Релаксационная методика решения задачи маркировки объекта
Проанализировав выражение (5.13) можно сделать вывод, что на его результат большое влияние оказывают значения априорных вероятностей гипотезы маркировки объектов. Чем более корректно заданы эти вероятности, тем больше шансов найти корректную метку для объекта.
Однако вычисление корректных значений величины априорной вероятности на практике представляет собой трудно решаемую задачу.Для решения указанной проблемы и повышения эффективности вероятностного метода маркировки предлагается решать рассматриваемую задачу итерационным методом. В итерационном методе апостериорные вероятности P(¾ :ЛкI а,г), полученные после первой итерации в выражении (5.13), используются как улучшенные и подкрепленные доказательствами априорные вероятности P(θki: Лк) на следующей итерации. Итерации продолжаются до тех пор, пока не будет удовлетворен критерий сходимости. Критерием сходимости может служить неизменность значений вероятностей гипотез маркировки объектов на следующих друг за другом итерациях.
Подобная методика решения задачи маркировки относит ее к семейству релаксационных алгоритмов, которые на каждой итерации «смягчают» процедуру получения решения на следующей итерации. К релаксационным алгоритмам 251
относится, например, алгоритм Дейкстры для поиска минимальных деревьев в графах, или алгоритмы для решения задач классификации объектов при обработке изображения (к которым, кстати, относится и данная задача).
Вычисление условных вероятностей в выражениях вероятностного метода
Для использования выражений (5.13)—(5.14) необходимо иметь возможность вычислить условные вероятности
Запишем выражения для их вычисления в общем виде.
Условная вероятность совпадения атрибутов а,, объекта с атрибутами метки Лк зависит не только от условия маркировки
с атрибутами метки Лк зависит не только от условия маркировки но и от неко
но и от неко
торой функции Φα, изменяющей значения атрибутов alв зависимости от рассогласования между изображениями.
Согласно аксиоме о вероятности совмещения двух случайных величин получим
где - заданная функция плотности вероятности для функции Φα.
- заданная функция плотности вероятности для функции Φα.
Для ненулевых меток Лк условная вероятность вычис
вычис
ляется как
где Fa(x) - некоторая одномодальная функция плотности вероятности с максимумом в x = 0. В качестве Fa(x)можно взять «-мерную функцию плотности нормального распределения, где « равно размерности вектора атрибутов ai.
Для нулевых меток Л$ условная вероятность выражает
выражает
ся константой
Величина Daможет быть представлена как пороговая вероятность, которая начинает превалировать над вероятностями гипотез маркировки объекта ненулевыми метками при превышении параметра функции Fa(x)в (5.16) определенного максимального значения хтах(см. рис.5.2). Для тех значений параметра х на рис.5.2, где значение первой кривой больше значения второй кривой будет преобладать гипотеза маркировки объекта соответствующей ненулевой меткой. Для остальных значений х более вероятна маркировка объекта нулевой меткой.
Условная вероятность совпадения множества связей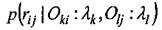
также зависит не только от двух вариантов маркировки объектов Oiи Oj, но и от некоторой функции Φr, изменяющей значения атрибутов rijв зависимости от имеющегося рассогласования между изображениями.
Аналогично (5.15) запишем

Рис.5.2. Функции плотности вероятности для атрибутов: (1) для ненулевой метки, (2) для нулевой метки.
В свою очередь условная вероятность для двух
для двух
ненулевых меток Akи A1может быть вычислена с помощью некоторой одномодальной функции плотности вероятности/*)^):

Если хотя бы одна из меток Ak, Aiявляется нулевой меткой, то условная вероятность выражается константой
выражается константой

Следует заметить, что представленные выше общие выражения (5.15) и (5.17) для вычисления условных вероятностей нарушают предположения о независимости множеств атрибутов и связей объектов из-за использования в этих выражениях функций Φflи Φr. Указанные функции вносят в выражения значительную корреляцию между атрибутами и связями объектов, т.к. они некоторым образом связаны с рассогласованием между изображениями. Это нарушает сделанные предположения об условной независимости, а игнорирование этого факта приводит к существенной потере подкрепляющей информации при выборе корректной гипотезы маркировки объекта.
Для минимизации указанной проблемы необходимо выбирать такие атрибуты и связи объектов, которые были бы инвариантны к рассогласованию между изображениями (т.е. оставались бы постоянными). При невозможности задания инвариантных атрибутов и связей следует стремиться задавать их такими, чтобы их зависимость от рассогласования между изображениями была минимальна.
При инвариантности атрибутов и связей объектов функции плотности Фа и Φrявляются дельта-функциями и выражения (5.15) и 253(5.17), соответственно, принимают вид:

Использование вероятностного метода для сопоставления ориентиров на базовом и на текущем изображениях
Для поиска корректного соответствия используем информацию о геометрической связности ориентиров на базовом изображении. Данная информация будет содержаться во множестве связей г. Значениями локальных атрибутов для характерных точек, в данном случае, будем пренебрегать. Таким образом, условные вероятности гипотез маркировки будут вычисляться в виде P(pki: λk| г).
В качестве связей ориентиров будем использовать относительные расстояния между ориентирами в базовом изображении, полученные для локального подмножества ориентиров, и нормированными наибольшим расстоянием между ориентирами. Все относительные расстояния, вычисленные для ориентира λiна базовом изображении, составлят множество связей Rz-.
Использование относительного расстояния для вычисления связей между ориентирами удовлетворяет условию, указанному в разделе 5.4.2, т. к. данная величина является инвариантной для преобразований сдвига, вращения и масштабирования. Инвариантность относительных расстояний нарушается для проективных преобразований, но при небольших проективных рассогла- сованияя между изображениями можно предположить что инвариантность относительных расстояний сохраняется. Кроме того, мы предлагаем минимизировать нарушения инвариантности связей за счет вычисления относительных расстояний только для локального подмножества ориентиров.
Для определения локальных подмножеств ориентиров предлагается построить на множестве ориентиров в базовом изображении триангуляцию Делоне[165,205,348]. Триангуляция Делоне на плоскости обладает рядом оптимальных свойств, а именно: (а) является единственной, т.е.
для заданного множества точек не существует другой триангуляции Делоне; (б) минимизирует длину ребер получаемых треугольников.В качестве локального подмножества отдельного ориентира в триангуляции выбираются только ориентиры, которые лежат с ним на общих ребрах треугольников. Благодаря свойству оптимальности триангуляции Делоне полученное подмножество ориентиров в действительности является подмножеством наиболее близко расположенных ориентиров в данной области базового изображения.
Таким образом, множество связей Rzдля метки λiвычисляется следующим порядком:
• C использованием построенной триангуляции Делоне для λiопределяется локальное подмножество соседних ориентиров - они лежат на смежных с λiребрах треугольников.
• Определяется смежное ребро с наибольшей длиной. Данная длина принимается за единицу.
• Длины ребер с меньшей длиной выражаются относительно длины наибольшего ребра.
Эксперименты на реальных изображениях показали, что при малых проективных искажениях вносимая ими погрешность в относительные расстояния локального подмножества точек имеет среднеквадратичное отклонение в пределах 0.02-0.06, что является довольно малой величиной. Следовательно, в первом приближении можно говорить об инвариантности относительных расстояний.
Вычисление условных вероятностей для гипотез сопоставления
Отказ от использования атрибутов и использование относительных расстояний в качестве связей между ориентирами приводит к необходимости изменения выражений для вычисления условных вероятностей для множества связей (5.12) и конечных выражений (5.13)-(5.14).
Выражение (5.12) должно измениться из-за того, что в условной части появляется не только второй ориентир, но и третий ориентир, расстояния до которого принято за единицу. Причем этот третий ориентир является постоянным для всех связей в локальном подмножестве ориентиров. Таким образом, для каждой связи rijдолжна быть получена условная вероятность

Согласно аксиоме о вероятности совмещения трех событий результи- рующе выражение будет иметь следующий вид

В (5.20) в скобках сначала вычисляется условная вероятность для каждой отдельной гипотезы маркировки, относительно которой вычисляются рас- 255
стояния, а затем вычисляется общая условная вероятность
Выражения (5.13)-(5.14) соответственно меняются на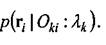
 и где
и где вычисляется с использованием (5.20).
вычисляется с использованием (5.20).
5.3.3. Численная реализация и экспериментальная проверка алгоритма
При реализации рассмотренного выше алгоритма основные вычислительные ресурсы расходуются на вычисление функций поддержки для каждой
для каждой
гипотезы сопоставления ориентиров-кандидатов. Самым затратным с вычислительной точки зрения является выражение (5.20), где имеется четырехуровневый вложенный цикл, на самом нижнем уровне которого вычисляются произведения априорных вероятностей гипотез маркировки и условных вероятностей
и условных вероятностей
для связей Вычислительные затраты еще более
Вычислительные затраты еще более
возрастают при нескольких итерациях релаксационного метода.
Вычислительными затратами на одну операцию умножения на нижнем уровне вложенных циклов можно пренебречь по сравнению с более затратной операцией вычисления условной вероятности для каждой связи. Таким образом, основную часть времени при реализации алгоритма займет вычисление
Условные вероятности для каждой связи являются постоянными величинами на последующих итерациях алгоритма, так как множество связей не изменяется. Это дает возможность для оптимизации алгоритма. Оптимизация заключается в том, что значения условных вероятностей вычисляются один раз на первой итерации и сохраняются в массивах для следующих итераций. Данные массивы имеют различную длину, равную размерности локального подмножества связей в триангуляции — в одном базовом ориентире может сходиться разное количество ребер треугольников.
Структура массива для хранения значений условных вероятностей связей наглядно продемонстрирована на рис. 5.3. Данный массив является трехмерным. Двухкоординатные срезы массива содержат условные вероятности для комбинаций ориентиров-кандидатов в соответствующем локальном подмно- 256
жестве для отдельного варианта маркировки кандидата, относительно кото
рого вычисляются локальные связи.

Рис. 5.3. Структура массива для хранения значений условных вероятностей.
Занимаемый массивом объем зависит от числа базовых ориентиров, числа ориентиров-кандидатов и числа ребер, примыкающих к базовому ориентиру в триангуляции. Так, если в среднем каждый базовый ориентир имеет 4 связи, то общий объем занимаемой массивами памяти при 20 базовых ориентирах и 5*20 = 100 ориентиров-кандидатов может достигать 0.61 Мбайт.
Размерность массивов с условными вероятностями связей может быть уменьшена в 8 раз за счет нормирования элементов массива по значению Dr(см. выражение (5.18)). При этом двумерные срезы массивов по каждому второму индексу каждой размерности, соответствующие вариантам маркировки нулевой меткой, будут иметь элементы, равные единице. Это позволяет не хранить данные элементы, а учитывать их напрямую при вычислении выражения (5.20).
Экспериментальная проверка алгоритма
Для проверки работоспособности алгоритма были проведены эксперименты по сопоставлению ориентиров на паре синтетических множеств характерных точек и нескольких парах реальных изображений панелей с электрическим оборудованием.
На рис. 5.4.показаны синтетические множества базовых ориентиров (рис. 5.4,а) и ориентиров-кандидатов (по пять кандидатов на каждый базовый ориентир) (рис. 5.4,6). Здесь также показана полученная для этого случая триангуляция Делоне. Аналогичная триангуляция построена на корректно сопоставленных ориентирах-кандидатах. Четыре из пяти ориентиров-кандидатов добавлены случайным образом, пятый - является корректным совпадением.
Гистограммы вероятностей гипотез маркировки ориентиров-кандидатов  для данного эксперимента показаны на рис. 5.5. Вероятности маркировки ориентиров-кандидатов нулевыми метками вычисляются как
для данного эксперимента показаны на рис. 5.5. Вероятности маркировки ориентиров-кандидатов нулевыми метками вычисляются как  . Действительная эталонная маркировка приведена на графике в пунктирной рамке вверху на рис. 5.5,а. Из нее видно, что первому базовому ориентиру соответствует второй кандидат из соответствующего подмножества O1, второму - первый кандидат из O2, и т.д. Перед началом реализации алгоритма вероятности для всех кандидатов были заданы значением 0.5 (рис. 5.5,6).
. Действительная эталонная маркировка приведена на графике в пунктирной рамке вверху на рис. 5.5,а. Из нее видно, что первому базовому ориентиру соответствует второй кандидат из соответствующего подмножества O1, второму - первый кандидат из O2, и т.д. Перед началом реализации алгоритма вероятности для всех кандидатов были заданы значением 0.5 (рис. 5.5,6).

Рис. 5.4. Синтетические множества характерных точек: множество базовых точек (а) и множество точек-кандидатов (б).
Вероятности гипотез маркировки стабилизировались на 11-й итерации
релаксационного метода. Вероятности гипотез маркировки для первой, пятой и одиннадцатой итераций приведены на трех нижних графиках (рис. 5.5,в-д). На первой итерации алгоритма (рис. 5.5,в) были отброшены только самые
маловероятные варианты сопоставления. Варианты, которые не были отбро
шены пока рассматриваются как равновероятные. К пятой итерации (рис. 5.5,г) наблюдается стабилизация вероятностей вариантов маркировки для трех из пяти базовых ориентиров - для них выбраны наиболее вероятные единственные кандидаты. В двух подмножествах кандидатов наиболее вероятными считаются пока еще по два варианта. Наконец, к одиннадцатой итерации (рис. 5.5,д) вероятности вариантов маркировки для всех подмножеств кандидатов окончательно стабилизировались. Итоговые вероятности гипотез
совпадают с корректным вариантом сопоставления.
В эксперименте в качестве функции Frв (5.19) была выбрана функция плотности нормального распределения с σ = 0.035. Значение вероятности для нулевого
варианта маркировки в (5.18) было выбрано как Dr= Fz. (2.8 σ) (см. рис. 5.2). Время вычисления на процессоре Pentium IV 2.4 GHz составило менее 0,1 секунды.

Рис. 5.5. Гистограммы вероятностей маркировки для точек-кандидатов при увеличении числа кандидатов
Была проведена серия экспериментов на реальных изображениях рабочих сред. Особую сложность для сопоставления ориентиров представляют сцены с большим количеством мелких и похожих деталей, т.к. в этом случае появляется большое количество ложных ориентиров. На рис. 5.6 представлены изображения одной такой сцены (боковой панели электрической сборки, в окрестности которой позиционируется MP), для которой была решена задача сопоставления ориентиров. На рис. 5.6,а представлено базовое изображение с 18 визуальными ориентирами. На рис. 5.6,6 изображена триангуляция Дело-
не, построенная на базовом множестве ориентиров (для построения триангуляции использовалась программа Triangle [358]). На рис. 5.6,в и 5.6,г показаны разные текущие изображения со смещением относительно базового с большим количеством ориентиров-кандидатов (по 5 на каждый базовый ориентир - 90 ориентиров-кандидатов в каждом изображении).

Рис. 5.6. Изображения реальной сцены с большим количеством ложных ориентиров: а- базовое изображение; б- триангуляция Делоне; в,г - текущие изображения со смещением относительно базового
Результаты использования предложенного вероятностного релаксационного метода сопоставления ориентиров приведены на гистограммах на рис. 5.7. Для изображения на рис. 5.6,в вероятности гипотез сопоставления стабилизировались на шестой итерации (рис 5.7,а). Все отобранные гипотезы являются корректными, за исключением ориентиров № 11 и № 15, для которых метод выбрал две равновероятные гипотезы (отмечены на гистограмме эллипсами), но только одна гипотеза в обоих случаях является корректной.
Для изображения на рис. 5.6,г вероятности гипотез сопоставления стабилизировались на пятой итерации (рис 5.7,6). Все отобранные гипотезы являются корректными, за исключением ориентира № 15. Для него метод отобрал три равновероятные гипотезы, ни одна из которых не является корректной.
Для ориентиров № 6 и № 16 ни один из кандидатов, автоматически отобранных для этих ориентиров, не являлся корректным и вероятностный метод выдал для них правильный результат, отбросив все гипотезы сопоставления. Однако следует заметить, что отсутствие корректных кандидатов во входных данных алгоритма может привести к ошибкам маркировки кандидатов для других точек, что и случилось в данном эксперименте. В этом случае алгоритм лишается важной «подкрепляющей» информации для выбора вариантов маркировки. Потеря информации наиболее значительна, если по некорректным входным данным вычисляются относительные расстояния. Время вычисления в обоих случаях составило менее 0,2 секунды.

Рис. 5.7. Гистограммы вероятностей маркировки ориентиров для реальной сцены: а-рис. 5.6,в; б-рис. 5.6,г.
На рис. 5.8 приведена еще одна пара изображений другой стенной панели с электрооборудованием. На базовом изображении (рис. 5.8,а) выделены 17 ориентиров. На текущем изображении (рис. 5.8,6) автоматически выделены множества ориентиров-кандидатов (по четыре кандидата на каждый базовый ориентир). На рис. 5.8,в приведены гистограммы вероятностей маркировки, полученные с использованием предлагаемого метода для данных множеств ориентиров. Вероятности маркировки стабилизировались после пятой итерации. Результаты данного эксперимента демонстрируют работу предлагаемого метода при подаче на его вход большого количества некорректных данных.
Некорректность входных данных заключается в том, что для шести из семнадцати базовых ориентиров все ориентиры-кандидаты являются некорректными, в основном, из-за перекрытия корректных ориентиров другими объектами на втором снимке. Это ориентиры с номерами 4-7, 12 и 13 на гистограмме. Алгоритм корректно обработал данную ситуацию - все кандидаты для указанных ориентиров были промаркированы нулевыми метками.
Однако отсутствие большого количества подкрепляющей информации оказало влияние на корректность маркировки кандидатов для других базовых ориентиров. Так для ориентира номер 1 все кандидаты были промаркированы нулевыми метками, хотя корректным является первый кандидат (отмечено крестом). Для базовых ориентиров номер 3, 9 и 17 алгоритм отобрал по два равновероятных кандидата, в то время как корректным является только один из них (отмечено эллипсами).

Рис. 5.8. Базовое изображение (а) с выделенными ориентирами, текущее изображение (б) со множеством ориентиров-кандидатов и гистограммы вероятностей маркировки (в), полученные с помощью предложенного метода. Эксперименты на других парах изображений показали, что при отсутствии корректных кандидатов для большего количества (в процентном соотношении) базовых ориентиров число ошибочных вариантов маркировки резко возрастает. Это объясняется тем, что подавляющее число гипотез не получают подтверждающей или опровергающей их информации во входных данных. В данном случае варианты маркировки распределяются алгоритмом случайным образом.
5.4.
Еще по теме Релаксационная методика решения задачи маркировки объекта:
- 3.4.2.Экспериментальная проверка методики решения обратной задачи кинематики на пространственном упругом манипуляторе
- Методика решения обратной задачи кинематики упругого манипулятора
- Тактические принципы и методика экспертиз при решении ситуационных задач.
- Численное и экспериментальное моделирование методики решения обратной задачи кинематики на пространственном упругом манипуляторе
- 42. проблемная ситуация и задача этапы решения задач способы решения задач.
- 4 Пространство - это понятие, которое описывает такое состояние объекта, которое включает в себя то, что интересует человека в рамках решения им своей задачи.
- Блок 2. Технология решения психологических задач Занятие 3 Технологии решения психологических задач.
- 9.1.3. Основная часть (методика и объект исследования)
- Тема 1. Предмет и задачи курса «Методика преподавания философии».
- Релаксационные методы
- Формирование и оценка альтернатив решений по объектам инвестиционной деятельности
- Решение двойственных задач
- Алгоритм решения задач
- 4.3 Методика определении компонент ковариационных матриц навигационных решений
- Теоретическое обоснование методики. Постановка задачи
- Решение вспомогательных задач.
- 7.3. Графическое решение задачи линейного программирования
- 4.4 Указания к решению задач РГКР № 2