №3.
аждое из поддеревьев на первом шаге рассматривают по отдельности, производят сравнение аргументов шаблонов, а также других операндов между собой и замену их параметрами. Далее производят аналогичную операцию, но рассматривают уже пары, которые соответствуют аргументам шаблонов. На шаге №3 назначают параметры некомплементарным операндам, чьи пары совпадают с элементами множества, которое полученное на шаге №2. В этом случае возможно создание нескольких вариантов назначения параметров. Сопоставление остальных операндов функций производится на последнем шаге с учётом того, сколько раз они повторяются. Например, если исходные функции: f1=t1(x1,
^1)*^2
Еще по теме Генетические алгоритмы синтеза нейронных сетей для систем управления:
- Вариационный генетический алгоритма для синтеза системы управления с одним критерием оптимизации
- Разработка генетических алгоритмов для синтеза систем управления вертикализацией экзоскелета посредством нейросетевых технологий
- Синтез системы управления вертикализацией экзоскелета методом искусственных нейронных сетей
- Генетический алгоритма для обучения нейронной сети для вертикализации экзоскелета с одним критерием оптимизации
- Генетический алгоритма для обучения нейронной сети для вертикализации экзоскелета с двумя критериями оптимизации
- Макаренко Алексей Александрович. Алгоритмы и программная система классификации полутоновых изображений на основе нейронных сетей: диссертация... кандидата технических наук: 05.13.18. - Москва: РГБ, 2007, 2007
- Структуры нейронных сетей для нейроуправления
- Анализ и оценка состояния проблемы синтеза оптимального управления на базе нейросетевого подхода для биотехнических систем реабилитации
- 2.2 Алгоритм обучения нейронной сети для ускоренной сходимости обучения
- 1.2.7. Генетический алгоритм обучения
- Стадник Алексей Викторович. Использование искусственных нейронных сетей и вейвлет-анализа для повышения эффективности в задачах распознавания и классификации, 2004
- Глава 1. Основы искусственных нейронных сетей
- Синтез нейроконтроллера дляч системы управления вертикализацией экзоскилета
- Математическая модель для синтеза управления вертикализацией экзоскелета
- 3.1 Алгоритм обучения нейронной сети.